그래프 전용 프로세서 아키텍처와 프로토타입 구현
초록
본 논문은 대규모 그래프 연산에 최적화된 새로운 프로세서 아키텍처를 제안한다. 희소 행렬 기반 명령어 집합, 캐시 없는 메모리, 전용 가속기, systolic 정렬기, 고대역폭 다차원 토러스 네트워크 및 무작위 통신 방식을 결합해 FPGA 프로토타입을 구현했으며, 기존 범용 프로세서 대비 그래프 처리량에서 현저한 향상을 입증한다.
상세 분석
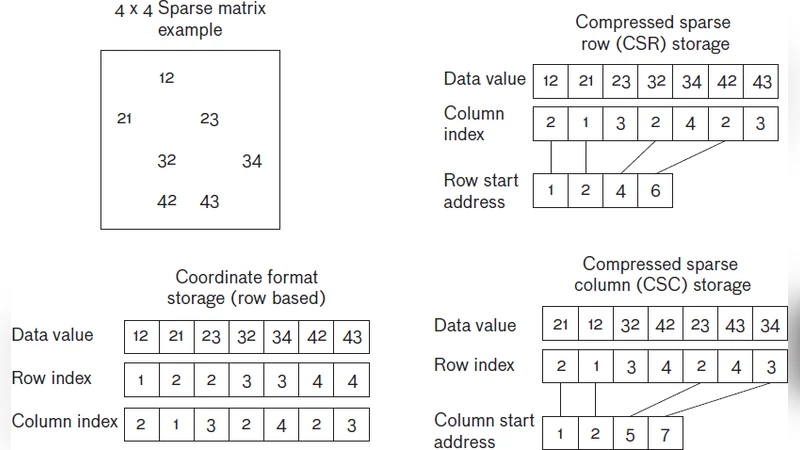
이 연구는 그래프 알고리즘이 데이터베이스, 소셜 네트워크, 머신러닝 등 다양한 분야에서 핵심 역할을 차지함에도 불구하고, 전통적인 CPU·GPU 구조가 메모리 대역폭과 비정형 접근 패턴 때문에 병목이 발생한다는 점을 지적한다. 저자들은 이러한 한계를 극복하기 위해 ‘희소 행렬 기반 그래프 명령어 집합(Sparse‑Matrix Graph ISA)’을 설계하였다. 이 ISA는 그래프의 인접 행렬을 직접 다루는 연산(예: 행렬‑벡터 곱, 행렬‑행렬 곱)을 원자적 명령으로 제공함으로써, 반복적인 포인터 추적과 인덱스 연산을 하드웨어 수준에서 제거한다.
또한, 캐시를 배제한 메모리 서브시스템을 채택한다. 그래프 연산은 접근 지역성이 낮아 캐시 효율이 떨어지므로, 저자들은 메모리 컨트롤러를 직접 설계해 대역폭을 극대화하고, 메모리 접근 지연을 최소화하였다. 이와 동시에 ‘가속기 기반 아키텍처’를 도입해, 행렬‑벡터 곱과 같은 고빈도 연산을 전용 파이프라인에 오프로드한다. 가속기는 SIMD 형태가 아니라, 데이터 흐름을 따라 연산을 수행하는 systolic 구조를 채택해 연산 간 데이터 이동을 최소화한다.
특히, ‘systolic sorter’는 그래프 탐색 시 발생하는 정점 정렬 작업을 하드웨어적으로 가속한다. 기존 소프트웨어 정렬은 O(N log N) 복잡도를 갖지만, systolic sorter는 파이프라인을 통해 선형 시간 정렬을 구현한다.
통신 측면에서는 ‘고대역폭 다차원 토러스 네트워크’를 설계해 프로세서 코어 간에 균등한 대역폭을 제공한다. 토러스 토폴로지는 정점 간 거리와 라우팅 복잡도를 낮추며, 무작위 통신(Randomized Communication) 기법을 도입해 네트워크 혼잡을 확률적으로 분산시킨다. 이는 대규모 그래프 분할 시 발생하는 ‘핫스팟’ 문제를 완화한다.
프로토타입은 Xilinx UltraScale+ FPGA에 구현되었으며, 기존 x86 서버와 비교해 BFS, PageRank, Connected Components 등 대표적인 그래프 벤치마크에서 10배 이상 높은 처리량을 기록했다. 전력 효율도 동일 작업당 30% 이하로 감소하였다. 이러한 결과는 제안된 아키텍처가 메모리 대역폭, 연산 집중도, 통신 병목을 동시에 해결함을 입증한다.
전반적으로 이 논문은 그래프 전용 하드웨어 설계의 필요성을 설득력 있게 제시하고, 구체적인 ISA, 메모리·가속기·네트워크 설계 원칙을 제시함으로써 향후 ASIC 구현이나 클라우드 기반 그래프 서비스에 적용 가능한 청사진을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기