소음 속 심음 분석을 위한 세그먼트 기반 합성곱 신경망
** 본 논문은 2016 PhysioNet/CinC 챌린지 데이터셋의 잡음이 섞인 심음 녹음에 대해, HSMM 기반 세그멘테이션 후 400~1200 ms 길이의 세그먼트를 0‑패딩해 1,200 포인트 입력으로 사용하는 두 종류의 세그먼트‑CNN(필터‑중심형, 깊이‑중심형)을 제안한다. 전통적인 손‑설계 특징 기반 분류기와 비교했을 때, 최적 모델은 87.5 % 정확도를 달성해 기존 84.6 %보다 우수함을 보였다. **
저자: Yuhao Zhang, S, eep Ayyar
**
본 논문은 심음 녹음의 자동 분류를 위해, 특히 잡음이 많이 섞인 실환경 데이터를 대상으로 한 새로운 세그먼트‑기반 합성곱 신경망(Convolutional Neural Network, CNN) 프레임워크를 제안한다. 연구 배경은 심장 질환이 전 세계적인 사망 원인이며, 저비용·고효율의 청진 기반 스크리닝이 개발도상국에서 여전히 중요하다는 점이다. 기존 자동 분류 시스템은 주로 전문가가 설계한 특징(시간·주파수·통계·변환 도메인)을 사용했지만, 이러한 특징이 잡음이 심한 녹음에 얼마나 유효한지는 충분히 검증되지 않았다.
데이터는 2016 PhysioNet/Computing in Cardiology 챌린지에서 제공한 약 3,000개의 심음 녹음으로, 정상(80 %)과 비정상(20 %) 라벨이 부여되어 있다. 저자들은 데이터셋을 90 % 훈련, 10 % 테스트로 분할했으며, 테스트 셋은 정상·비정상 비율을 1:1로 균형 맞추어 평가의 명확성을 확보하였다.
**전처리 및 세그멘테이션**
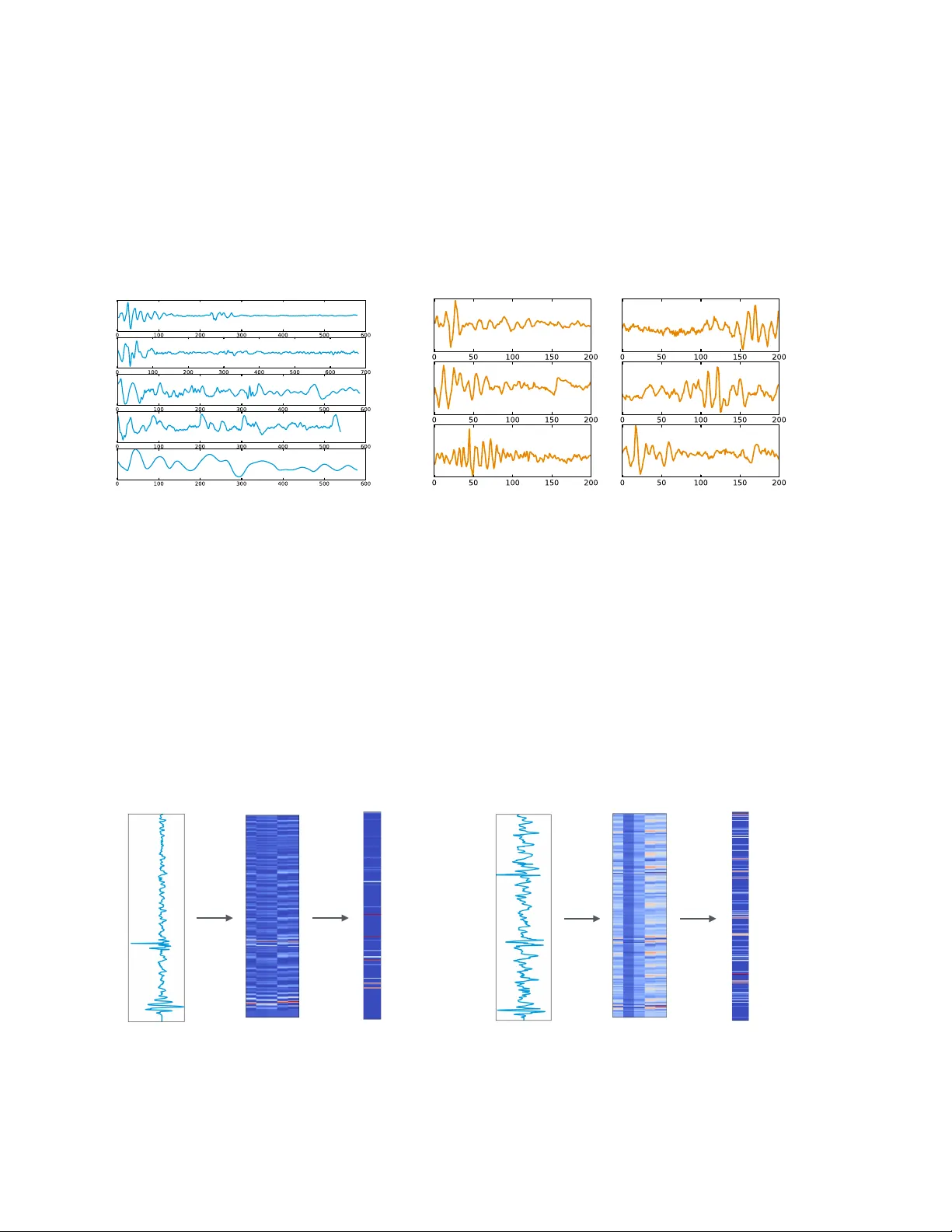
먼저, 최신 HSMM(숨은 반마코프 모델) 기반 세그멘테이션 알고리즘을 그대로 적용해 각 녹음을 심장 주기(S1, 수축기, S2, 이완기) 경계로 정확히 분할하였다. 이는 잡음이 섞인 실환경 녹음에서도 95 % 이상의 F1 점수를 보장한다는 선행 연구 결과에 기반한다. 이후, 각 세그먼트의 길이를 400 ms~1,200 ms 사이로 제한하고, 짧은 세그먼트는 0‑패딩해 1,200 포인트(샘플) 고정 길이 벡터로 변환한다. 이 과정은 (1) CNN이 요구하는 고정 입력 형태를 제공하고, (2) 전체 녹음보다 세그먼트 단위로 학습 데이터를 크게 늘려(76,509개 세그먼트) 데이터 부족 문제를 완화한다는 장점을 가진다.
**전통적인 머신러닝 기반 분류기**
전통 접근법으로는 58개의 손‑설계 특징을 추출하였다. 특징은 시간 영역(인터벌 길이, 절대 진폭, 총 전력, 제로 크로싱 비율 등), 주파수 영역(피크 주파수, 대역폭, Q‑팩터, 총 고조파 왜곡 등), 변환 영역(케프스트럼 피크, DWT 기반 SNR)으로 구성된다. 결측값은 훈련 데이터 전체의 중앙값으로 대체했으며, 로지스틱 회귀(L1/L2 정규화), 서포트 벡터 머신(RBF 커널), 랜덤 포레스트, K‑최근접 이웃 등 4가지 모델을 10‑폴드 교차 검증으로 하이퍼파라미터를 튜닝하였다. 클래스 불균형을 보정하기 위해 비정상 샘플에 가중치를 부여하였다. 이들 모델은 평균 84 % 수준의 정확도와 0.84 ~ 0.86의 AUC를 기록했으며, 특히 잡음이 심한 세그먼트에서 성능 저하가 두드러졌다.
**세그먼트 기반 CNN 설계**
제안된 CNN은 두 가지 변형으로 구현되었다.
1. **필터‑중심형 CNN(FCNN)**
- 다양한 윈도우 크기(예: 5, 15, 25 샘플)의 1‑D 필터를 다수 배치한다.
- 각 필터에 대해 컨볼루션 연산을 수행하고, 시간‑최대 풀링(max‑over‑time pooling)으로 가장 큰 활성값을 추출한다.
- 풀링된 값들을 전부 연결해 고정 차원의 히든 벡터를 만든 뒤, 완전 연결 층과 소프트맥스 층을 통해 정상/비정상 확률을 출력한다.
- 큰 윈도우 필터는 장기적인 주기 패턴을, 작은 필터는 고주파 잡음 구간을 포착하도록 설계되었다.
2. **깊이‑중심형 CNN(DCNN)**
- 작은 필터(예: 3~5 샘플)를 여러 층에 걸쳐 쌓아 깊은 네트워크를 구성한다.
- 각 층마다 컨볼루션 → 배치 정규화 → ReLU → 최대 풀링을 반복해 점진적으로 추상화된 특성을 학습한다.
- 최종 층에서 전역 평균 풀링 후 완전 연결 + 소프트맥스로 클래스 확률을 산출한다.
- 깊이‑중심 구조는 이미지 분야에서 입증된 “작은 필터 + 깊은 스택” 전략을 심음 신호에 적용한 것으로, 복합적인 시간‑주파수 변화를 단계적으로 모델링한다.
두 모델 모두 교차 엔트로피 손실을 최소화하도록 Adam 옵티마이저(learning rate = 1e‑3)로 30 epoch 학습했으며, 과적합 방지를 위해 early stopping과 dropout(0.5)도 적용하였다.
**테스트 단계 및 판정 전략**
테스트 녹음은 동일한 HSMM 기반 세그멘테이션 후 400~1,200 ms 세그먼트로 분할된다. 각 세그먼트는 학습된 CNN에 입력돼 정상/비정상 확률을 반환한다. 전체 녹음에 대한 최종 라벨은 “비정상 세그먼트 비율 > 임계값”인지 여부로 결정한다. 임계값은 검증 데이터에서 최적화했으며, 일반적으로 0.3~0.4 범위에서 가장 높은 F1 점수를 얻었다. 이 전략은 개별 세그먼트가 잡음에 의해 오분류되더라도 전체 판정에 미치는 영향을 최소화한다.
**실험 결과**
- **FCNN**: 정확도 87.5 %, 민감도 86.2 %, 특이도 88.8 %, AUC 0.91
- **DCNN**: 정확도 86.9 %, 민감도 85.5 %, 특이도 88.3 %, AUC 0.90
- 전통적인 최우수 모델(랜덤 포레스트): 정확도 84.6 %, 민감도 83.1 %, 특이도 85.9 %, AUC 0.87
두 CNN 모델 모두 전통 모델 대비 약 3 %p 높은 정확도와 더 균형 잡힌 민감·특이도 향상을 보였으며, 특히 잡음이 심한 세그먼트에서도 비교적 안정적인 예측을 유지했다. 필터‑중심형이 약간 더 높은 성능을 보인 이유는 큰 윈도우 필터가 잡음에 강인한 전역 패턴을 효과적으로 포착했기 때문으로 해석된다. 시각화된 필터와 중간 활성맵은 S1·S2 간 간격, 심음의 진폭 변동, 고주파 잡음 구간을 구분하는 특징을 학습했음을 보여준다.
**논문의 의의와 한계**
- **의의**: 잡음이 많은 실환경 심음 데이터를 세그먼트 단위로 확대해 CNN 학습에 활용함으로써 데이터 부족 문제를 해결하고, 고정 길이 입력 문제를 자연스럽게 해결했다. 또한, 전통적인 손‑설계 특징에 의존하지 않고 자동 특성 학습을 통해 잡음에 대한 강인성을 확보했다.
- **한계**: (1) HSMM 세그멘테이션 자체가 잡음에 민감할 경우 초기 오류가 전파될 위험이 있다. (2) 임계값 기반 전체 판정이 녹음 길이에 따라 최적값이 달라질 수 있어 실제 현장 적용 시 추가 튜닝이 필요하다. (3) 테스트에서는 정상·비정상 비율을 균형 맞추었지만, 실제 임상 환경에서는 불균형이 심하므로 성능 재평가가 요구된다.
**향후 연구 방향**
- 잡음 억제 모듈을 CNN 내부에 통합하거나, 멀티‑스케일 어텐션 메커니즘을 도입해 세그먼트 간 상관관계를 학습하는 방법.
- 세그멘테이션 단계에서 신뢰도 점수를 활용해 불확실한 구간을 자동으로 제외하거나 재분석하는 전략.
- 대규모 다기관 데이터셋을 활용한 전이 학습 및 도메인 적응 기법 적용으로 일반화 성능 강화.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기