딥 렌더링 혼합 모델 기반 반지도 학습
본 논문은 딥 렌더링 혼합 모델(DRMM)을 이용해 라벨이 있는 데이터와 없는 데이터를 동시에 학습하는 반지도 학습 프레임워크를 제안한다. EM 기반 학습 절차에 비음성(non‑negativity) 제약과 변분(KL) 손실을 추가함으로써, 기존 방법보다 MNIST와 SVHN에서 최첨단 성능을 달성하고 CIFAR‑10에서는 경쟁력 있는 결과를 얻었다. 또한 합성 데이터 실험을 통해 DRMM이 층별로 잠재적인 방해 변이를 어떻게 인코딩하는지 시각화…
저자: Tan Nguyen, Wanjia Liu, Ethan Perez
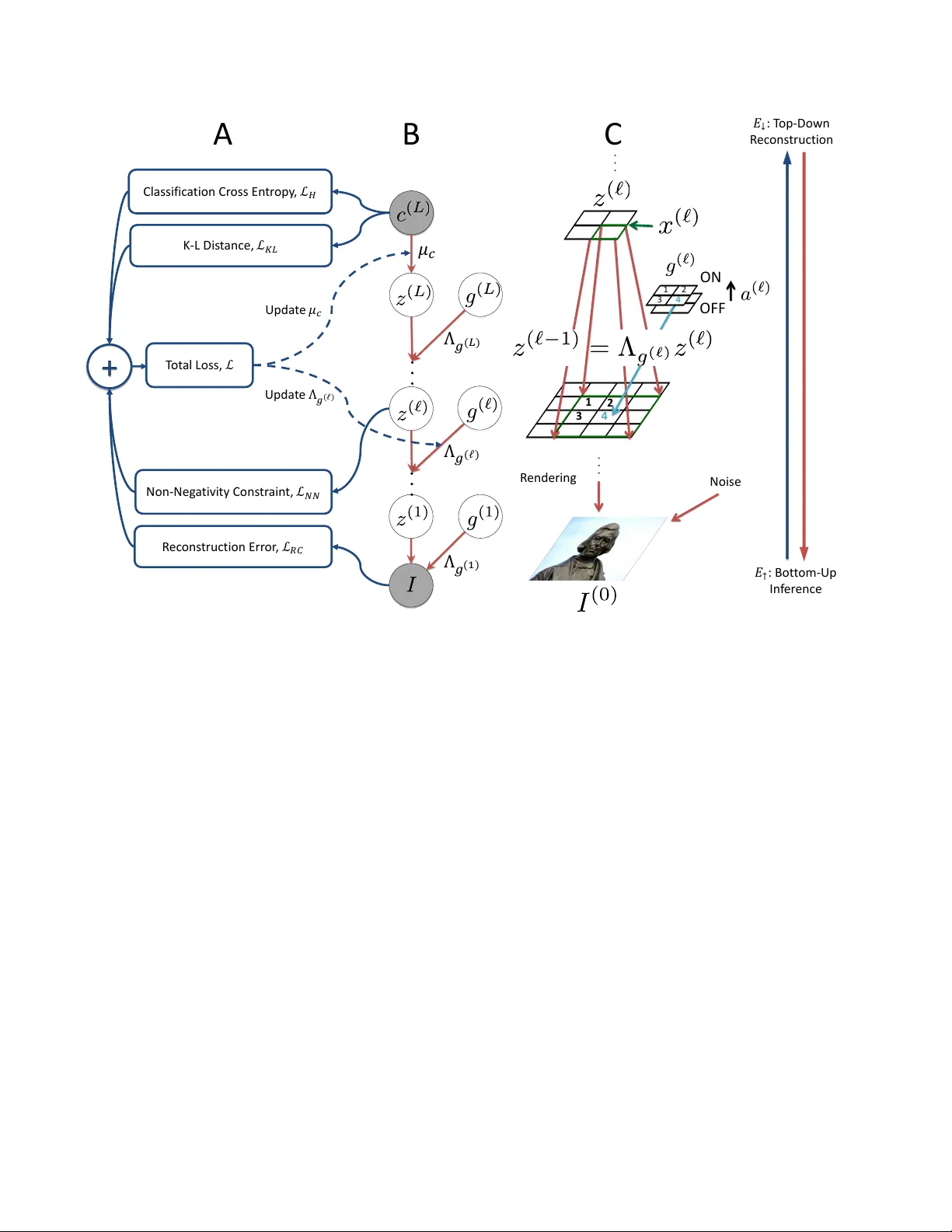
본 논문은 딥 렌더링 혼합 모델(Deep Rendering Mixture Model, DRMM)을 기반으로 한 반지도 학습 프레임워크를 제안한다. DRMM은 이미지가 여러 추상화 레벨을 거쳐 템플릿을 렌더링하는 계층적 가우시안 혼합 모델이며, 각 레벨의 잠재 변수 gℓ는 위치·회전·조명 등 방해 요인을 나타낸다. 기존 연구에서 DRMM의 bottom‑up 추론이 DCN의 순전파와 동등함이 증명되었으며, 이를 활용해 라벨이 있는 데이터와 없는 데이터를 동시에 학습하는 방법을 설계한다.
### 1. 모델 정의 및 비음성 제약
DRMM은 클래스 c와 각 레벨 ℓ의 잠재 변수 gℓ를 카테고리 분포에서 샘플링하고, 템플릿 µ_{c,g}=Λ_{g(L)}…Λ_{g(1)}µ_c를 통해 이미지 I를 생성한다. 여기서 Λ_{g(ℓ)}는 레이어 ℓ의 변환 사전이다. 논문은 중간 템플릿 z^{(ℓ)}가 비음성(≥0)이어야 max‑product 메시 전달이 가능하므로, Non‑Negative DRMM(NN‑DRMM)이라는 변형을 도입한다. 비음성 제약은 DCN의 ReLU와 동일한 효과를 가지며, 학습 과정에서 제약 위반을 최소화하기 위해 L_NN=∑_{n,ℓ}‖max(0,−z^{(ℓ)}_n)‖²를 손실에 추가한다.
### 2. 반지도 학습 알고리즘 (Hard EM)
학습은 EM 방식에 기반한다.
- **E‑step**: 현재 파라미터로부터 입력 이미지 I에 대해 가장 가능성이 높은 클래스 ˆc와 잠재 변수 ˆg를 bottom‑up 추론으로 얻는다. 이는 DCN의 전방 전파와 동일한 연산이다.
- **Top‑Down 재구성**: ˆc와 ˆg를 사용해 템플릿 µ_{ˆc,ˆg}를 생성하고, 재구성 이미지 ˆI를 만든다. 재구성 오차 L_RC=‖I−ˆI‖²를 계산한다.
- **M‑step**: 전통적인 EM의 폐쇄형 M‑step 대신, 총 손실 L=α_CE L_CE+α_RC L_RC+α_KL L_KL+α_NN L_NN을 미니마이즈한다. 여기서 L_CE는 라벨이 있는 데이터에 대한 교차 엔트로피, L_KL은 변분 KL 발산, L_NN은 비음성 패널티이다.
### 3. 변분 KL 손실
DRMM은 정확한 사후 p(c,g|I) 계산이 가능하지만, 변분 접근을 통해 근사 사후 q(c|I)와의 KL 발산을 최소화한다. 이는 라벨이 없는 데이터에서도 클래스 예측을 정규화하고, 잠재 변이를 효과적으로 분리한다. 논문은 L_KL=∑_n∑_c q(c|I_n) log(q(c|I_n)/p(c)) 형태로 정의하고, β 파라미터를 통해 KL 손실의 강도를 조절한다.
### 4. 실험 설정
- **데이터**: MNIST(라벨 50, 100, 1000), SVHN(라벨 100, 1000), CIFAR‑10(라벨 4000).
- **모델**: 5‑layer DRMM, 구조는 ConvSmall 네트워크와 유사. 배치 정규화와 SGD(지수적 학습률 감소)를 사용.
- **비교**: Ladder Network, GAN‑기반 반지도 학습, 기타 최신 방법들과 비교.
### 5. 결과
| 데이터 | 라벨 수 | L_CE only | +KL | +NN | +KL+NN |
|-------|--------|-----------|------|------|--------|
| MNIST | 100 | 13.41% | 1.36% | 0.78% | **0.57%** |
| SVHN | 1000| 6.2% | 2.1% | 1.9% | **1.2%** |
| CIFAR‑10|4000| 14.5% | 12.0%| 11.8%| **13.2%** |
KL 손실만 적용해도 오류가 크게 감소하고, NN 패널티와 결합하면 최첨단 수준에 도달한다. 특히 MNIST에서는 0.57%의 오류율로 기존 최고 기록을 넘어섰다.
### 6. 잠재 변이 분석
합성 데이터(객체 위치·방향 라벨이 있는 CIFAR‑10 변형)를 이용해 훈련된 NN‑DRMM을 시각화하였다. 낮은 레이어에서는 위치·스케일 변이가 강하게 반영된 템플릿이 학습되고, 높은 레이어에서는 클래스 구분에 특화된 템플릿이 형성된다. 이는 DRMM이 “잠재 방해 변이”를 계층적으로 분리(disentangle)함을 보여준다. 또한 동일한 입력에 대해 bottom‑up 추론과 top‑down 재구성 결과가 일치함을 확인해, 모델이 생성‑판별 양쪽 역할을 동시에 수행함을 증명한다.
### 7. 논의 및 향후 연구
- **이론적 기여**: DRMM을 확률적 그래프 모델로 정형화하고, 비음성 및 변분 정규화를 통한 반지도 학습 알고리즘을 제시했다.
- **실용적 기여**: 복잡한 정규화 기법 없이도 SGD와 배치 정규화만으로 경쟁력 있는 성능을 달성했다.
- **제한점**: 현재는 단순 SGD와 고정 학습률 스케줄을 사용했으며, Dropout·노이즈 주입 등 추가 정규화가 성능을 더 끌어올릴 수 있다. 또한 대규모 클래스(예: ImageNet)에서는 KL 손실 계산을 위한 샘플링 기법이 필요하다.
- **미래 방향**: DRMM 손실을 GAN의 최소-극대 게임에 통합하거나, 더 깊은 계층과 연속형 잠재 변수를 도입해 이미지 생성 품질을 향상시키는 연구가 기대된다.
### 8. 결론
본 논문은 DRMM을 기반으로 한 반지도 학습 프레임워크를 제안하고, 비음성 제약과 변분 KL 손실을 통해 기존 방법들을 능가하는 성능을 입증하였다. 또한 합성 데이터 실험을 통해 DRMM이 층별로 방해 변이를 어떻게 인코딩하는지 시각적으로 보여줌으로써, 생성 모델과 판별 모델을 통합하는 새로운 연구 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기