노이즈에 강한 음성 인식을 위한 불변 표현 학습
본 논문은 음성 인식 시스템이 환경·스피커·채널 등 다양한 변동에 강건하도록, 잡음 조건에 불변인 중간 표현을 학습하는 방법을 제안한다. GAN과 도메인 적응에서 영감을 얻은 적대적 훈련(gradient‑reverse) 기법을 적용해, 인코더가 잡음 도메인 분류기를 혼란스럽게 만들면서 동시에 음소(class) 예측 성능을 유지하도록 설계하였다. Aurora‑4 데이터셋에서 다중 조건 학습 대비, 특히 훈련에 포함되지 않은 잡음 유형에 대해 월드…
저자: Dmitriy Serdyuk, Kartik Audhkhasi, Philemon Brakel
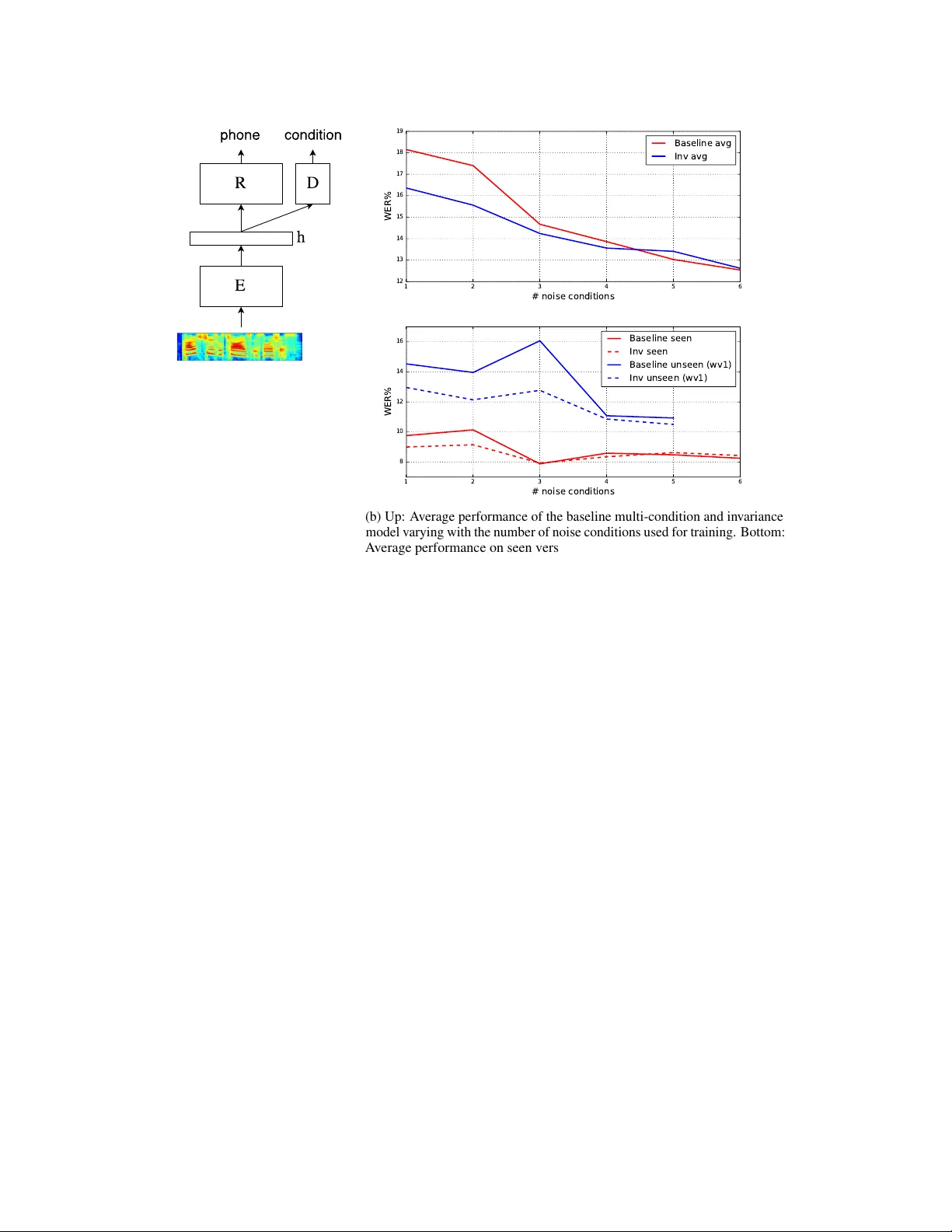
본 논문은 현대 ASR 시스템이 환경·스피커·채널·녹음 조건 등 다양한 변동성에 취약한 문제를 해결하고자, 신경망이 잡음 조건에 불변한 특징 표현을 학습하도록 하는 새로운 접근법을 제시한다. 기존의 적응 기법(MLLR, i‑vector, VTS 등)은 주로 모델 파라미터를 별도로 조정하거나 특수한 전처리를 필요로 했지만, 본 연구는 딥러닝 모델 자체에 잡음 불변성을 내재화한다. 이를 위해 GAN과 도메인 적응에서 영감을 얻은 적대적 훈련 방식을 차용한다. 구체적으로, 입력 음성의 40‑dim Mel‑filterbank + delta/delta‑delta 특성을 1320 차원으로 스팬하고, 6‑layer DNN(각 층 2048 ReLU)으로 구성된 인코더 E를 만든다. E의 중간 출력 h는 두 개의 분기망에 전달되는데, 하나는 전통적인 음소(HMM state) 분류기 R이며, 다른 하나는 잡음/청음 이진 도메인 판별기 D이다. 학습 손실은 세 부분으로 구성된다. L₁은 음소 라벨에 대한 교차 엔트로피, L₂는 도메인 라벨에 대한 교차 엔트로피, L₃는 D의 예측을 역전시켜 E가 D를 혼란스럽게 만들도록 하는 손실이다. L₃는 ‘d·log(1‑ĥd)+(1‑d)·log(ĥd)’ 형태로 정의해, D가 올바른 도메인 라벨을 맞추지 못하도록 유도한다. 전체 손실은 L₁+α·L₂−β·L₃이며, 실험에서는 α를 1로 고정하고 β 하나만 조정하였다. 훈련 시 잡음 라벨은 필요하지만, 테스트 단계에서는 D를 완전히 배제하고 R만 사용하므로 추가 연산 비용이 없다.
실험은 Aurora‑4 데이터셋을 사용했다. 이 데이터는 WSJ0 기반으로 6가지 잡음(airport, babble, car, restaurant, street, train)과 두 종류의 마이크(깨끗한 마이크와 Sennheiser)로 구성된다. 훈련 데이터는 청음 4400 utterance와 각 잡음당 446 utterance를 포함한다. 저자는 잡음 종류를 하나씩 추가하면서 6가지 훈련 시나리오를 만들었으며, 각 시나리오마다 다중 조건 학습(baseline)과 제안한 불변 학습 모델을 비교했다. 결과는 표 1과 그림 1b에 제시된다. 잡음 종류가 적을수록(예: 1~3가지) 불변 모델이 baseline보다 평균 2~4%p 낮은 WER를 기록했으며, 특히 훈련에 포함되지 않은 새로운 잡음이나 마이크에 대해 큰 일반화 이점을 보였다. 모든 잡음(6가지)을 모두 사용한 경우에도 불변 모델이 약간의 추가 개선을 보였지만, 차이는 크지 않았다. 또한 사전 학습(pre‑training)된 모델에 불변 학습을 적용한 실험(표 1 마지막 행)에서도 동일한 경향이 확인되었다.
논의에서는 음성 인식 분야에서 도메인 적응 네트워크가 이미지 분야에 비해 과소적합되는 경향이 있음을 지적한다. 이는 L₃의 그래디언트가 불안정하고 잡음 라벨이 이진으로 제한된 점이 원인일 수 있다. 향후 연구 방향으로는 도메인 판별기의 구조를 심화시키거나, 다중 도메인(스피커, 채널, 방위 등) 라벨을 동시에 활용하는 멀티‑태스크 적대 학습, 그리고 보다 정교한 불변 촉진 손실 함수를 설계하는 것을 제안한다. 최종적으로, 이 접근법은 제한된 잡음 라벨만으로도 실제 서비스 환경에서 발생할 수 있는 다양한 잡음에 대해 강인한 ASR 시스템을 구축하는 데 유용한 길을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기