상황 인식의 의미 희소성 해결: 텐서 합성 및 웹 기반 데이터 증강
초록
이미지 상황 인식에서 동사‑역할‑명사 조합이 대부분 드물게 나타나는 ‘의미 희소성’ 문제를 지적하고, 명사와 역할을 공유하도록 설계한 텐서 기반 합성 CRF와 웹 검색을 통한 자동 데이터 증강 기법을 제안한다. 이 두 기술을 결합하면 기존 모델 대비 동사 Top‑5 정확도가 2.11%, 명사‑역할 Top‑5 정확도가 4.40% 향상되고, 5백만 장의 웹 이미지 추가 시 각각 6.23%와 9.57%의 추가 개선을 달성한다.
상세 분석
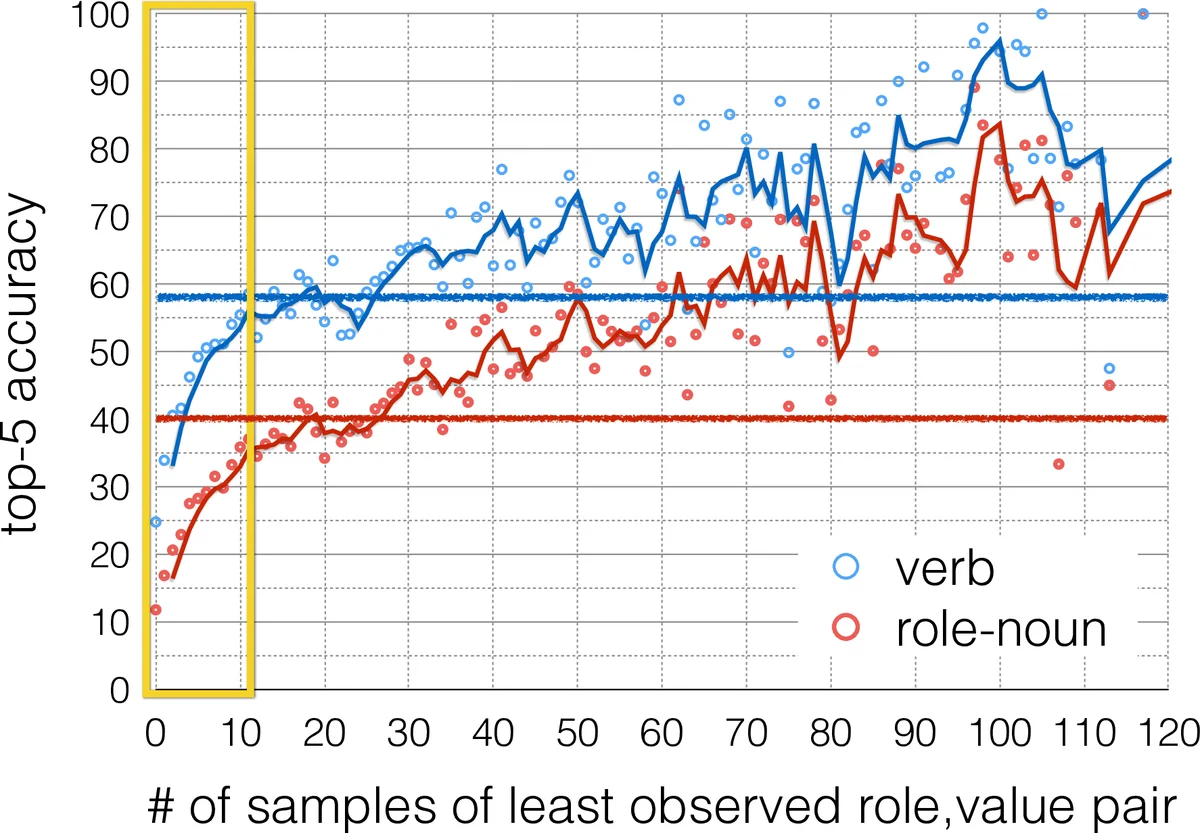
본 논문은 상황 인식(situation recognition)이라는 구조화된 시각 분류 문제에서 ‘의미 희소성’이라는 근본적인 한계를 체계적으로 분석한다. imSitu 데이터셋을 기준으로 전체 예측 중 35%가 훈련에 10번 이하로 등장하는 드문 역할‑명사 쌍으로 구성된다는 사실을 실험적으로 밝혀냈으며, 이러한 희소성은 최소 하나의 역할‑명사 쌍이라도 드물면 전체 동사·역할‑명사 예측 정확도가 급격히 떨어지는 현상을 초래한다(그림 3).
이를 해결하기 위해 두 가지 핵심 접근법을 제시한다. 첫 번째는 명사와 역할 사이의 파라미터 공유를 명시적으로 구현하는 텐서 합성 함수이다. 기존 CRF는 각 (동사, 역할, 명사) 조합마다 고유의 선형 회귀 파라미터 θ_{v,e,n}을 학습했지만, 이는 데이터가 충분히 존재하지 않을 경우 과적합을 유발한다. 논문은 명사 임베딩 d_n∈ℝ^m, 역할‑동사 매트릭스 H(v,e)∈ℝ^{p×o}, 그리고 전역 이미지 피처 g_i∈ℝ^p를 도입하고, 이들을 외적(⊗)하여 3차원 텐서 C∈ℝ^{m×o×p}와 결합한다. 최종 스코어 φ_e(v,e,n,i)=∑_{x,y,z} T(v,e,n,g_i)
댓글 및 학술 토론
Loading comments...
의견 남기기