하이브리드 학습 시스템 DKFIS: SVM·ANFIS·전문지식 융합으로 석유 포화도 예측 혁신
본 논문은 SVM 기반 1단계 분류와 ANFIS 기반 2단계 회귀를 결합하고, 도메인 전문가 규칙을 퍼지 시스템에 삽입한 DKFIS 프레임워크를 제안한다. 인도 서부 유전의 4개 웰 로그(감마선, 저항율, 밀도, 점토량)를 이용해 석유 포화도를 예측했으며, 제로값이 93%에 달하는 불균형·노이즈 데이터에서도 정확도가 크게 향상되었다. 성능 평가는 CC, RMSE, AEM, SI 네 가지 지표로 수행되었다.
저자: Soumi Chaki, Aurobinda Routray, William K. Mohanty
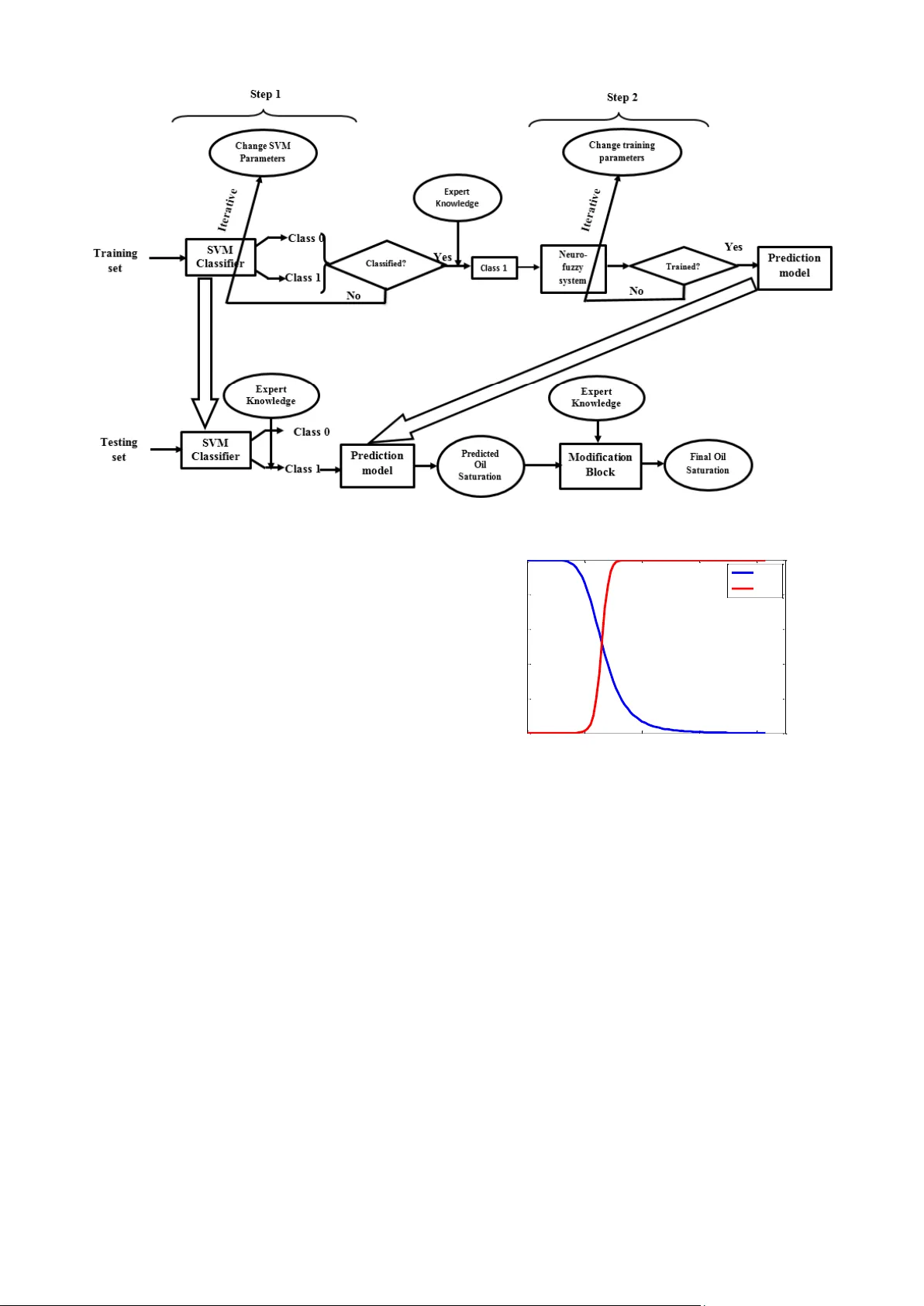
본 논문은 석유 포화도 예측이라는 실제 산업 문제를 해결하기 위해, 데이터‑기반 학습 알고리즘과 도메인 전문가 지식을 결합한 새로운 프레임워크인 DKFIS(Domain Knowledge based Fuzzy Information System)를 제안한다. 연구 배경으로는 기존의 ANN, ANFIS, 퍼지 로직, 유전 알고리즘 등 다양한 소프트웨어 기반 방법들이 존재하지만, 데이터가 희소하고 불균형하며 잡음이 많은 경우 모델이 불안정하거나 물리적으로 비현실적인 결과를 도출한다는 점을 지적한다. 특히, 인도 서부 유전에서 수집한 4개 웰(A, B, C, D)의 로그 데이터는 감마선, 저항율, 밀도, 점토량 네 가지 입력 변수와 석유 포화도라는 목표 변수를 포함한다. 포화도 값은 0‑0.86 범위에 분포하지만, 전체 데이터 중 93.55%가 정확히 0인 제로 포화도로, 매우 편향된 분포를 보인다.
이에 저자는 두 단계의 하이브리드 모델을 설계한다. 1단계는 SVM을 이용한 이진 분류로, 입력 벡터를 “제로 포화”(Class 0)와 “비제로 포화”(Class 1)로 구분한다. SVM은 SMO 알고리즘으로 학습되며, 입력 변수는 Z‑score 정규화한다. 분류 결과는 전문가가 정의한 도메인 규칙(R1‑R3)과 연계된 퍼지 인포메이션 시스템(FIS)으로 후처리된다. 규칙은 감마선, 저항율, 밀도, 점토량의 조합에 따라 포화도가 낮거나 높다는 질적 판단을 제공한다. 예를 들어, 감마선이 높고 저항율이 낮으며 밀도와 점토량이 높을 경우 포화도가 낮다고 판단한다. 이러한 규칙 기반 필터링은 SVM이 소수의 비제로 샘플을 오분류했을 때 이를 Class 0으로 재조정함으로써, 이후 단계에 오류가 전파되는 것을 방지한다.
2단계에서는 Class 1으로 판정된 샘플에 대해 ANFIS를 적용한다. ANFIS는 퍼지 전방 추론과 역전파 기반 파라미터 학습을 결합한 모델로, 입력 변수는 동일하게 정규화된 상태이며, 멤버십 함수는 일반화된 벨형(g‑bell) 함수를 사용한다. 학습 과정에서는 최소제곱법과 경사하강법을 혼합한 하이브리드 알고리즘이 적용된다. ANFIS가 출력한 포화도는 0‑1 구간으로 정규화된 뒤, 두 개의 퍼지 집합(NZS: Non‑Zero Small, NZB: Non‑Zero Big)으로 다시 퍼지화된다. 이후 도메인 규칙에 따라 멤버십 등급이 조정되고, 디퍼지화를 통해 최종 연속값이 도출된다.
실험 설계는 각 웰에서 70% 데이터를 학습용, 30% 데이터를 테스트용으로 사용했으며, 전체 데이터는 4개의 웰을 합쳐 구성하였다. 성능 평가는 상관계수(CC), 평균 제곱근 오차(RMSE), 평균 절대 오차(AEM), 산점도 지수(SI) 네 가지 지표로 수행되었다. 결과는 순수 ANFIS 모델에 비해 DKFIS가 CC에서 약 0.05~0.08 상승하고, RMSE와 AEM이 각각 10%~15% 감소했음을 보여준다. 특히, 전문가 규칙이 적용된 후의 예측값은 물리적으로 의미 있는 범위(0‑0.86) 내에 머물렀으며, 제로 포화도가 높은 데이터에서도 과도한 오버샘플링이나 비현실적인 값이 발생하지 않았다.
논문의 주요 기여는 다음과 같다. 첫째, 불균형·노이즈 데이터에 적합한 2단계 모델 구조를 제시함으로써, 분류와 회귀를 효과적으로 분리하였다. 둘째, 도메인 전문가의 질적 지식을 퍼지 규칙으로 체계화하여, 데이터‑기반 모델의 오류를 보정하고 결과의 신뢰성을 높였다. 셋째, 정량적 성능 지표와 정성적 전문가 판단을 동시에 만족시키는 프레임워크를 구현함으로써, 실제 현장 적용 가능성을 입증하였다.
하지만 몇 가지 한계점도 존재한다. SVM의 커널 선택과 비용 민감도 파라미터에 대한 상세한 튜닝 과정이 논문에 기술되지 않아 재현성이 다소 떨어진다. 또한, ANFIS의 멤버십 함수 초기값 및 규칙 수에 대한 최적화 전략이 명시되지 않아, 다른 데이터셋에 적용할 때 성능 변동이 클 수 있다. 마지막으로, 기존의 딥러닝 기반 회귀 모델(예: CNN, LSTM)과의 비교 실험이 부족하여, 제안 방법이 최신 기법 대비 어느 정도의 경쟁력을 갖는지 명확히 판단하기 어렵다. 향후 연구에서는 이러한 파라미터 최적화와 다양한 베이스라인 모델과의 비교를 통해 DKFIS의 일반화 능력을 검증하고, 도메인 규칙 자동 추출 방법을 모색함으로써 전문가 의존도를 낮추는 방향으로 확장할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기