대규모 샘플링 기반 중복값 추정기의 오류 분석 및 시각화
본 논문은 11개의 대표적인 중복값 추정기를 10억 행 규모의 Zipfian 데이터에 적용해 오류 특성을 체계적으로 실험한다. 평균 균일 클래스 크기라는 잠재 파라미터가 오류에 결정적 영향을 미침을 발견하고, 이를 기반으로 오류 패턴을 시각화하는 프레임워크를 제시한다. 또한 샘플링 비율과 추정기 선택에 대한 실용적 가이드라인을 제공한다.
저자: Vinay Deolalikar, Hernan Laffitte
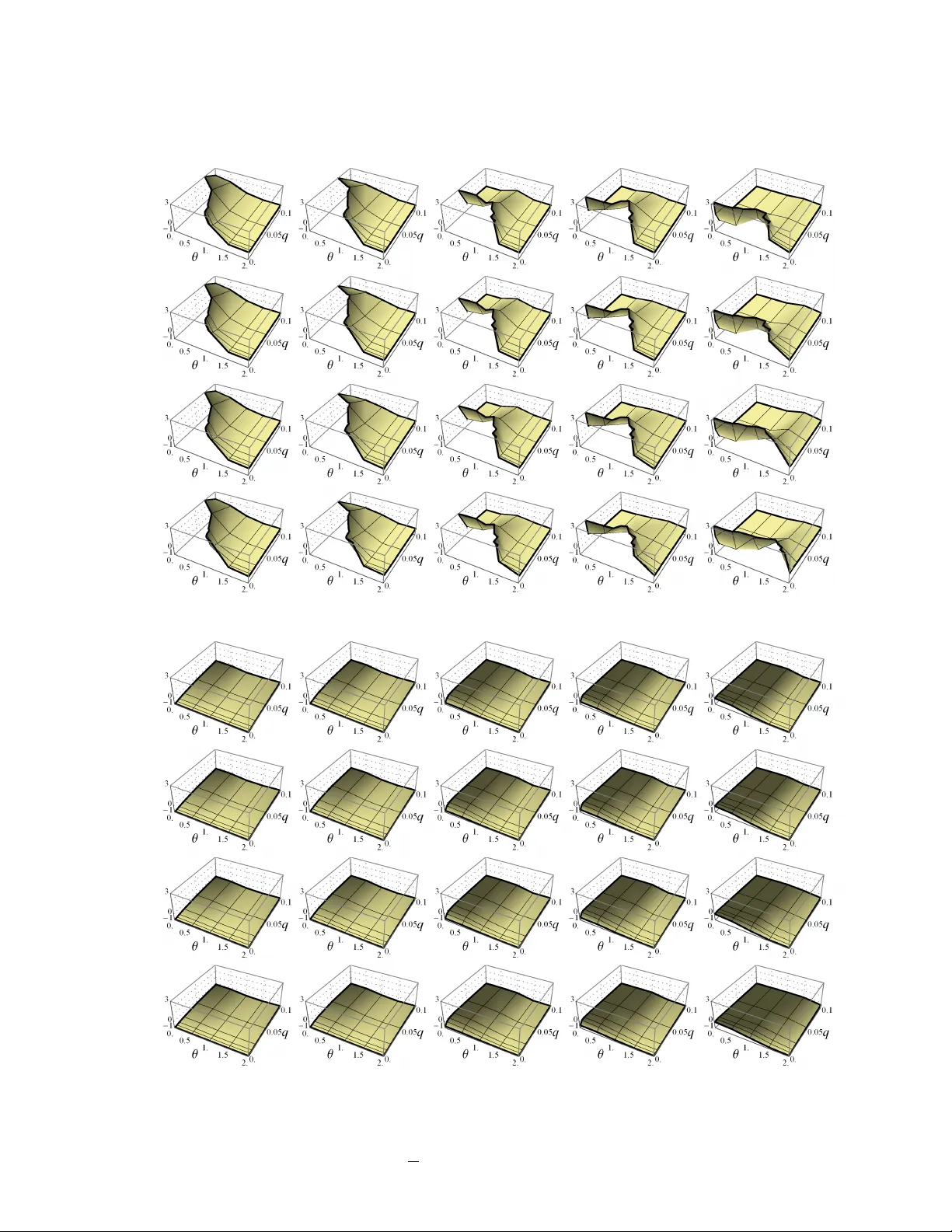
본 논문은 데이터베이스 쿼리 옵티마이저에서 핵심적인 역할을 하는 중복값 추정(distinct value estimation) 문제를 다루며, 특히 오늘날 상용 데이터 웨어하우스가 다루는 수십억 행 규모에서 샘플링 기반 추정기의 오류 특성을 체계적으로 규명한다. 연구 동기는 기존 문헌이 소규모 데이터에 한정된 실험만을 제공하고, 오류를 분석할 수 있는 강력한 이론적 도구가 부족하다는 점에 있다. 이를 해결하기 위해 저자들은 다음과 같은 5단계 접근법을 채택하였다. 1) 11개의 대표적 추정기(ˆD_Sh, ˆD_uj1, ˆD_uj2, ˆD_sj2, ˆD_uj2a, ˆD_GEE, ˆD_AE, ˆD_CL1, ˆD_CL2 등)를 네 가지 방법론(샤프, 잭나이프, GEE/AE, 커버리지 기반)으로 분류하고, 각 추정식의 수학적 형태와 가정(예: 샘플링 비율 q, 인구 크기 N, 클래스 크기 분포)을 명시하였다. 2) 실험 파라미터 공간을 정의하였다. 인구 크기 N은 10⁸~10⁹, 클래스 수 D는 N/10~N/1000 범위, 클래스 크기 분포는 Zipfian(θ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기