SLAM과 객체 인식을 결합한 딥 강화학습으로 도둠 마스터하기
본 논문은 3D FPS 게임 Doom에서 부분 관측과 희소 보상의 문제를 해결하기 위해, 실시간 SLAM 기반 위치 추정과 Faster‑RCNN 객체 탐지를 통해 얻은 의미 지도(semantic map)를 DQN의 입력에 추가하는 방법을 제안한다. 2D 평면 지도에 벽, 에이전트 위치·방향, 적·무기·보급품 등 5가지 객체 카테고리를 색상‑그레이스케일 히트맵 형태로 겹쳐 제공함으로써, 에이전트가 과거에 관찰한 환경 정보를 기억하고 효율적인 탐색…
저자: Shehroze Bhatti, Alban Desmaison, Ondrej Miksik
본 논문은 3차원 첫인칭 슈팅 게임인 Doom에서 딥 강화학습(DRL) 에이전트가 직면하는 주요 문제점—부분 관측, 탐색 공간의 폭발적 증가, 희소 보상—을 해결하기 위해 인간의 인지 메커니즘에서 영감을 얻은 의미 기반 접근법을 제안한다. 기존의 DQN(Deep Q‑Network) 기반 에이전트는 원시 RGB 이미지만을 입력으로 사용해 정책을 학습했으며, 이는 2D Atari 게임에서는 성공적이었지만, 3D 환경에서는 시야가 제한되고 객체가 다양한 관점에서 나타나기 때문에 학습 효율이 급격히 떨어진다.
이를 극복하기 위해 저자들은 두 가지 핵심 기술을 결합한다. 첫 번째는 ORB‑SLAM2를 이용한 실시간 카메라 포즈 추정이다. 게임 엔진이 제공하는 z‑buffer(깊이 버퍼)를 활용해 정적 구조물(벽, 바닥 등)의 3D 포인트 클라우드를 재구성하고, 매 프레임마다 에이전트의 6자유도 위치와 방향을 추정한다. 두 번째는 Faster‑RCNN 기반 객체 탐지기로, Doom 내에서 중요한 역할을 하는 적(몬스터), 무기, 탄약, 체력 팩 등 다섯 가지 카테고리를 실시간으로 식별한다.
이 두 정보를 동일한 전역 좌표계에 투사한 뒤, 고정 크기의 2D ‘플로어 플랜’ 지도에 색상‑그레이스케일 히트맵 형태로 인코딩한다. 지도는 세 가지 레이어로 구성된다: (1) 정적 구조물은 흰색, (2) 에이전트 위치와 방향은 초록색 화살표, (3) 객체는 각각 빨강(몬스터), 보라(체력 팩), 파랑(고급 무기), 노랑(기타 무기·탄약) 등으로 표시한다. 이렇게 만든 의미 지도는 매 타임스텝마다 DQN의 입력 채널에 추가된다. 기존 DQN이 84×84×1 형태의 이미지만을 받았다면, 본 모델은 84×84×2(이미지+지도) 형태의 입력을 받아 학습한다.
네트워크 구조 자체는 기존 DQN과 동일하게 3개의 컨볼루션 레이어와 2개의 완전 연결 레이어를 사용하지만, 입력 차원의 확장으로 인해 객체와 구조 정보가 직접적인 특징으로 학습된다. 이는 에이전트가 현재 시야에 보이지 않는 영역에 대해서도 과거에 탐색한 정보를 활용해 의사결정을 할 수 있게 만든다. 예를 들어, 체력 팩이 보이지 않을 때도 지도에 기록된 위치를 기반으로 이동 경로를 계획하거나, 적이 숨어 있는 구역을 회피하는 전략을 세울 수 있다.
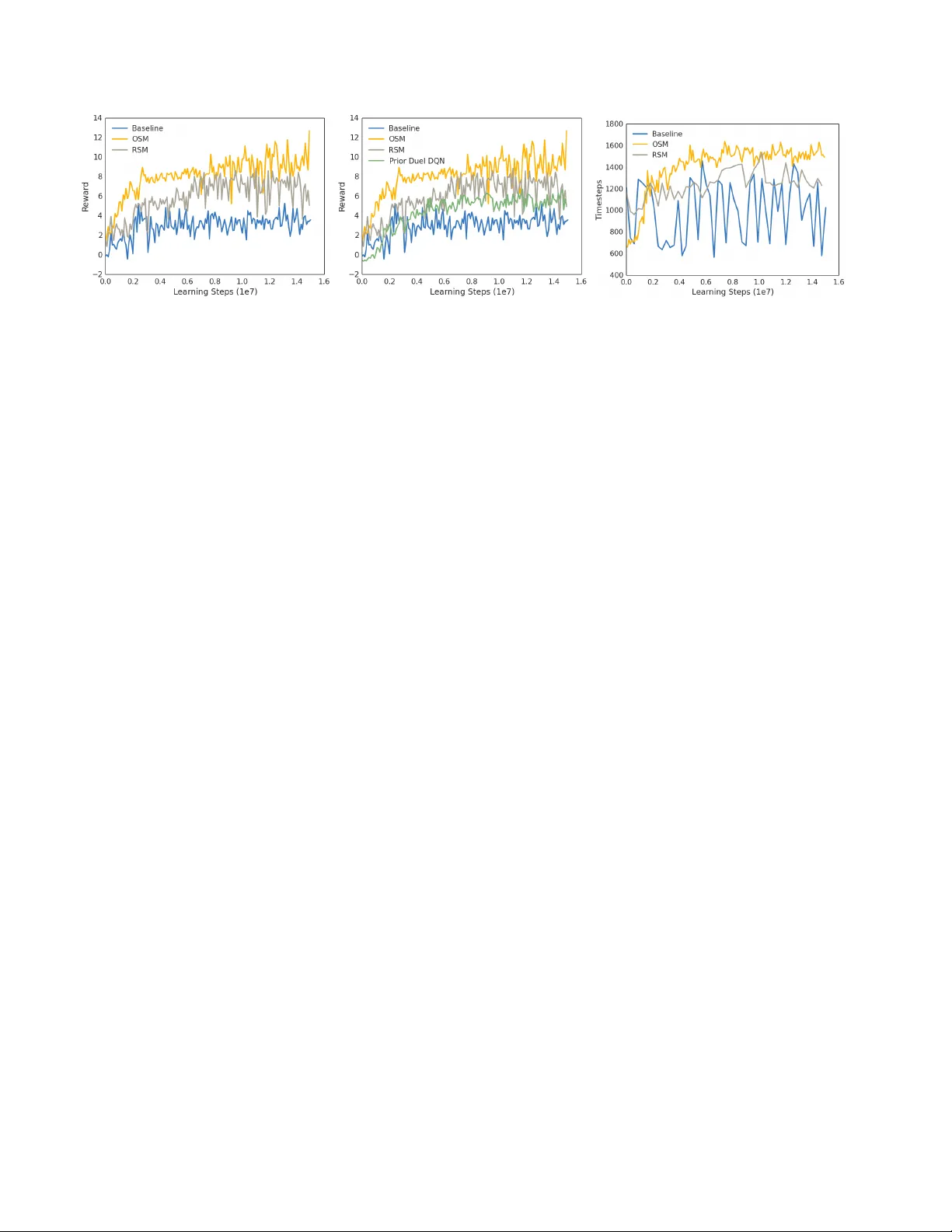
실험은 VizDoom API를 이용해 두 가지 시나리오(기본 사냥 모드와 목표 기반 수집 모드)에서 진행되었다. 비교 대상은 순수 이미지 기반 DQN과 제안된 SLAM‑augmented DQN이다. 결과는 다음과 같다. (1) 학습 초기 단계에서 의미 지도 기반 에이전트는 평균 점수가 20~30% 빠르게 상승하였다. (2) 최종 평균 점수는 기존 DQN 대비 15~30% 향상되었으며, 특히 복잡한 맵에서는 40% 이상 차이가 나타났다. (3) 에피소드당 평균 사망 횟수가 감소하고, 목표(체력 팩·무기) 획득 효율이 크게 증가하였다. 이러한 성능 향상은 의미 지도가 부분 관측 문제를 완화하고, 탐색 효율성을 높이며, 보상이 희소한 상황에서도 목표 지향적인 행동을 가능하게 만든 결과이다.
논문의 한계점으로는 현재 정적 환경을 전제로 하여 움직이는 객체(예: 적)의 위치 업데이트가 제한적이며, 의미 지도 생성에 SLAM과 객체 탐지 연산이 추가되어 실시간 처리에 높은 연산 자원이 요구된다는 점을 들 수 있다. 저자들은 향후 연구에서 동적 객체 추적을 위한 데이터 연관성 기법, 지도 압축 및 효율적인 업데이트 전략, 그리고 Unity나 Unreal Engine과 같은 다른 3D 시뮬레이터에 대한 일반화 가능성을 탐구할 계획이다.
결론적으로, 이 논문은 인간의 인지적 추상화 방식을 딥 강화학습에 도입함으로써 3D 게임 환경에서의 학습 효율과 정책 성능을 크게 개선할 수 있음을 실증하였다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기