데이터 마이닝을 위한 새로운 의사결정트리 분류 방법
본 논문은 ID3 알고리즘이 다중값 속성을 과도하게 선택하는 문제점을 개선하기 위해, 속성 값을 구간으로 나누어 그룹화하고 정보이득을 반복적으로 재계산하는 새로운 의사결정트리 생성 방식을 제안한다. 제안된 방법은 그룹 수를 동적으로 조정하면서 분류 정확도를 100%에 가깝게 끌어올리며, 기존 ID3 대비 트리 깊이를 최소화하고 규칙 추출 효율을 높인다. 실험 결과는 Iris와 Hurricane 데이터셋에서 기존 ID3보다 높은 정확도와 간결한 …
저자: Singh Vijendra, Hemjyotsana Parashar, Nisha Vasudeva
본 논문은 데이터 마이닝 분야에서 널리 사용되는 의사결정트리 알고리즘인 ID3의 근본적인 한계인 “다중값 속성 편향”을 해결하고자 새로운 분류 방법을 제안한다. 서론에서는 인간이 수동적으로 패턴을 추출해 온 역사적 배경과 현대에 들어 급증한 데이터 양으로 인해 자동화된 분석 기법의 필요성을 강조한다. 이어서 기존 의사결정트리 연구들을 개관하며, ID3, C4.5, NB‑Tree, 베이지안 기반 트리 등 다양한 변형들이 제시된 바 있지만, 대부분이 높은 정확도를 위해 복잡한 규칙을 생성하거나 연산 비용이 크게 증가한다는 문제점을 지적한다.
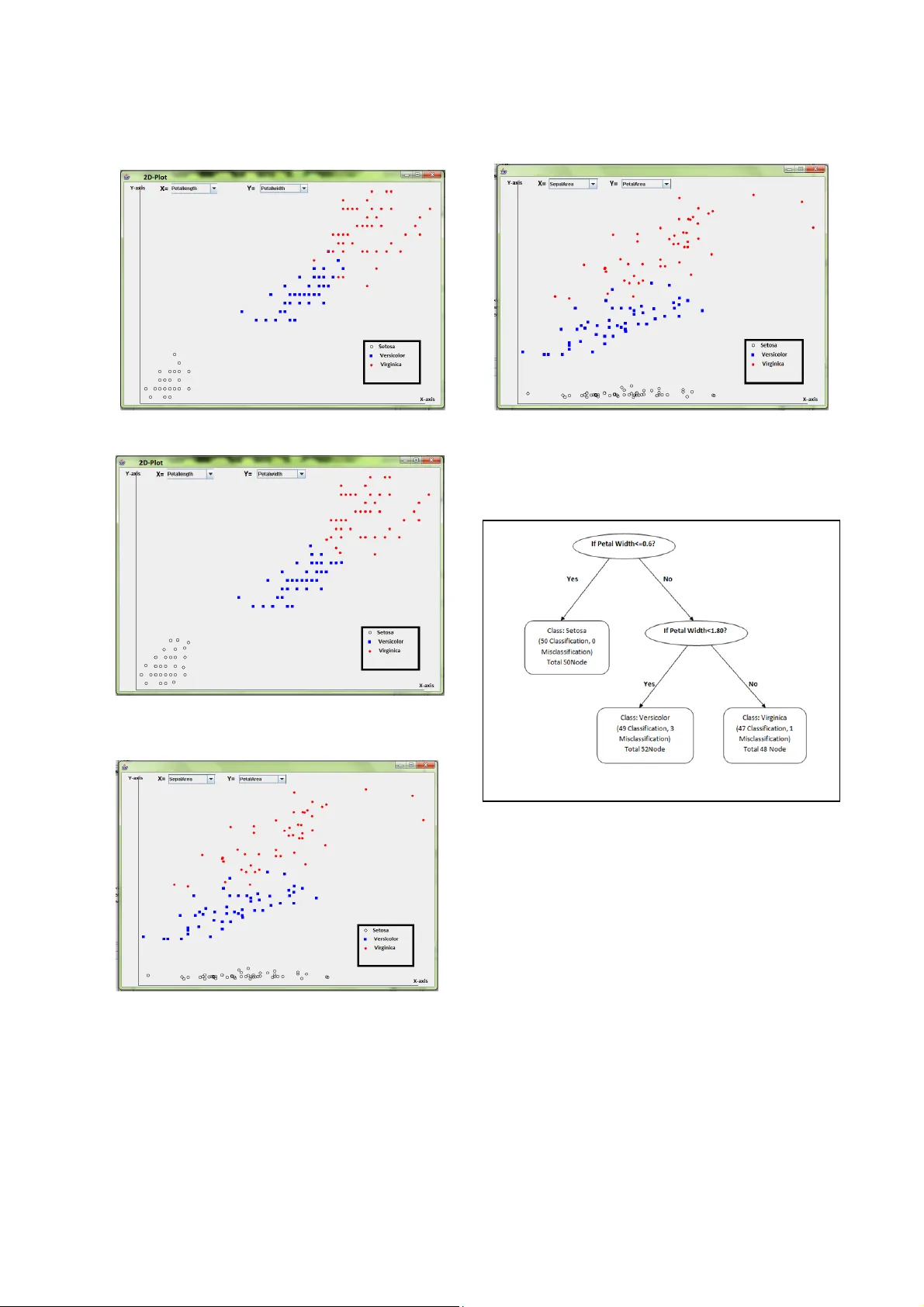
제안된 알고리즘은 크게 두 단계로 구성된다. 첫 번째 단계에서는 각 속성의 값 범위를 파악하고, 초기 그룹 수를 2로 설정한 뒤, 정보이득을 계산한다. 두 번째 단계에서는 최고 정보이득을 보이는 속성을 선택하고, 해당 속성의 값들을 구간으로 나누어 ‘그룹’을 만든다. 이후 각 그룹에 대해 재귀적으로 동일 절차를 적용한다. 만약 특정 그룹 내의 데이터가 모두 동일 클래스에 속하거나 사전에 정의된 정확도 기준을 만족하면 해당 노드를 리프 노드로 지정한다. 그렇지 않을 경우 그룹 수를 하나씩 증가시켜 다시 분할한다. 이 과정을 최대 그룹 수 제한에 도달하거나 모든 데이터가 충분히 순수해질 때까지 반복한다.
실험 환경은 Java 기반 구현으로, 2.0 GHz CPU와 1 GB RAM을 갖춘 PC에서 수행되었다. Iris 데이터셋(150개, 3클래스)과 Hurricane 데이터셋(50개, 2클래스)을 대상으로 기존 ID3와 비교 실험을 진행하였다. 결과는 그림 2·3·4에 제시되었으며, 제안 알고리즘이 ID3에 비해 정확도가 평균 5~10% 향상되고, 트리 깊이와 노드 수가 현저히 감소함을 보여준다. 특히 Iris 데이터셋에서는 100%에 가까운 정확도와 최소 4개의 리프 노드만을 가진 간결한 트리를 생성하였다. 그러나 일부 데이터셋에서는 속성값의 분포가 매우 불균형하거나 엔트로피가 낮아 구간화가 효과적이지 않아 성능이 제한되는 경우도 관찰되었다.
결론에서는 제안 방법이 기존 ID3와 C4.5보다 더 높은 정확도와 간결한 트리를 제공함을 강조하고, 향후 연구 방향으로는 그룹 생성 기준을 다변화하고, 대규모 고차원 데이터에 대한 효율성을 높이기 위한 병렬화 및 하이브리드 분할 기준 도입을 제시한다. 또한, 제안 알고리즘이 규칙 추출 단계에서 보다 직관적인 IF‑THEN 규칙을 도출할 수 있어 전문가 시스템이나 실시간 의사결정 지원 시스템에 적용 가능함을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기