자동 MOS 평가 음성 자연스러움 예측 딥러닝 모델
본 논문은 원시 파형을 입력으로 하는 심층 순환 신경망을 이용해 텍스트‑투‑스피치(TTS) 시스템의 평균 의견 점수(MOS)를 자동으로 예측하는 AutoMOS 모델을 제안한다. 모델은 음성 길이에 관계없이 높은 피어슨·스피어맨 상관관계를 달성했으며, 다수 발화를 평균화할 경우 인간 평가와 거의 동일한 수준의 정확도를 보인다.
저자: Brian Patton, Yannis Agiomyrgiannakis, Michael Terry
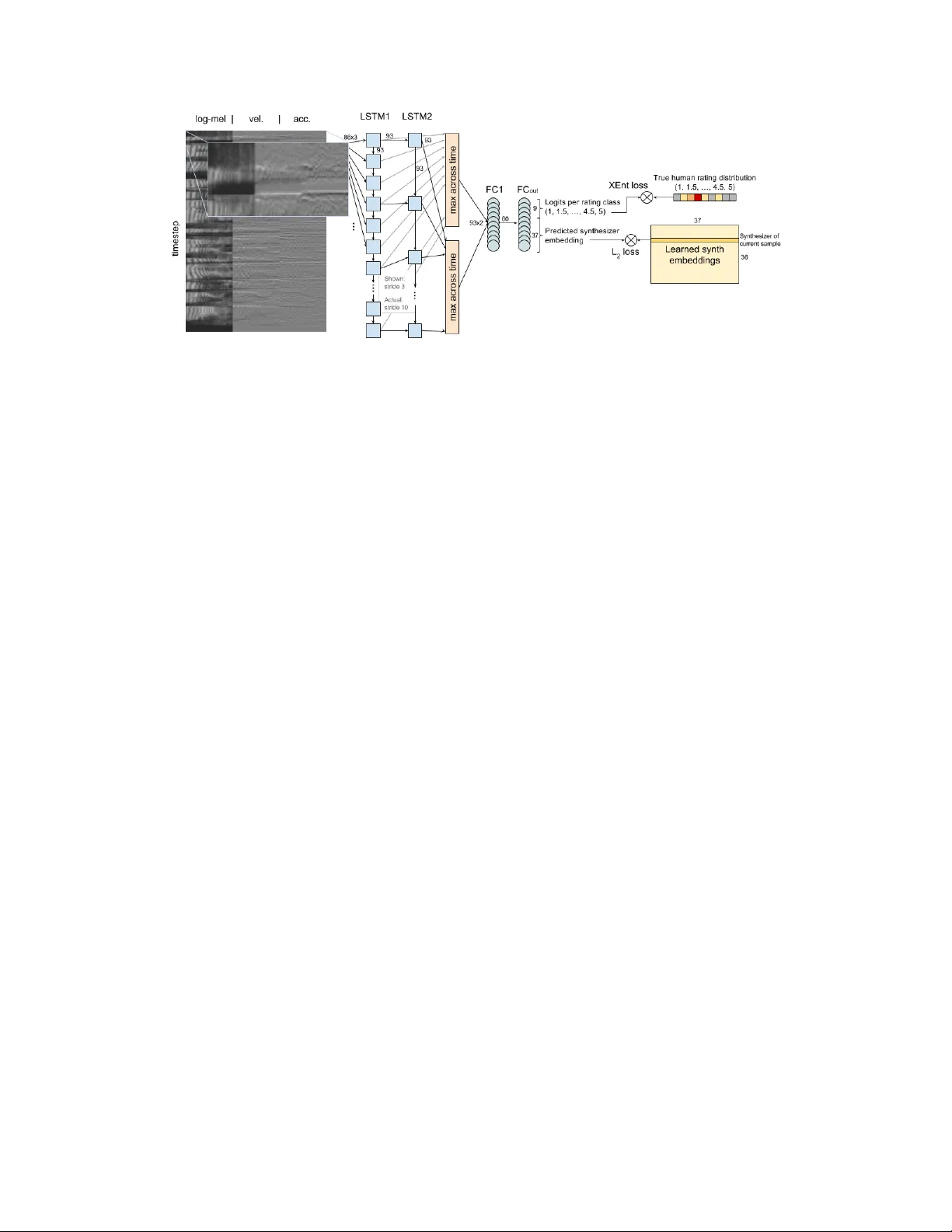
이 논문은 텍스트‑투‑스피치(TTS) 시스템의 자연스러움을 정량화하는 평균 의견 점수(MOS)를 자동으로 예측하는 비침입적 모델, AutoMOS를 제안한다. 전통적으로 MOS는 인간 청취자가 1~5점(0.5 간격) 척도로 평가한 평균값이며, TTS 품질 개선을 위해서는 수많은 발화에 대한 반복적인 인간 평가가 필요했다. 이러한 비용과 시간 문제를 해결하고자 저자들은 원시 오디오 파형만을 입력으로 하는 심층 순환 신경망을 설계했다.
모델 구조는 크게 세 단계로 이루어진다. 첫 번째 단계에서는 16 kHz로 샘플링된 파형을 로그‑멜 스펙트로그램 혹은 시간‑풀링된 1‑D 컨볼루션 특징으로 변환한다. 두 번째 단계에서는 변환된 시계열을 1~2개의 LSTM 층에 통과시켜 시간적 의존성을 학습한다. LSTM 출력은 시간 차원에서 최대 풀링(max‑pooling)되어 고정 길이 벡터가 된다. 마지막 단계에서는 이 벡터를 1~2개의 완전 연결층에 입력해 연속적인 MOS 값을 회귀한다. 추가적으로, 각 합성기(시스템)마다 37 차원의 임베딩을 학습시켜 모델에 정규화 효과와 합성기 간 차이를 반영하도록 했다.
학습 목표는 세 가지가 실험되었다. (1) 개별 평점에 대한 가우시안 로그우도 손실, (2) 실제 MOS와의 L2 회귀 손실, (3) 9‑카테고리(1~5점, 0.5 간격) 분포에 대한 교차 엔트로피 손실. 실험 결과, 카테고리형 교차 엔트로피가 가장 높은 피어슨 상관계수(r = 0.61)를 기록했으며, 이는 L2 손실보다 약간 우수했다. 가우시안 로그우도는 예측 분산이 실제보다 크게 나오면서 수렴이 느려지는 문제가 있었다.
하이퍼파라미터 탐색은 Google Cloud HyperTune을 이용해 학습률(0.0001~0.1), 정규화(L1/L2), LSTM 차원(20~100), 층 수(1~10), 입력 특징 종류(로그‑멜 vs. 컨볼루션), 파생 특징(속도·가속도) 등을 광범위하게 조정했다. 최적 모델은 로그‑멜 입력(86 멜 필터), LSTM 차원 93, 2층 LSTM, 포스트‑LSTM 완전 연결층 차원 60, 그리고 합성기 임베딩 차원 37을 사용했다. 학습은 Adagrad 옵티마이저와 20 k 배치(10 워커 비동기)로 진행되었으며, 5‑fold 교차 검증을 통해 일반화 성능을 평가했다.
데이터셋은 구글 내부 TTS 엔진에서 수집된 168 086개의 인간 평점(47 320개의 발화, 36개의 합성기)으로 구성된다. 각 발화는 5점 척도에 0.5 간격으로 평가되었다. 훈련/검증 분할은 합성기 단위로 이루어졌으며, 동일 합성기의 모든 발화가 같은 폴드에 배치되도록 했다.
성능 평가는 여러 기준으로 수행되었다. (1) 편향 전용 모델(전체 평균 예측)과 발화 길이만을 입력으로 하는 작은 비선형 모델을 베이스라인으로 사용했다. (2) 실제 인간 평점 중 하나를 무작위로 추출한 “샘플 인간 평점”을 비교 기준으로 제시했다. AutoMOS는 발화 수준에서 RMSE 0.462, 피어슨 r = 0.764, 스피어맨 r = 0.757을 기록했으며, 이는 샘플 인간 평점(r ≈ 0.81)보다 약간 낮지만 여전히 실용적인 수준이다. 발화 10개를 평균한 경우 RMSE 0.172, 피어슨 r = 0.933, 스피어맨 r = 0.925에 도달했다. 합성기 수준(36개)에서는 RMSE 0.075, 피어슨 r = 0.987, 스피어맨 r = 0.986으로 인간 평가와 거의 동일한 순위 정렬 능력을 보였다.
오류 분석에 따르면 모델은 훈련 데이터의 점수 분포에 따라 극단적인 점수(1점·5점)를 회피하는 경향이 있다. 또한 특정 텍스트 유형(예: “알람 설정”과 같은 일상 대화 vs. 사전 정의 읽기)에서 일관된 MOS 패턴을 학습했으며, 이는 텍스트 자체가 품질에 미치는 영향을 배제하지 못했기 때문일 수 있다. 향후 연구에서는 텍스트 기반 베이스라인을 도입해 잔차를 모델링하거나, 레이어‑와이즈 관련성 전파(LRP)·활성 차이 전파(DeepLIFT)와 같은 해석 기법을 적용해 모델이 어떤 음향 특징을 중시하는지 시각화할 계획이다.
실용적인 응용 측면에서 AutoMOS는 (1) 대규모 TTS 엔진의 지속적인 품질 모니터링, (2) 자동 파라미터 튜닝 루프에 인간 라벨링 없이 MOS를 피드백으로 활용, (3) 인간 라벨러에게 고품질·저품질 발화를 균형 있게 제공하는 스트라티파이드 샘플링 등에 활용될 수 있다. 저자들은 이미 AutoMOS를 이용해 TTS 엔진을 튜닝하고 있으며, 향후 인간 평가와 비교해 실제 품질 향상 효과를 검증할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기