트위치 채팅 분석: 스트리머 성별에 따른 대화의 차이
초록
트위치 플랫폼에서 수집된 10억 개 이상의 채팅 메시지를 분석한 결과, 여성 스트리머는 외모와 관련된 객체화된 댓글을, 남성 스트리머는 게임 관련 댓글을 더 많이 받는 것으로 나타났습니다. 특히 인기 있는 스트리머일수록 이러한 성별 간 차이가 더욱 뚜렷했습니다. 문서 임베딩 기법을 활용한 분석은 채팅 내용만으로 스트리머의 성별과 시청자의 성별 선호도를 높은 정확도로 예측할 수 있음을 보여주었습니다.
상세 분석
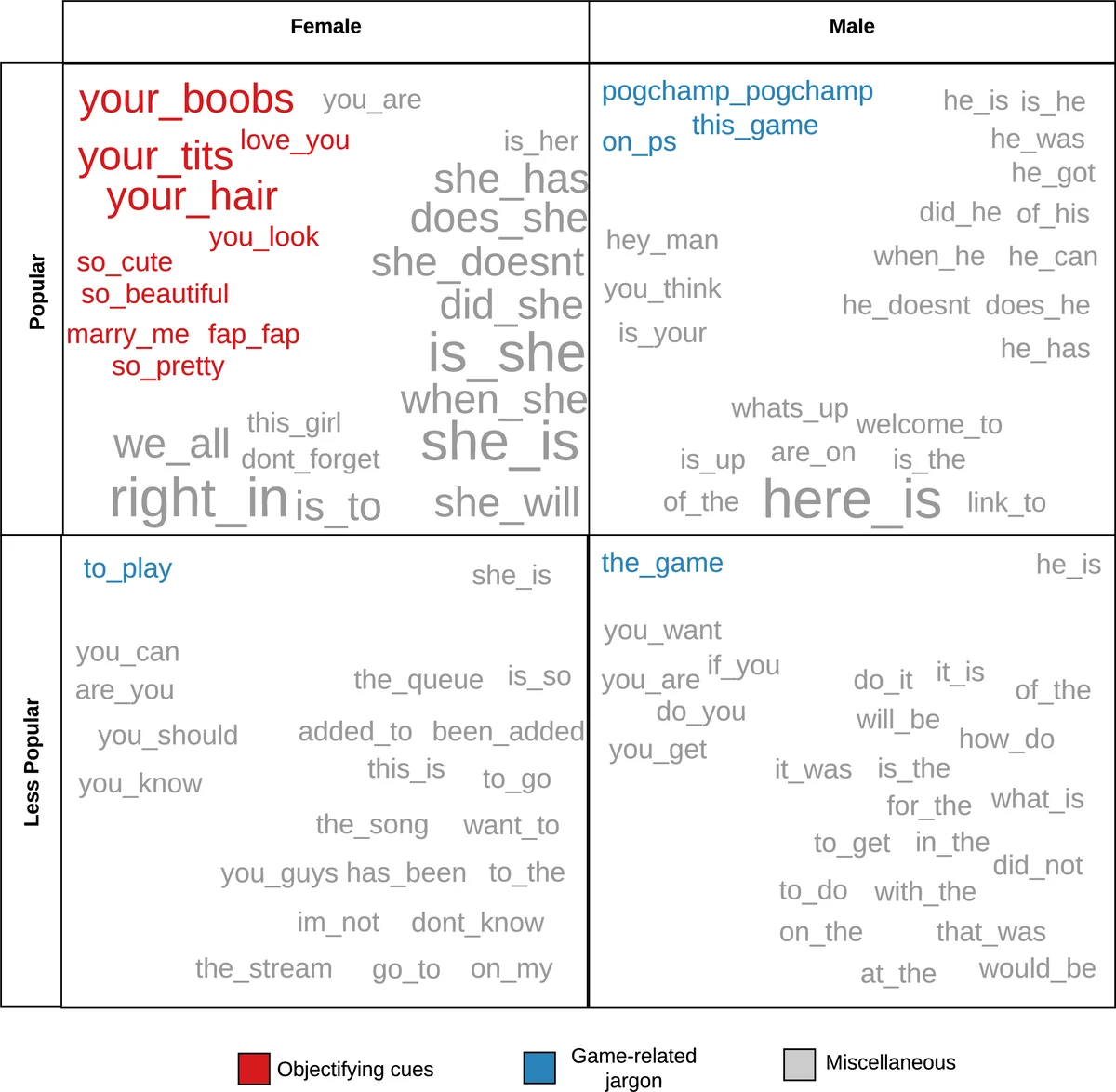
본 연구는 대규모 텍스트 데이터를 활용한 계산 사회과학의 정교한 방법론을 보여줍니다. 핵심 분석 방법은 크게 두 가지입니다. 첫째, ‘정보적 디리클레 사전 분포를 활용한 로그 오즈비(Log-Odds Ratio with Informative Dirichlet Prior)’ 기법을 사용하여 남성/여성 스트리머 채널에서 통계적으로 과대표현된 단어와 바이그램을 추출했습니다. 이 방법은 빈도가 높은 단어의 유의미한 차이를 검출하는 데 효과적이며, TF-IDF나 PMI보다 희귀 단어의 변동에 과민반응하지 않는 장점이 있습니다. 분석 결과, 인기 있는 여성 채널에서는 ‘cute’, ‘beautiful’, ‘boobs’ 등의 객체화 언어가, 인기 있는 남성 채널에서는 ‘reset’, ‘shields’, ‘melee’ 등의 게임 전문 용어가 두드러졌습니다. 흥미롭게도 덜 인기 있는 여성 채널에서는 이러한 객체화 언어보다 ‘hello’, ‘bye’, ‘song’과 같은 사회적 상호작용 언어가 더욱 두드러져, 채널의 인기도가 대화의 성격에 미치는 복합적인 영향을 시사합니다.
둘째, ‘문서 벡터(Doc2Vec)‘라는 신경망 기반 벡터 임베딩 기법을 채택했습니다. 이는 Word2Vec을 문서 수준으로 확장한 모델로, 개별 채널과 사용자의 모든 채팅 메시지를 하나의 문서로 취급하여 100차원의 벡터 공간에 임베딩합니다. 이 공간에서 t-SNE를 이용한 시각화는 성별에 따라 채널 벡터가 군집화되는 현상을 명확히 보여주었습니다. 이 임베딩 벡터를 특징으로 사용한 L2 정규화 로지스틱 회귀 모델은 스트리머의 성별을 87%의 정확도로 예측했으며, AUC는 0.93에 달했습니다. 이는 단순한 Bag-of-Words 모델(정확도 74%, AUC 0.80)을 크게 상회하는 성능입니다. 모델이 학습한 특징을 살펴보면, 여성 채널은 ‘cute’, ‘beautiful’ 등의 외형 관련 단어 벡터와 가깝고, 남성 채널은 ’epoch’, ‘attempts’ 등의 게임 진행 관련 단어 벡터와 가까웠습니다. 이는 머신러닝 모델이 명시적 지도 없이도 채팅 담론의 깊은 성별 편향 구조를 포착할 수 있음을 입증합니다.
연구의 핵심 통찰은 성별 불평등이 단순히 스트리머의 성별에만 기인하는 것이 아니라, 시청자 집단의 구성과 행태와도 긴밀히 연결된 ‘상호작용적 현상’이라는 점입니다. 많은 시청자가 특정 성별의 스트리머 채널에만 활동을 집중하는 현상이 확인되었으며, 이들의 언어 사용 패턴 또한 뚜렷이 구분되었습니다. 즉, 플랫폼 내의 젠더화된 담론은 방송자와 수용자 모두에 의해 공동으로 구축되고 유지되는 것입니다.
댓글 및 학술 토론
Loading comments...
의견 남기기