그룹라쏘를 이용한 딥 뉴럴 네트워크 자동 노드 선택
본 논문은 그룹라쏘(gLasso) 정규화를 DNN 학습에 통합하여, 은닉층 노드를 자동으로 선택·제거하는 방법을 제안한다. 출력·입력 가중치 벡터를 각각 그룹화해 정규화하고, TED Talks 음성 데이터를 이용한 DNN‑HMM 인식 실험에서 gLasso가 L2 정규화보다 명확한 노드 구분과 성능 유지·축소를 달성함을 보였다.
저자: Tsubasa Ochiai, Shigeki Matsuda, Hideyuki Watanabe
**1. 서론**
딥 뉴럴 네트워크(DNN)는 깊은 층 구조와 방대한 파라미터 수 덕분에 음성 인식 등 다양한 분야에서 뛰어난 성능을 보인다. 그러나 네트워크가 커질수록 연산 비용·메모리 요구가 급증하고, 훈련 데이터에 대한 과적합 위험도 커진다. 기존 연구에서는 네트워크 재구성이나 사후 프루닝을 통해 규모를 축소했지만, 이는 추가적인 재학습·미세조정이 필요했다. 따라서 학습 단계에서 자동으로 ‘필요하고 충분한’ 구조를 찾아내는 방법이 요구된다.
**2. 제안 방법**
저자는 그룹라쏘(gLasso) 정규화를 DNN 훈련에 직접 삽입한다. 가중치 행렬 W⁽ˡ⁾의 열(Outgoing) 또는 행(Incoming)을 각각 하나의 그룹으로 보고, 각 그룹의 ℓ2 노름을 합산한 정규화 항 𝑅_group을 손실함수에 추가한다. 전체 손실은
L(Λ)=E(Λ)+α·𝑅_group({W⁽ˡ⁾}_{l=2}^{L})+β·𝑅_L2(W¹,{b⁽ˡ⁾}_{l=1}^{L})
여기서 E는 교차 엔트로피 손실, α·β는 정규화 강도 조절 파라미터이다. gLasso의 미분 결과는 ∂𝑅_group/∂w_j = w_j /‖w_j‖₂ 로, 노드의 가중치 벡터 노름이 작을수록 빠르게 0에 수렴한다. 반면 L2 정규화는 ∂𝑅_L2/∂w_j = w_j 로 전체 가중치를 균등하게 축소한다.
**3. 노드 선택 메커니즘**
학습이 진행되면서 일부 가중치 벡터의 노름이 미리 정한 임계값 θ(예: 10⁻²) 이하로 떨어진다. 이때 해당 노드와 연결된 가중치를 ‘폐기 가능’이라 판단하고, 실제 네트워크에서 제거한다. 제거 시 바이어스는 상위 층으로 재분배한다(특히 Incoming 그룹화 경우). 이렇게 하면 노드 제거 후에도 활성값에 큰 변화가 없으며, 성능 저하가 최소화된다.
**4. 실험 설정**
- **데이터**: TED Talks 강연 음성, 62 h, 3,944 senone, 어휘 179,604.
- **모델**: 6층 MLP (입력 429 차원, 은닉층당 2048 또는 4096 유닛, 시그모이드 활성화).
- **학습**: RBM 사전학습 후 교차 엔트로피 + 정규화 손실 최소화, 20 epoch, β=0, α 변동.
- **비교**: gLasso‑O(Outgoing), gLasso‑I(Incoming), L2‑O, L2‑I 네 경우.
- **평가**: DNN 자체의 senone classification accuracy(SCA)와 최종 HMM‑LM 결합 인식의 word error rate(WER).
**5. 결과**
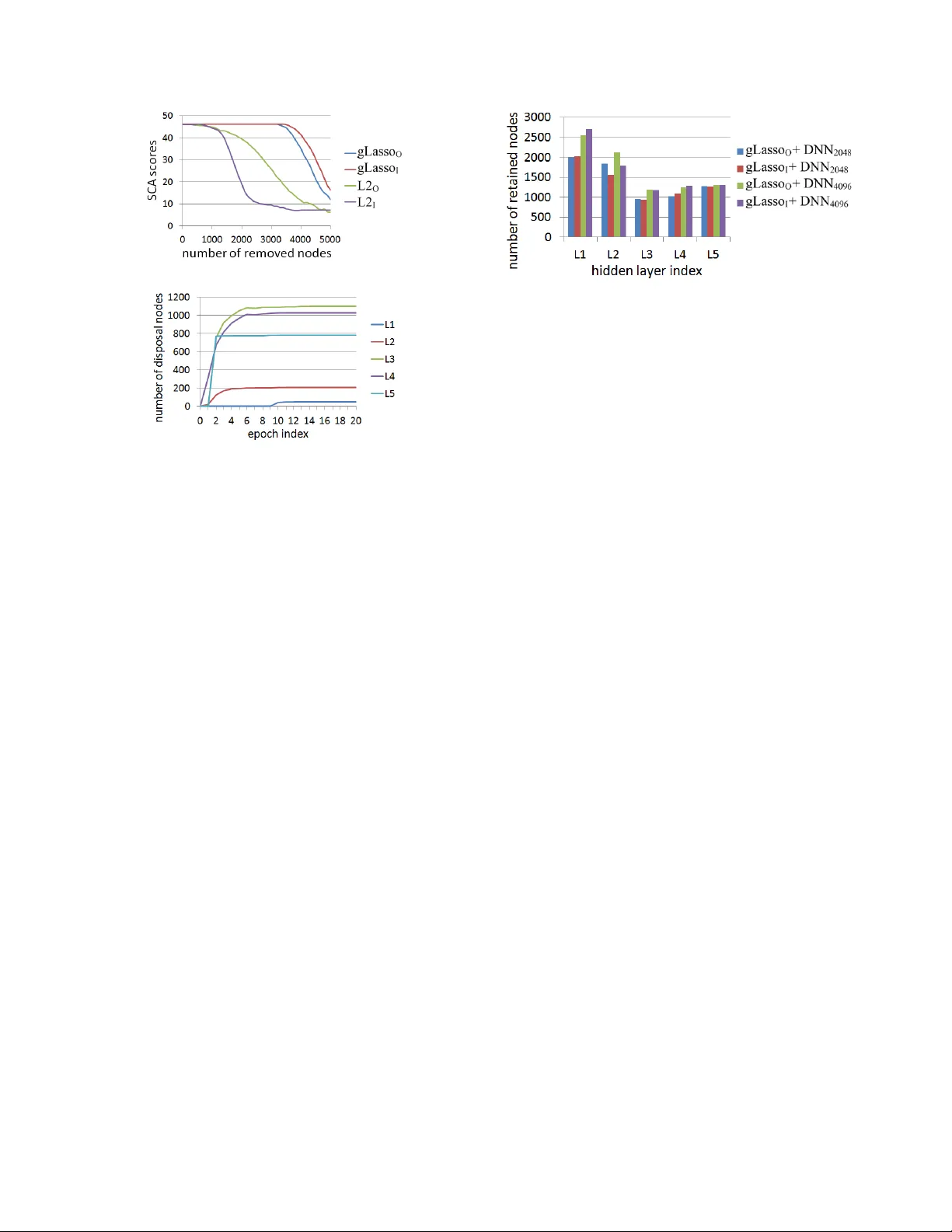
- **기본 성능**: 모든 경우에서 SCA≈46 %, WER<19 % 로 높은 정확도 확보.
- **가중치 노름 분포**: gLasso는 두 개의 뚜렷한 구간(큰값·작은값)으로 노름을 분리, L2는 10⁰~10¹ 사이에 집중.
- **노드 제거**: gLasso‑O에서는 3,161개, gLasso‑I에서는 3,368개 노드를 θ=10⁻² 로 제거했음에도 SCA와 WER 변화가 거의 없었다. 반면 동일 수의 노드를 L2 기반 모델에서 제거하면 SCA가 크게 떨어지고 WER가 급증했다.
- **학습 초반 폐기 가능 노드**: 1~5 epoch 사이에 대부분의 폐기 가능 노드가 식별, 즉 gLasso는 초기에 불필요 파라미터를 억제한다.
- **추가 분석**: 노드 제거 순서에 따른 SCA 변화 그래프에서, L2는 노드 제거 시 성능이 서서히 감소하는 반면, gLasso는 낮은 노름 영역에 있는 노드만 제거해도 성능이 유지되는 ‘플랫’ 구간을 보였다.
**6. 논의 및 의의**
- **구조적 프루닝**: 가중치 스칼라가 아닌 벡터 단위 정규화로 노드 수준의 구조적 압축이 가능함을 입증.
- **재학습 불필요**: 학습 단계에서 이미 불필요 노드를 식별·제거하므로 사후 재학습이 필요 없으며, 실시간 시스템에 바로 적용 가능.
- **확장성**: 본 방법은 출력·입력 가중치뿐 아니라 컨볼루션 필터, 트랜스포머 헤드 등 다양한 파라미터 그룹에도 적용 가능할 것으로 기대된다.
- **제한점**: 현재 실험은 음성 인식에 한정되었으며, 다른 도메인(이미지, 자연어)에서의 일반화 검증이 필요하다. 또한 θ 선택이 경험적이므로 자동 임계값 설정 기법이 추가 연구 과제로 남는다.
**7. 결론**
그룹라쏘 정규화를 DNN 학습에 통합함으로써, 은닉층 노드를 자동으로 선택·제거하는 효과적인 메커니즘을 제시하였다. 실험 결과는 gLasso가 L2 정규화에 비해 명확한 노드 구분, 초기 단계에서의 불필요 파라미터 억제, 그리고 사후 성능 저하 없이 대규모 네트워크를 압축할 수 있음을 보여준다. 이는 연산·메모리 제한이 있는 환경에서 고성능 DNN을 구현하는 데 실용적인 해결책이 될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기