유전체 텐덤 복제의 용량과 표현력
초록
본 논문은 제한된 길이의 텐덤 복제 연산을 통해 초기 시드 문자열에서 생성될 수 있는 문자열 집합의 용량(capacity)과 표현력(expressiveness)을 정의하고, 알파벳 크기와 복제 길이에 따른 정확한 용량값과 완전 표현 가능 여부를 완전히 규명한다. 특히 알파벳이 4 이상일 때는 복제 길이에 관계없이 완전 표현이 불가능함을 보이며, 이는 Thue의 무제곱(스퀘어프리) 문자열 존재 결과와 연결된다.
상세 분석
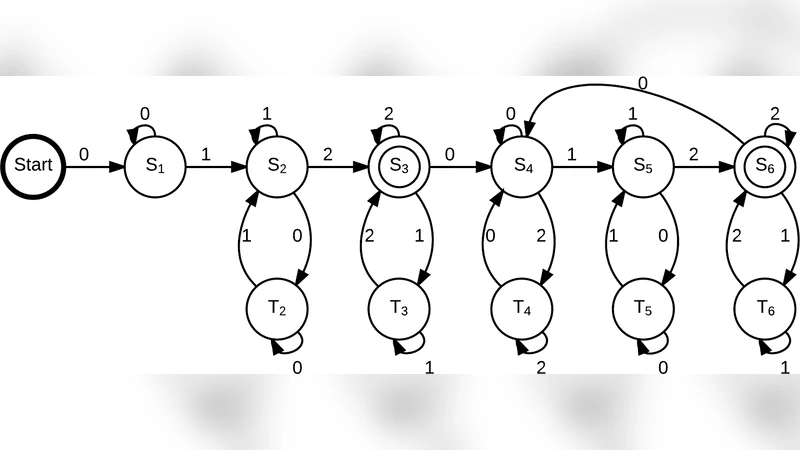
논문은 먼저 “텐덤 복제 문자열 시스템”을 (알파벳 Σ, 시드 s, 복제 규칙 집합 T) 형태로 정의하고, 복제 규칙 Ttan≤k 를 “길이 ≤k 인 텐덤 복제”로 설정한다. 용량(capacity)은 lim supₙ (log_{|Σ|}|S∩Σⁿ|)/n 로 정의되며, 이는 시스템이 생성할 수 있는 길이 n 문자열의 수가 알파벳 크기에 비해 어느 정도 성장하는지를 측정한다. 완전 표현성(full expressiveness)은 Σ*의 모든 문자열이 시스템 내 어떤 문자열의 부분 문자열로 나타날 수 있음을 의미한다.
주요 정리는 세 부분으로 나뉜다. 첫째, ternary(3-알파벳) 시스템에 대해 seed=012, 복제 길이 ≤3 인 경우 정확한 용량값을 log₃( (3+√5)/2 )≈0.876036 로 계산한다. 이를 위해 저자들은 해당 시스템을 유한 자동기(Finite Automaton)로 모델링하고, Perron‑Frobenius 이론을 이용해 전이 행렬의 최대 고유값을 구해 용량을 추정한다. 또한, 자동기의 정규 표현식 R을 도출하고, R이 생성하는 언어 L_R이 시스템 S와 동등함을 증명함으로써 용량 계산의 정당성을 확보한다.
둘째, 표현성 측면에서 알파벳 크기에 따른 전이 현상을 분석한다. 알파벳이 2 또는 3일 때는 복제 길이 k를 충분히 크게 하면(예: k≥4) 모든 문자열이 부분 문자열로 나타날 수 있어 완전 표현성이 확보된다. 반면, 알파벳이 4 이상이면 복제 길이와 무관하게 완전 표현이 불가능함을 보인다. 이 결과는 1906년 Axel Thue가 제시한 ternary 무제곱 문자열 존재 정리를 활용한다. Thue의 결과에 따르면, 3-알파벳에서는 임의의 길이까지 무제곱(두 번 연속 반복) 없이 문자열을 만들 수 있으므로, 이를 4-알파벳 문자열에 매핑하면 특정 패턴이 절대로 생성되지 않음을 증명한다. 따라서 4‑알파벳 이상에서는 “어떠한 시드와 복제 길이 제한”에도 불구하고 일부 문자열이 절대 나타나지 않아 완전 표현성이 깨진다.
셋째, 정규성(regularity) 문제를 다룬다. 기존 연구에서는 복제 길이 k≥4이면 시스템 언어가 비정규임을 보였지만, k=3 일 때는 정규성 여부가 미해결이었다. 논문은 모든 알파벳 크기와 시드에 대해 k=3 인 경우 언어가 정규임을 증명한다. 이는 자동기 구성과 상태 전이 분석을 통해 이루어지며, 정규성을 확보함으로써 앞서 제시한 용량 계산을 일반화할 수 있다.
전체적으로 본 연구는 “복제 길이”가 시스템의 생성 능력에 미치는 영향을 정량화하고, “시드”보다 복제 길이가 더 결정적인 역할을 함을 입증한다. 또한, 용량과 표현성 사이의 직접적인 연관성을 밝혀, 완전 표현이 불가능한 경우 용량이 1보다 작음(즉, 정보 효율이 제한됨)을 보인다. 이러한 이론적 결과는 유전체 내 텐덤 반복 구조의 진화적 제한을 이해하고, DNA 데이터 저장 및 합성 생물학 설계에 실용적인 인사이트를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기