생체 시계열을 위한 단어집합 표현
초록
본 논문은 EEG와 ECG와 같은 생체 시계열 데이터를 텍스트 문서에 비유하여, 짧은 구간을 ‘단어’로 추출하고 이를 코드북에 매핑한 뒤 히스토그램 형태의 Bag‑of‑Words(BOW) 표현으로 변환한다. 시간 순서는 무시하지만, 지역·전역 구조 정보를 동시에 활용해 높은 분류 정확도를 달성한다. 세 가지 실험 데이터셋에서 파라미터 민감도가 낮고 잡음에 강인함을 입증하였다.
상세 분석
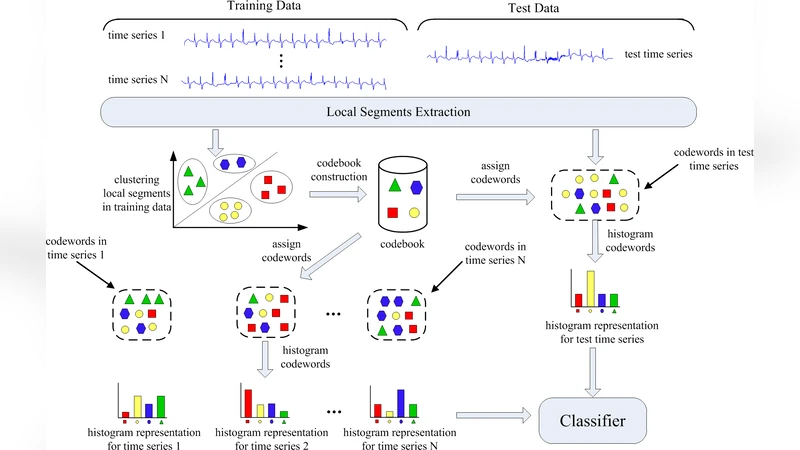
본 연구는 기존 시계열 분류 기법이 갖는 복잡도와 파라미터 의존성을 완화하기 위해, 텍스트 마이닝에서 영감을 얻은 Bag‑of‑Words(BOW) 모델을 생체 시계열에 적용하였다. 핵심 아이디어는 시계열을 연속적인 짧은 구간(윈도우)으로 슬라이딩하고, 각 구간을 고정 차원의 특성 벡터(예: DFT, DWT, 혹은 원시 샘플)로 변환한 뒤, K‑means 군집화를 통해 코드북을 구축한다는 것이다. 이후 각 구간을 가장 가까운 코드워드에 할당하고, 전체 시계열에 등장한 코드워드의 빈도를 히스토그램 형태로 집계한다. 이 과정에서 시간 순서는 무시되지만, 동일한 구조적 패턴이 반복될 경우 동일 코드워드가 다수 등장하게 되므로, 전역적인 구조 유사성을 효과적으로 포착한다.
파라미터 분석에서는 구간 길이와 코드북 크기가 결과에 미치는 영향을 실험적으로 평가하였다. 구간 길이가 너무 짧으면 잡음에 민감해지고, 너무 길면 중요한 세부 패턴을 놓칠 위험이 있다. 그러나 실험 결과는 0.52초 범위 내에서 성능 변동이 미미함을 보여, 실제 적용 시 유연한 설정이 가능함을 시사한다. 코드북 크기 역시 50200 사이에서 큰 차이가 없으며, 과도한 확장은 계산량만 증가시킨다.
잡음에 대한 강인성은 인위적으로 가우시안 잡음을 추가한 실험을 통해 검증되었다. BOW 히스토그램은 개별 구간의 변동을 평균화하는 효과가 있어, SNR이 낮은 상황에서도 비교적 안정적인 분류 성능을 유지한다. 이는 특히 임상 현장에서 전극 접촉 불량이나 움직임 아티팩트가 빈번히 발생하는 EEG/ECG 데이터에 유리하다.
비교 대상으로는 전통적인 동적 시간 왜곡(DTW) 기반 최근접 이웃, 그리고 파워 스펙트럼 기반 SVM을 포함하였다. 전반적으로 BOW‑SVM 조합이 정확도와 F1‑score에서 우수했으며, 특히 다중 클래스(예: 다양한 발작 유형) 구분에서 차별화된 성능을 보였다. 다만, 시간 순서를 완전히 무시하기 때문에 급격한 전이(transient) 이벤트를 포착하는 데는 제한이 있을 수 있다. 이를 보완하기 위해 윈도우 오버랩 비율을 조절하거나, 히스토그램에 위치 정보를 부가하는 하이브리드 방식을 제안할 여지가 있다.
결론적으로, 본 논문은 복잡한 시계열 모델링 없이도 간단한 BOW 구조만으로 높은 분류 정확도와 파라미터 안정성을 달성했으며, 실시간 임상 모니터링 시스템에 적용 가능한 경량화된 솔루션을 제시한다.