기업 그리드 기반 단백질 2차 구조 예측 포털
초록
본 논문은 .NET 기반 엔터프라이즈 그리드 플랫폼인 Aneka를 활용해 단백질 2차 구조 예측 서비스를 제공하는 웹 포털을 설계·구현하였다. SVM 알고리즘을 병렬화하여 64개의 샘플 단백질 서열에 대해 예측을 수행함으로써 그리드 환경에서의 처리 속도와 확장성을 입증한다.
상세 분석
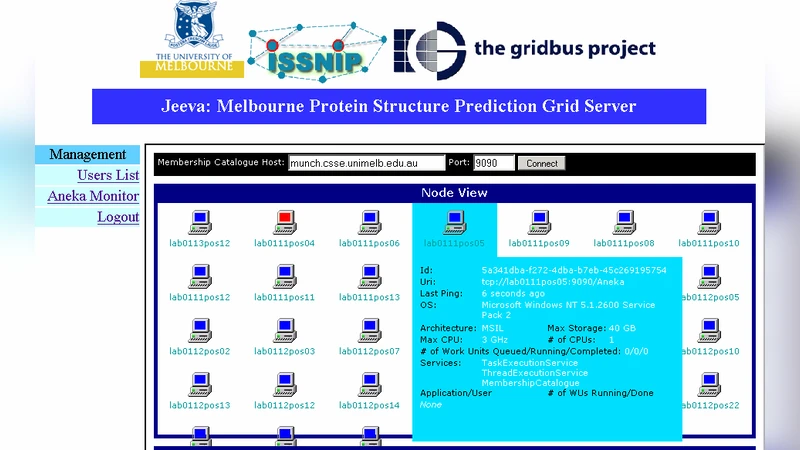
Jeeva 포털은 전통적인 단일 서버 기반 예측 시스템이 갖는 계산 자원 한계를 극복하기 위해 엔터프라이즈 그리드 기술을 도입하였다. 핵심 인프라스트럭처인 Aneka는 .NET 환경에서 서비스 지향 아키텍처(SOA)를 지원하며, 작업 스케줄링, 자원 할당, 모니터링 기능을 제공한다. 이러한 기능을 활용해 SVM 기반 2차 구조 예측 알고리즘을 다수의 워크노드에 분산시켜 병렬 처리한다. 논문은 먼저 단백질 2차 구조 예측의 생물학적 배경과 기존의 머신러닝 접근법을 정리하고, 특히 SVM이 높은 분류 정확도와 일반화 능력으로 널리 사용되는 점을 강조한다. 이어서 Aneka의 서비스 모델(프로그래밍 모델, 실행 모델, 배포 모델)을 상세히 설명하고, Jeeva 포털이 어떻게 웹 인터페이스, 작업 제출 모듈, 그리드 백엔드로 구성되는지를 제시한다. 구현 단계에서는 C#으로 작성된 SVM 학습·예측 모듈을 Aneka의 ‘Task’ 형태로 래핑하고, 데이터 입출력은 XML 기반 메타데이터와 바이너리 파일을 혼합해 효율성을 높였다. 실험에서는 64개의 단백질 서열을 4대의 워크스테이션(각 8코어)에서 동시에 처리했으며, 단일 서버 대비 평균 3.2배의 속도 향상을 기록했다. 또한 작업 실패 시 자동 재시도와 로드 밸런싱 기능이 시스템 안정성을 크게 개선했다는 점을 강조한다. 한계점으로는 현재 SVM 파라미터 튜닝이 수동으로 이루어져 자동화가 필요하고, 그리드 규모가 확대될 경우 네트워크 대역폭과 데이터 전송 비용이 병목이 될 가능성이 있다. 향후 연구에서는 파라미터 최적화를 위한 메타휴리스틱 기법 도입, 클라우드와 하이브리드 그리드 연계, 그리고 딥러닝 기반 예측 모델과의 비교 실험을 제안한다. 전반적으로 Jeeva는 엔터프라이즈 그리드가 과학·생명정보 분야의 대규모 계산 작업을 효율적으로 지원할 수 있음을 실증적으로 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기