웹사이트 링크 구조의 숨은 규칙
초록
본 연구는 18개의 서로 다른 웹사이트를 전면 크롤링하여 내부 링크 구조를 분석한다. 1차·2차 위상 특성에서는 사이트마다 큰 차이를 보였지만, 삼각형(3차) 구조에서는 일관된 패턴이 나타나 웹사이트 고유의 불변량을 제시한다. 이 특성은 일반적인 인터넷, AS 네트워크, 인용 네트워크 및 기존 생성 모델에서는 발견되지 않는다.
상세 분석
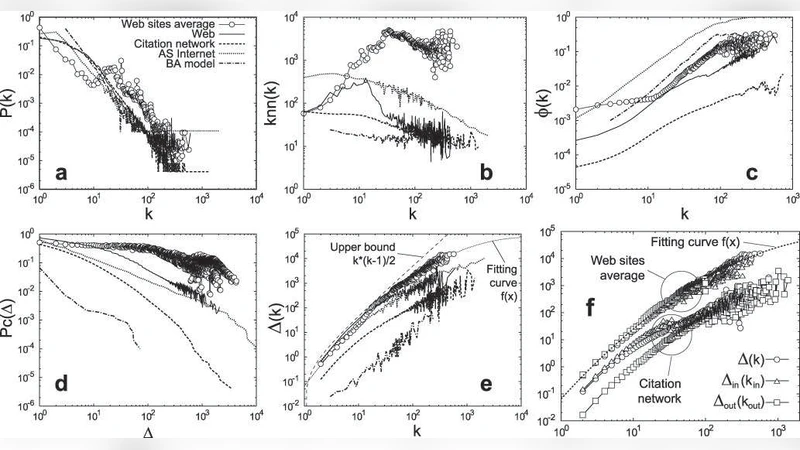
이 논문은 웹 전체가 아니라 개별 웹사이트 내부의 링크 토폴로지를 집중적으로 탐구한다는 점에서 의미가 크다. 18개의 사이트는 정부 부처, 기업, 대학 등 다양한 도메인과 규모(수천 페이지에서 수백만 페이지)로 구성되어 있어 결과의 일반화 가능성을 높인다. 연구진은 각 사이트를 완전 크롤링한 뒤, 노드(페이지)와 엣지(하이퍼링크)로 이루어진 그래프를 구축하고, 1차(노드 차수), 2차(연결된 노드 쌍의 공통 이웃) 및 3차(삼각형 클러스터) 위상 특성을 정량화하였다.
1차와 2차 특성에서는 사이트마다 평균 차수, 차수 분포, 이웃 연결성 등에 현저한 차이가 나타났다. 이는 각 조직의 정보 구조, 콘텐츠 관리 정책, 사용자 흐름 등에 따라 링크 설계가 크게 달라짐을 시사한다. 특히, 일부 대형 사이트는 높은 평균 차수와 낮은 평균 경로 길이를 보이는 반면, 소규모 사이트는 보다 분산된 구조를 띤다.
반면, 3차 위상 특성인 삼각형 클러스터링 계수는 모든 사이트에서 놀라울 정도로 유사한 값을 보였다. 이는 서로 다른 도메인과 규모에도 불구하고, 페이지 간 상호 연결이 일정한 패턴을 따른다는 강력한 증거이다. 논문은 이 현상을 “웹사이트 링크 구조의 불변량”이라고 명명하고, 삼각형이 형성되는 비율이 전체 링크 수 대비 일정하게 유지된다는 점을 강조한다.
또한, 저자들은 이 3차 특성이 전통적인 인터넷 라우팅 그래프(AS 레벨), 과학 논문 인용 네트워크, 그리고 Barabási‑Albert와 같은 무작위 척도 자유 모델에서도 나타나지 않음을 실험적으로 입증한다. 이는 웹사이트 내부 구조가 단순히 규모의 법칙이나 무작위 연결에 의해 설명될 수 없으며, 고유한 설계 원칙이나 인간‑컴퓨터 상호작용 메커니즘이 작용한다는 중요한 시사점을 제공한다.
마지막으로, 논문은 이러한 불변량을 활용해 웹사이트 품질 평가, 자동 구조 분석, 그리고 악성 사이트 탐지 등에 응용할 가능성을 제시한다. 향후 연구에서는 더 많은 사이트 샘플링과 시간에 따른 동적 변화를 추적함으로써, 이 불변량이 얼마나 안정적인지, 혹은 특정 이벤트(리디자인, 보안 침해 등)에서 어떻게 변형되는지를 조사할 필요가 있다.