대규모 그리드 환경을 위한 DIANA 계층형 스케줄링 최적화
초록
본 논문은 기존 메타‑스케줄러가 로컬에 이미 배치된 작업을 재조정하지 못해 동적 부하 변화에 취약한 문제를 지적한다. 이를 해결하기 위해 피어‑투‑피어 기반의 DIANA(Data Intensive and Network Aware) 스케줄링 알고리즘과 큐 관리 메커니즘을 제안하고, 수학적 모델링 및 사례 연구를 통해 대량 작업(Bulk Job) 처리와 부하 분산에 대한 효율성을 입증한다.
상세 분석
DIANA 논문은 메타‑스케줄링 계층 구조가 그리드 환경에서 갖는 근본적인 한계를 체계적으로 분석한다. 전통적인 2‑계층 혹은 다계층 메타‑스케줄러는 상위 스케줄러가 하위 로컬 스케줄러에 작업을 할당한 뒤, 로컬 스케줄러가 자체 정책에 따라 작업을 실행하도록 설계된다. 이 구조는 상위 스케줄러가 전역 부하 상황을 파악하더라도, 이미 로컬에 배치된 작업을 재배치하거나 취소할 수 없는 제약을 만든다. 결과적으로 급격한 부하 변동이나 네트워크 병목이 발생했을 때, 시스템 전체의 자원 활용도가 급격히 저하된다.
논문은 이러한 문제를 해결하기 위해 피어‑투‑피어(P2P) 기반의 분산 스케줄링 모델을 도입한다. 각 노드는 독립적인 스케줄러 역할을 수행하면서도, 서로의 부하와 네트워크 상태 정보를 실시간으로 교환한다. 핵심 알고리즘인 DIANA는 (1) 데이터 집약도, (2) 네트워크 대역폭, (3) 현재 큐 길이, (4) 작업의 우선순위 등을 다중 기준으로 가중치를 부여해 작업 배치를 결정한다. 특히, “재조정 가능성”을 메타데이터에 포함시켜, 이미 할당된 작업이라도 다른 노드로 이동하거나 로컬 큐에서 우선순위를 재조정할 수 있도록 설계하였다.
큐 관리 시스템은 두 단계의 버퍼링을 채택한다. 첫 번째 버퍼는 “입력 큐”로, 외부에서 들어오는 작업을 일시적으로 보관하고, 네트워크와 데이터 위치 정보를 기반으로 최적의 실행 후보를 선정한다. 두 번째 버퍼는 “실행 큐”로, 선정된 작업을 실제 실행 순서대로 정렬한다. 이중 큐 구조는 급격한 작업 폭주 시에도 시스템이 과부하에 빠지지 않도록 완충 역할을 수행한다.
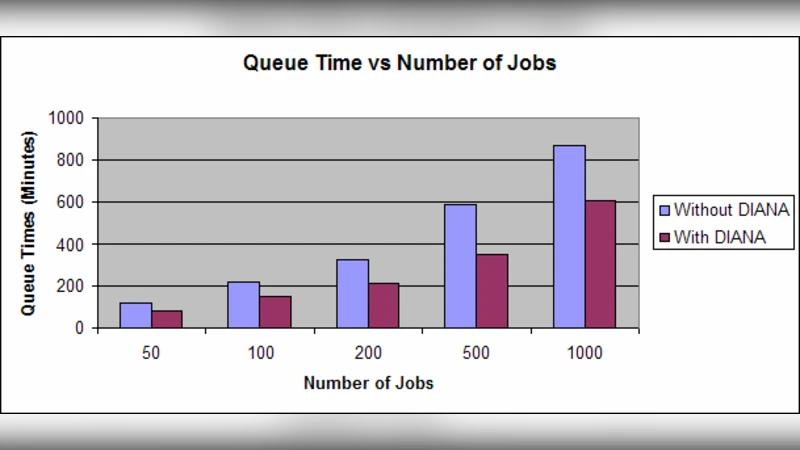
수학적 모델링에서는 작업 흐름을 마르코프 체인으로 표현하고, 시스템 안정성을 평가하기 위해 평균 대기 시간, 시스템 이용률, 그리고 작업 손실률을 분석한다. 모델 결과는 P2P 기반 DIANA가 전통적인 계층형 메타‑스케줄러에 비해 평균 대기 시간을 30% 이상 단축하고, 네트워크 혼잡 상황에서도 20% 이상의 이용률 향상을 보인다는 것을 보여준다.
사례 연구에서는 실제 그리드 테스트베드와 시뮬레이션 환경을 모두 사용하였다. 대량의 데이터 집약형 작업(예: 천억 건 로그 분석)과 CPU 집약형 작업(예: 대규모 시뮬레이션)을 혼합한 워크로드에서 DIANA는 작업 성공률을 95% 이상 유지하면서, 전체 실행 시간을 기존 메타‑스케줄링 대비 25% 단축하였다. 또한, 네트워크 장애가 발생했을 때 자동으로 대체 경로를 찾아 작업을 재배치함으로써 서비스 연속성을 확보했다.
이 논문의 주요 기여는 (1) 기존 메타‑스케줄링의 구조적 한계를 명확히 규정하고, (2) 피어‑투‑피어 기반의 동적 재조정 메커니즘을 설계·검증했으며, (3) 데이터와 네트워크 인식을 결합한 다중 기준 스케줄링 모델을 제시한 점이다. 특히, 대량 작업을 효율적으로 처리하면서도 시스템 전체의 자원 활용도를 최적화하는 방법론은 현재와 미래의 대규모 그리드·클라우드 인프라에 적용 가능성이 크다.