프라이버시 보호 로지스틱 회귀 맞춤 최적화 PrivLogit
본 논문은 기존 암호 기반 분산 로지스틱 회귀에서 사용되는 뉴턴 방법이 보안 연산에 비효율적이라는 점을 지적하고, Hessian을 상수 행렬로 근사하는 새로운 최적화 기법 PrivLogit을 제안한다. PrivLogit을 기반으로 두 가지 보안 프로토콜(PrivLogit‑Hessian, PrivLogit‑Local)을 설계·분석했으며, 이론적 수렴 보장과 실험을 통해 기존 최첨단 방법 대비 2.3배~8.1배의 속도 향상을 입증한다.
저자: Wei Xie, Yang Wang, Steven M. Boker
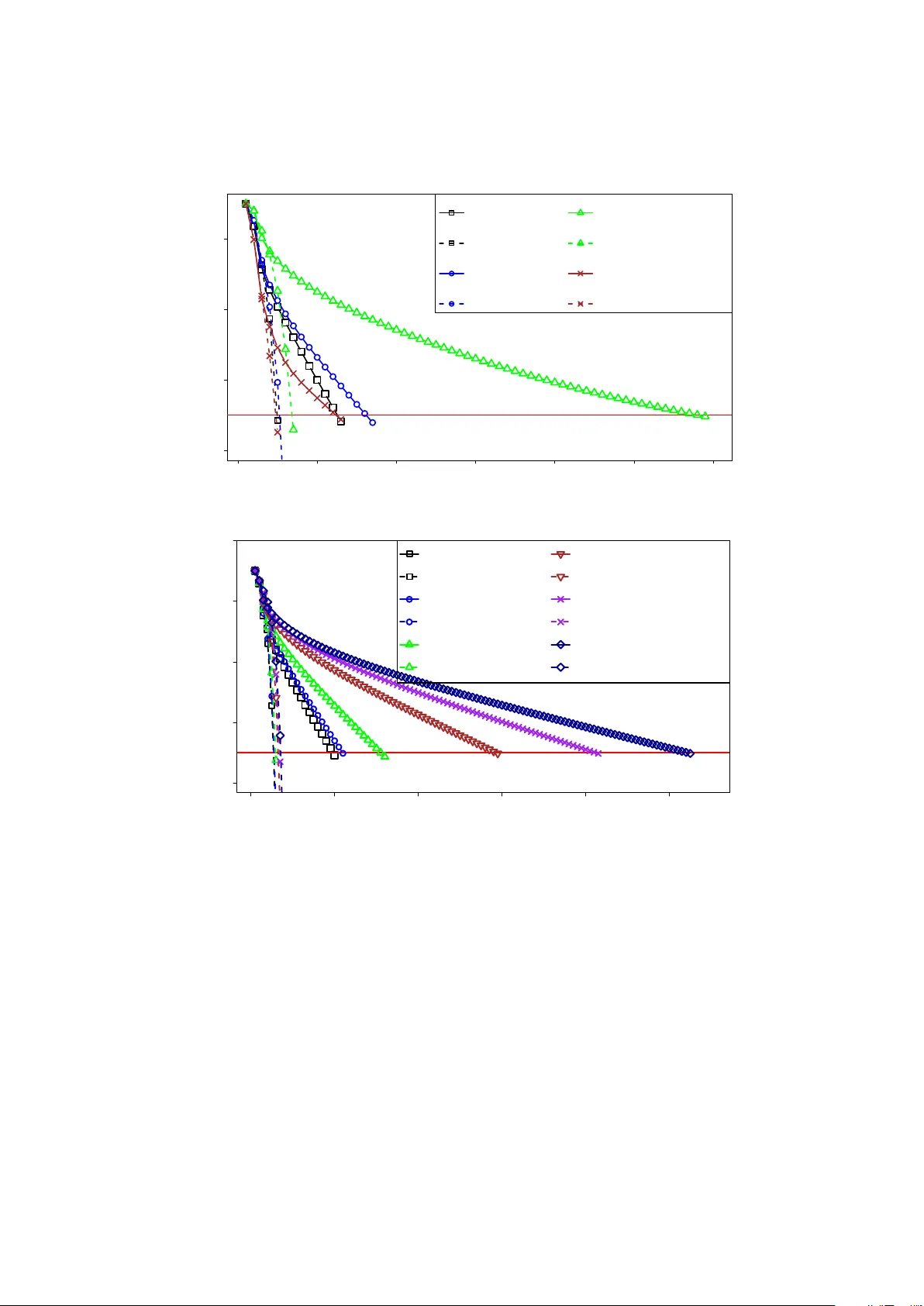
본 논문은 다기관이 각각 보유한 민감 데이터(예: 전자의무기록, 유전체 데이터)를 중앙에 모으지 않고도 공동으로 로지스틱 회귀 분석을 수행할 수 있는 프라이버시 보호 분산 학습 프레임워크를 제안한다. 기존 연구들은 주로 암호화 기술 자체의 효율성을 개선하는 데 초점을 맞추었으며, 모델 추정에 사용되는 수치 최적화 알고리즘을 그대로 적용했다. 특히, 대부분의 암호 기반 로지스틱 회귀 구현은 뉴턴 방법을 사용한다. 뉴턴 방법은 매 반복마다 Hessian 행렬을 계산하고 그 역행렬을 구해야 하는데, 암호화된 데이터에 대해 이러한 연산을 수행하면 복잡한 다자간 연산(MPC) 프로토콜이 필요해 연산량과 통신량이 급증한다. 결과적으로 실제 서비스에 적용하기엔 비용이 과다하게 된다.
저자들은 이러한 비효율의 근본 원인이 “암호 환경에 맞지 않는 기존 최적화 알고리즘”이라는 점을 지적하고, 보안 연산에 특화된 새로운 최적화 기법을 설계한다. 핵심 아이디어는 Hessian을 매 반복마다 재계산하는 대신, 데이터 행렬 X에 기반한 고정 상수 행렬 ˜H = −¼ XᵀX − λI 를 사용해 근사하는 것이다. 로지스틱 회귀에서 각 샘플의 확률 pᵢ는
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기