대규모 머신러닝 파이프라인을 위한 KeystoneML 최적화 시스템
초록
KeystoneML은 고수준 논리 연산자를 기반으로 머신러닝 파이프라인을 선언하고, 연산자별 비용 모델과 클러스터 자원 정보를 활용해 물리적 구현을 자동 선택·최적화한다. 전체 파이프라인 수준에서 중간 결과 물리화 전략을 결정함으로써 데이터 재사용을 극대화하고, 실제 이미지, 음성, 텍스트 워크로드에서 최대 15배의 학습 속도 향상을 달성한다.
상세 분석
본 논문은 머신러닝 파이프라인 최적화를 데이터베이스 쿼리 최적화와 유사한 프레임워크로 재구성한다는 점에서 혁신적이다. 첫 번째 핵심은 “Transformer”와 “Estimator”라는 두 종류의 고수준 연산자를 도입해 파이프라인을 선언적 DAG 형태로 표현한다는 점이다. Transformer는 입력 데이터를 변환하는 순수 함수이며, Estimator는 학습 과정을 수행해 Transformer를 반환한다. 이러한 구분은 연산자 재배치와 병렬 실행을 안전하게 허용한다.
두 번째 핵심은 연산자 수준 비용 모델이다. 각 물리적 구현은 실행 비용 c_exec와 조정 비용 c_coord을 함수 형태로 정의하고, 클러스터 자원 기술자(R_exec, R_coord)를 곱해 전체 비용을 추정한다. 여기서 입력 데이터의 희소도, 차원 수, 클래스 수 등 통계적 특성이 비용 함수에 직접 반영된다. 예컨대, 선형 솔버는 정확 해법, 블록 솔버, SGD·L‑BFGS 등 여러 구현을 제공하고, 비용 모델은 FLOP, 메모리, 네트워크 전송량을 기반으로 최적 구현을 선택한다.
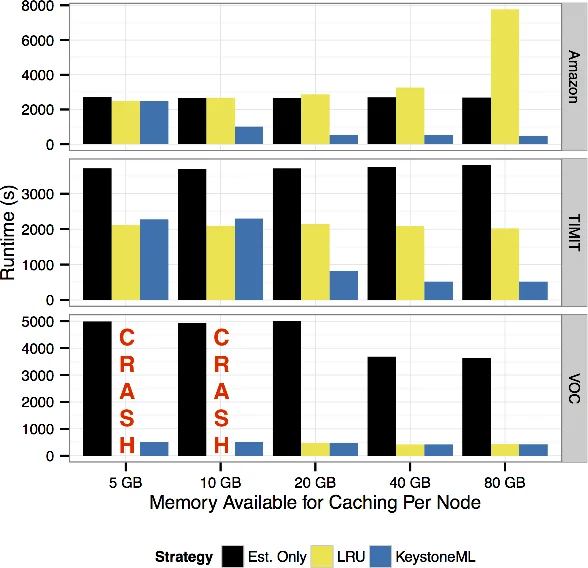
세 번째 혁신은 파이프라인 전체 최적화이다. 연산자 간 중간 결과를 메모리에 물리화할지 여부를 결정하는 문제를 “어떤 중간 데이터를 물리화할 것인가”라는 이진 선택 문제로 모델링하고, 비용 절감 효과가 큰 경우를 탐욕적으로 선택한다. 이 접근법은 반복적인 연산(예: PCA, 반복형 SGD)에서 데이터 재사용을 보장해 네트워크 I/O와 디스크 I/O를 크게 감소시킨다.
실험에서는 이미지 분류(1M 이미지), 음성 인식(phoneme classification), 텍스트 감성 분석 등 세 가지 도메인에서 KeystoneML을 적용했다. 특히 이미지 파이프라인에서는 15배 가량의 학습 속도 향상을 보였으며, 물리적 연산자 선택이 부적절할 경우 260배까지 성능 저하가 발생한다는 사실을 입증했다. 또한, 동일한 정확도를 유지하면서도 기존 특화 시스템 대비 8배 적은 자원으로 동일하거나 더 나은 성능을 달성했다.
전체적으로 KeystoneML은 고수준 선언형 API와 비용 기반 물리적 구현 선택, 파이프라인 전체 최적화를 결합해 대규모 분산 환경에서 머신러닝 파이프라인을 효율적으로 실행한다는 중요한 교훈을 제공한다. 향후 GPU·TPU와 같은 이종 하드웨어, 자동 하이퍼파라미터 튜닝과 결합한다면 더욱 강력한 엔드‑투‑엔드 ML 플랫폼으로 확장될 가능성이 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기