네트워크 분류를 위한 특징 기반 하이브리드 접근법
본 논문은 도메인 지식을 활용해 수동으로 선택한 네트워크 특징을 기반으로, 랜덤 포레스트와 같은 자동 분류기를 적용하는 하이브리드 방법을 제안한다. 전화 통화 기록, 암 전이 조절망, 그리고 공개 벤치마크 데이터를 대상으로 실험했으며, 기존 그래프 커널·딥러닝 기법보다 높은 정확도와 낮은 연산 비용, 그리고 결과 해석 용이성을 입증하였다.
저자: Ian Barnett, Nishant Malik, Marieke L. Kuijjer
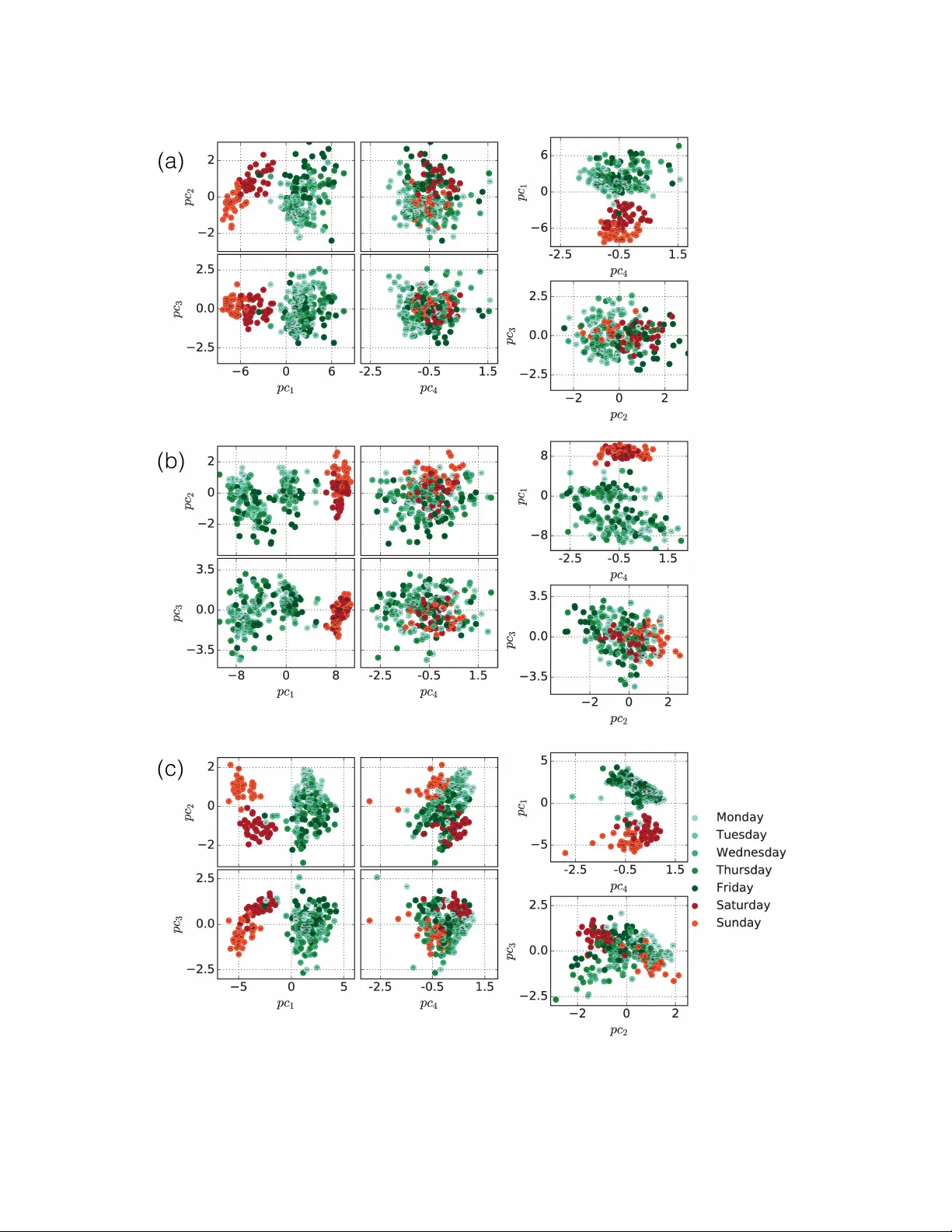
본 논문은 다양한 과학·사회 분야에서 관측되는 복합 네트워크가 완전한 무작위성이나 완전한 규칙성을 갖지 않고, 반복적으로 나타나는 구조적 빌딩 블록을 포함한다는 전제에서 출발한다. 이러한 구조적 특징은 동일한 대분류(예: 사회 네트워크, 생물학 네트워크)에 속하는 네트워크 간에 공유되며, 더 세분화된 하위 클래스에서는 시스템의 목적·구조가 유사할수록 특징도 유사하게 나타난다. 저자들은 이러한 특징을 활용해 네트워크를 자동·수동 방식으로 분류하는 기존 연구들을 검토하고, 두 접근법의 장단점을 종합한 ‘하이브리드’ 방법을 제안한다.
핵심 절차는 두 단계로 구성된다. 첫 번째 단계에서는 연구자가 도메인 지식에 기반해 네트워크의 구조적·속성적 특징을 직접 선정한다. 여기에는 전통적인 그래프 지표(평균 차수, 전역 클러스터링 계수, 차수 상관성, 네트워크 규모)뿐만 아니라, 데이터 특성에 맞춘 맞춤형 피처(예: 성별·연령·우편번호 기반 연결 비율, 전사인자‑유전자 조절 강도 등)가 포함된다. 두 번째 단계에서는 이렇게 정의된 피처 벡터를 입력으로 머신러닝 분류기를 학습시킨다. 저자는 k‑means, k‑nearest‑neighbors(KNN), 그리고 랜덤 포레스트(Random Forest) 세 가지 방법을 비교했으며, 특히 랜덤 포레스트가 피처 간 다중공선성을 효과적으로 다루고, 피처 중요도 평가를 제공함으로써 해석 가능성을 크게 향상시킨다.
실험은 세 종류의 네트워크에 대해 수행되었다. 첫 번째는 2014년 3분기 동안 유럽 국가의 주요 통신 사업자에서 수집한 통화·문자 기록을 일별로 집계한 무방향 소셜 네트워크이다. 각 일별 네트워크는 전화 통화·문자 교환 관계를 기반으로 구축되었으며, 저자들은 이 네트워크를 요일(월~일) 혹은 주말/주중으로 분류하였다. 결과는 모든 분류기가 95% 이상의 정확도를 보였으며, 랜덤 포레스트에서는 ‘같은 우편번호 내 연결 비율’이 가장 중요한 피처로 나타났다(전체 평균 피처 대비 4.5배 중요). 주말에는 같은 지역 내 연결 비율이 증가하고, 네트워크 규모와 평균 연령 차이도 변동하여 모델이 이를 효과적으로 포착했다.
두 번째 실험은 암 환자 샘플에서 추정한 전사인자‑유전자 조절망(이중 네트워크)이다. 각 샘플은 113개의 전사인자와 10,903개의 유전자로 구성되며, 전사인자와 유전자 사이의 조절 강도를 가중치로 갖는다. 폐암, 뇌암, 난소암 세 종류의 종양을 구분하는 과제로, 랜덤 포레스트는 68%의 정확도를 기록했으며, KNN은 62%에 그쳤다. 여기서 가장 중요한 피처는 유전자‑유전자 투영망의 차수 상관성이었으며, 전체 피처가 비교적 고르게 기여하는 형태를 보였다. 이는 종양 유형 간 구조적 차이가 미세하고 선형적으로 구분되지 않기 때문에, 복잡한 비선형 경계가 가능한 랜덤 포레스트가 유리함을 시사한다.
세 번째 실험은 공개된 네트워크 분류 벤치마크(포럼 기반 에고‑소셜 네트워크, IMDb 기반 연기자‑영화 네트워크 등) 여섯 개를 대상으로 수행되었다. 여기서는 동일한 피처 집합(주요 그래프 지표)만을 사용했으며, 랜덤 포레스트가 KNN·k‑means보다 평균 3% 높은 정확도를 보였다. 특히, 최근 제안된 그래프 커널, 딥 그래프 커널, 그래프 CNN 등 복잡하고 연산 비용이 큰 방법들과 비교했을 때, 피처 기반 랜덤 포레스트가 동일하거나 더 높은 성능을 내면서 학습·예측 시간이 크게 단축되었다.
논문은 또한 피처 선택이 데이터셋마다 달라야 함을 강조한다. 사회 네트워크에서는 지리·인구통계적 속성이 핵심이지만, 생물학적 네트워크에서는 투영망 구조가 더 중요한 경우가 많다. 이러한 유연성은 도메인 전문가가 사전 지식을 반영해 피처 풀을 확장·조정할 수 있게 하며, 자동 피처 추출에 비해 결과 해석이 용이하다는 장점을 제공한다. 랜덤 포레스트가 제공하는 피처 중요도 순위는 모델이 특정 클래스로 예측한 이유를 설명하고, 라벨 오류나 이상치를 탐지하는 데도 활용될 수 있다(예: 폐암 샘플이 난소암 군에 잘못 분류된 사례).
결론적으로, 저자들은 ‘수동 피처 선택 + 자동 분류’라는 하이브리드 접근법이 네트워크 분류에서 높은 정확도, 낮은 연산 비용, 그리고 뛰어난 해석 가능성을 동시에 달성한다는 점을 실증하였다. 이는 네트워크 과학·사회·생물학 분야에서 도메인 지식을 효과적으로 활용하면서도 최신 머신러닝 기법의 장점을 살릴 수 있는 실용적인 프레임워크로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기