온라인 학습 활동 동역학을 위한 계층적 디리클레 호크스 프로세스
본 논문은 사용자별 연속시간 스트리밍 데이터를 클러스터링하기 위해 계층적 디리클레 과정과 호크스 프로세스를 결합한 HDHP 모델을 제안한다. 학습 패턴을 무한히 확장 가능한 토픽으로 정의하고, 각 사용자의 행동 시계열을 다변량 호크스 프로세스로 모델링한다. 효율적인 순차적 몬테카를로 추론을 통해 수백만 건의 로그 데이터를 처리할 수 있으며, Stack Overflow 데이터 실험에서 내용·시간 양면에서 의미 있는 학습 패턴을 발견하고 사용자 관…
저자: Charalampos Mavroforakis, Isabel Valera, Manuel Gomez Rodriguez
1. 서론
온라인 학습이 일상화됨에 따라 사용자는 위키, Q&A 사이트, 블로그 등 다양한 웹 자원을 순차적으로 탐색한다. 이러한 행동은 목표 지향적이며, 동일한 목표를 가진 사용자는 유사한 행동 시퀀스를 보인다. 저자는 이러한 “학습 패턴”을 자동으로 추출하고, 시간에 따른 사용자의 관심 변화를 추적하기 위해 새로운 확률 모델을 제안한다.
2. 관련 연구
그룹 데이터 클러스터링에서는 LDA와 HDP가 주류를 이루지만, 시간 정보를 고려하지 못한다. 반면, 스트리밍 데이터 클러스터링은 Hawkes 기반 모델이 주를 이루지만, 단일 스트림에 한정된다. 최근 제안된 Dirichlet Hawkes Process(DHP)는 시간·클러스터링을 결합했지만, 비모수 사전이 없고 사용자 간 공유 클러스터를 지원하지 않는다. 따라서 그룹화된 연속시간 스트리밍 데이터를 다루는 모델은 아직 부재하다.
3. 사전 지식
3.1 계층적 디리클레 과정(HDP) – 무한 클러스터를 정의하고, 각 그룹(사용자)마다 독립적인 디리클레 프로세스를 샘플링하되, 전체 클러스터 집합을 공유한다. CRFP(Chinese Restaurant Franchise Process) 표현을 통해 직관적인 샘플링 및 추론이 가능하다.
3.2 호크스 프로세스 – 자기흥분(point self‑excitation) 특성을 갖는 시계열 모델로, λ(t)=μ+∑κ(t,t_i) 형태의 강도 함수를 사용한다. 급격한 버스트와 장기간 침묵을 자연스럽게 모델링한다.
4. 모델 설계 – HDHP
- 상위 레이어: DP(β, H)에서 학습 패턴 π와 파라미터 ϕ={α,θ}를 샘플링한다. π는 stick‑breaking으로 무한히 확장 가능하며, 각 패턴의 인기도를 나타낸다.
- 하위 레이어: 각 사용자 u는 다변량 호크스 프로세스를 갖는다. 차원 ℓ에 대응하는 강도 λ*u,ℓ(t)=μ_u π_ℓ + ∑_{t_j∈H_u(t),p_j=ℓ}α_ℓ exp(−ν(t−t_j)). 여기서 μ_u는 사용자의 신규 작업 시작 속도, α_ℓ는 패턴별 자기흥분 정도, ν는 감쇠율이다.
- 콘텐츠 모델: 행동 e=(t,ω,p)에서 ω는 패턴 p의 단어 분포 θ_p를 따르는 다항분포에서 샘플링한다.
5. 추론 알고리즘
시간 순서대로 도착하는 이벤트에 대해 파티클 필터링을 적용한다. 각 파티클은 (a) 새로운 작업(패턴) 시작 여부, (b) 기존 패턴에 대한 팔로업 여부를 샘플링하고, (c) 파라미터(μ_u,π,α,θ)는 베이지안 사후 업데이트를 통해 추정한다. 가중치는 로그우도 L_T=∑logλ*(t_i)−∫λ*(τ)dτ 로 계산한다. 이 방식은 메모리 사용량을 O(#파티클)로 제한하면서도 대규모 데이터에 적용 가능하다.
6. 실험
데이터: Stack Overflow에서 4년간 1.6 M 질문·답변, 16 K 사용자.
비교 모델: (i) HDP 기반 토픽 모델, (ii) DHP, (iii) 베이스라인 LDA.
평가 지표: 퍼플렉시티, 로그우도, 사용자 관심 예측 정확도(AUC).
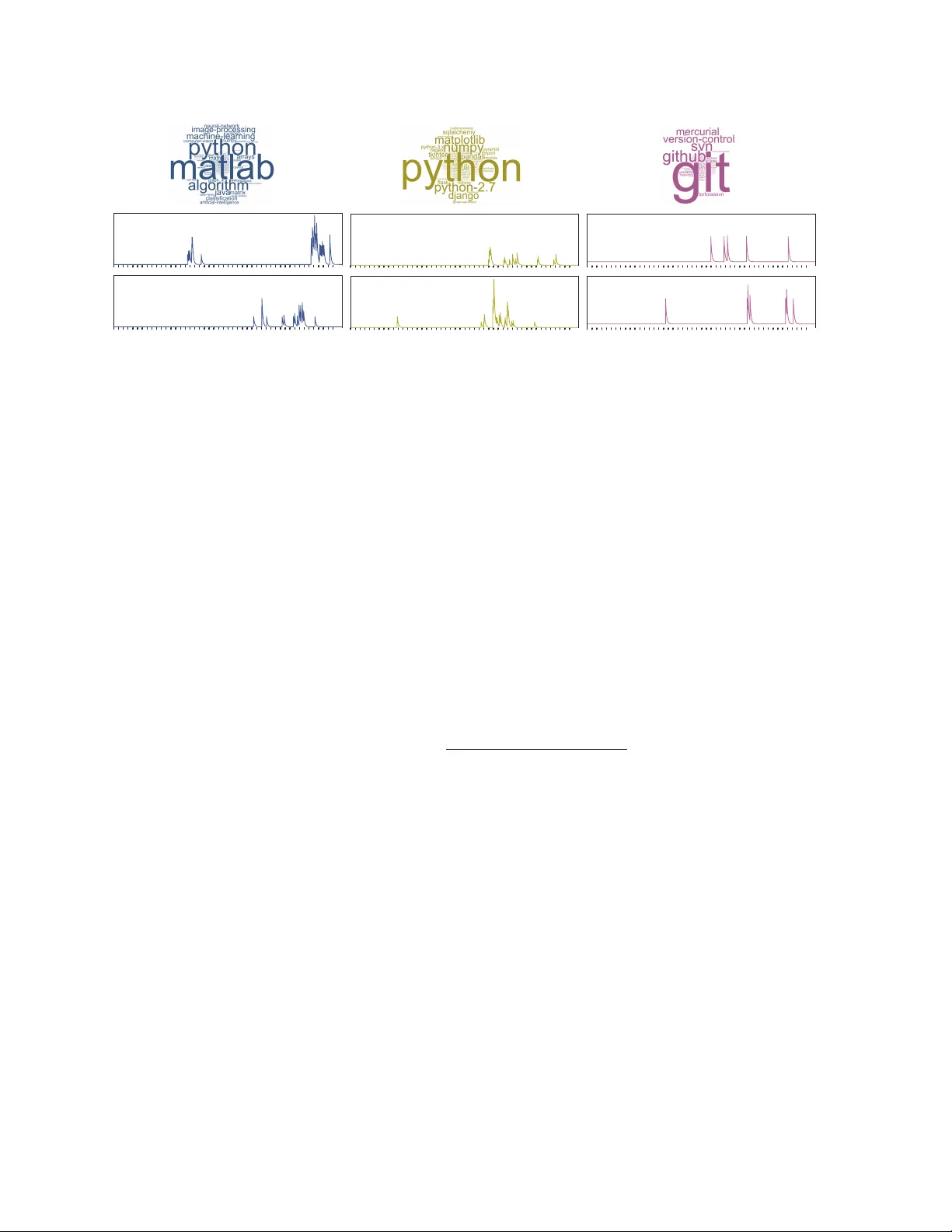
결과: HDHP는 퍼플렉시티 20 % 개선, 로그우도 유의하게 상승, 사용자별 관심 변화를 시계열적으로 정확히 포착. 학습 패턴별 단어 클라우드는 실제 프로그래밍 분야와 일치했으며, α 값이 높은 패턴은 새로운 기술 발표 시 급증하는 질문 버스트와 강하게 연관됨을 확인했다.
7. 논의 및 한계
- 현재는 지수형 커널만 사용해 복잡한 감쇠 형태를 표현하기 어려움.
- 패턴 인기도 π가 시간에 따라 고정돼 있어 장기 트렌드 변화를 반영하지 못함.
- 파티클 수에 따라 추론 정확도가 달라지므로, 실시간 시스템에서는 적절한 트레이드오프가 필요함.
8. 결론 및 향후 연구
HDHP는 그룹화된 연속시간 스트리밍 데이터를 동시에 클러스터링하고, 시간적 자기흥분을 모델링함으로써 온라인 학습 활동을 정교하게 분석한다. 향후에는 가변형 커널, 동적 π 모델, 그리고 멀티모달(텍스트·코드·이미지) 확장을 통해 더욱 풍부한 학습 행동 분석이 가능할 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기