노이즈 환경에서 강인한 음성 인식을 위한 초심층 합성곱 신경망
초록
본 논문은 Aurora 4 잡음 데이터베이스를 대상으로, 필터·풀링 크기를 축소하고 입력 특성 맵을 확대하여 10층 이상의 합성곱 층을 쌓은 초심층 CNN(VDCNN)을 설계한다. 패딩, 시간·주파수 풀링, 입력 맵 선택, i‑vector·fMLLR 보조 특성의 공동 학습, 그리고 LSTM‑RNN과의 점수 결합 등 여러 최적화 기법을 적용해 기존 CNN 대비 WER를 8.81 %→7.09 %까지 낮춘다.
상세 분석
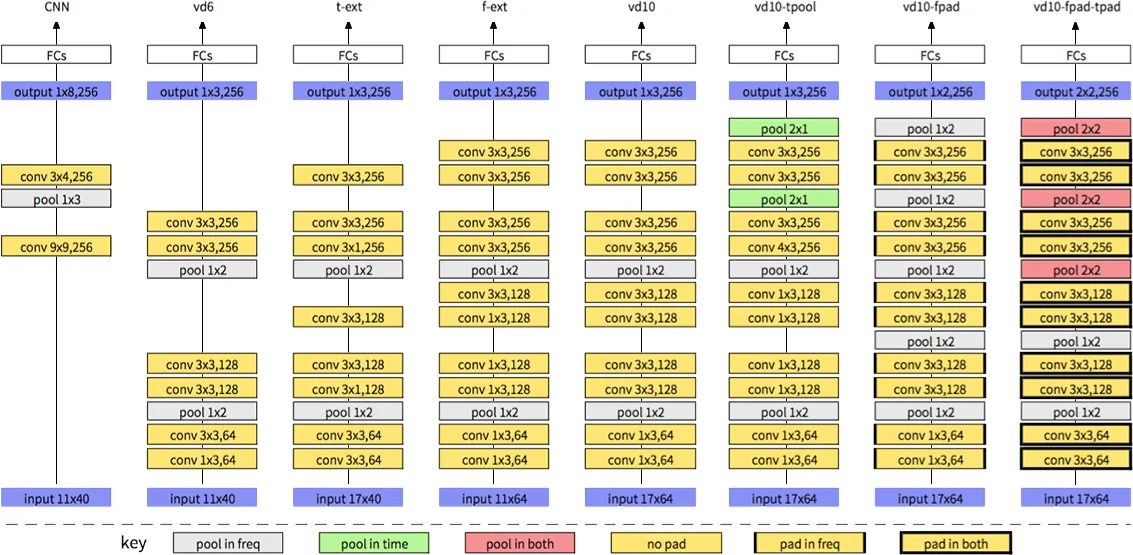
이 연구는 기존 음성 인식용 CNN이 2~3개의 합성곱 층에 머무는 한계를 인식하고, 컴퓨터 비전 분야에서 성공한 ‘very deep’ 설계를 음성 영역에 맞게 변형한다는 점에서 의미가 크다. 첫 번째 핵심은 필터와 풀링 크기를 3×3, 1×2 혹은 2×2로 최소화함으로써 층 수를 늘릴 수 있는 여지를 만든 것이다. 작은 필터는 국소적인 시간‑주파수 패턴을 세밀하게 포착하고, 비중첩 풀링은 정보 손실을 최소화한다. 두 번째로 입력 특성 맵의 차원을 확대한다. 기존 11×40(FBANK + Δ + ΔΔ) 대신 17×64로 확장함으로써 더 많은 합성곱·풀링 연산을 수행할 수 있게 되었으며, 이는 ‘시간‑주파수 확장(t‑ext, f‑ext)’ 실험에서 WER 감소로 검증된다.
패딩 전략도 중요한 역할을 한다. 기존 음성 CNN은 경계 패딩 없이 합성곱을 수행했지만, 본 논문은 주파수 방향에만 패딩을 적용한 vd10‑fpad, 시간·주파수 모두에 패딩을 적용한 vd10‑fpad‑tpad을 실험한다. 패딩을 통해 특성 맵 크기가 유지되어 더 깊은 네트워크 설계가 가능해졌으며, 특히 두 축 모두에 패딩을 적용했을 때 8.81 %→7.27 % 수준의 추가 개선이 관찰된다.
입력 특성 맵 수에 관한 실험에서는 정적 FBANK 하나만을 사용한 VDCNN이, 전통적으로 사용되는 정적+Δ+ΔΔ 3채널보다 우수한 성능을 보였다. 이는 매우 깊은 네트워크가 원시 스펙트럼 정보를 충분히 학습할 수 있음을 시사한다.
보조 특성(i‑vector, fMLLR)과의 공동 학습은 적응 프레임워크를 제공한다. 보조 특성을 별도 전처리 네트워크로 인코딩한 뒤, 중간 레이어에서 결합함으로써 잡음·채널 변이에 대한 강인성을 더욱 강화한다. 이 방식을 적용한 모델은 WER 7.99 %를 달성, 단순 VDCNN 대비 0.8 %p 정도의 추가 이득을 제공한다.
마지막으로 LSTM‑RNN과의 점수 결합은 서로 다른 모델링 강점을 상보적으로 활용한다. VDCNN은 고정‑길이 프레임 기반의 강력한 로컬 패턴 인식을, LSTM‑RNN은 장기 의존성 모델링을 담당한다. 두 모델의 상태‑레벨 가중 로그우도 점수를 결합한 ‘joint decoding’은 최종적으로 7.09 % WER를 기록, 기존 최첨단 시스템 대비 약 15 % 이상의 상대적 개선을 이루었다.
전체적으로 본 논문은 (1) 필터·풀링 최소화, (2) 입력 차원 확대, (3) 적절한 패딩 적용, (4) 보조 특성 공동 학습, (5) LSTM‑RNN과의 점수 결합이라는 다섯 축을 통해 초심층 CNN을 잡음 환경에 최적화하는 방법론을 체계적으로 제시한다. 실험 결과는 Aurora 4라는 표준 벤치마크에서 일관된 성능 향상을 보여, 향후 실시간·저전력 음성 인식 시스템에 적용 가능한 설계 지침을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기