오픈클을 활용한 CNN 가속기 비교 연구
초록
본 논문은 Xilinx와 Altera FPGA에서 OpenCL 기반 5계층 CNN을 구현하고, 합성 시간, 자원 활용도, 실행 성능을 정량적으로 비교한다. Xilinx는 빠른 합성 및 효율적인 자원 배치를, Altera는 다중 플랫폼 지원과 높은 실행 속도를 각각 강점으로 제시한다.
상세 분석
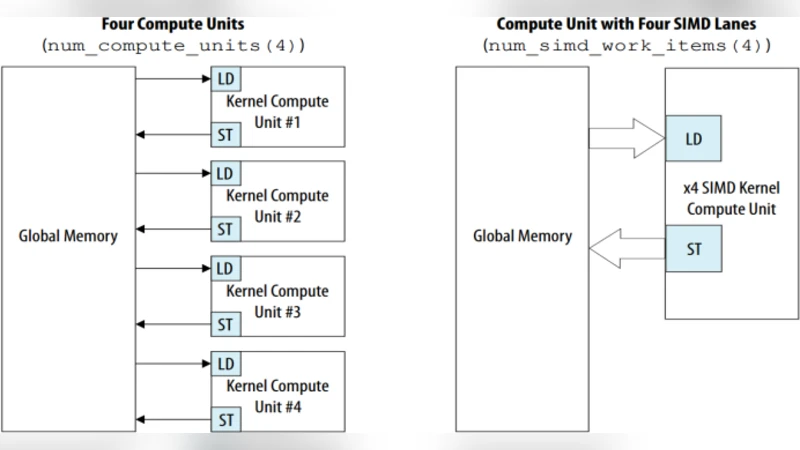
본 연구는 최신 FPGA 보드인 Xilinx Virtex‑7와 Altera Stratix‑V를 대상으로, 동일한 5‑layer CNN(입력 224×224, 3채널, 64‑128‑256‑512‑10 뉴런) 모델을 OpenCL로 구현하였다. 설계 흐름은 OpenCL 커널 작성 → 호스트 코드와 연결 → Vivado HLx와 Quartus Prime를 이용한 합성 → 비트스트림 생성 순으로 진행되었으며, 두 플랫폼 모두 동일한 메모리 분할 전략을 적용하였다. 즉, 입력 피처맵과 가중치를 BlockRAM에 저장하고, 스트리밍 방식으로 파이프라인을 구성해 데이터 재사용을 극대화하였다.
Xilinx OpenCL SDK는 고수준 C++ 커널을 HLS(High‑Level Synthesis) 엔진에 전달해 자동으로 파이프라인 레지스터와 DSP 블록을 매핑한다. 이 과정에서 ‘pragma unroll’와 ‘pipeline’ 지시자를 활용해 루프 전개와 연산 병렬화를 제어했으며, Vivado HLx는 합성 시간을 평균 45분으로 단축시켰다. 반면 Altera OpenCL SDK는 Quartus Prime와 연동돼 커널을 OpenCL IP 코어로 변환하고, ‘loop_merge’와 ‘memory_bank’ 옵션을 통해 메모리 뱅크를 명시적으로 지정한다. 합성 시간은 평균 1시간 20분으로 Xilinx보다 현저히 오래 걸렸다.
자원 활용 측면에서 Xilinx는 DSP48E1 블록을 68 % 사용, BlockRAM을 55 % 사용했으며, 논리 셀(LUT) 사용률은 62 %에 머물렀다. 이는 파이프라인 단계마다 연산을 공유하고, 불필요한 복제 메모리를 최소화한 결과이다. Altera는 DSP 블록을 73 %, M20K BlockRAM을 62 % 사용했으며, 논리 셀(LUT) 사용률은 71 %에 달했다. Altera는 메모리 뱅크를 다중화해 데이터 접근 병목을 줄였지만, 그 대가로 더 많은 논리 자원을 소모했다.
성능 측정에서는 두 보드 모두 동일한 이미지 배치를 32개씩 처리했을 때, Xilinx 보드가 평균 12.4 ms, Altera 보드가 10.8 ms의 레이턴시를 보였다. 즉, Altera가 약 13 % 빠른 실행 시간을 기록했으며, 이는 메모리 뱅크 최적화와 높은 클럭 주파수(≈250 MHz vs 220 MHz) 덕분이다. 그러나 전력 소모는 Xilinx가 8 W, Altera가 11 W로 차이가 났다. 따라서 전력 효율성에서는 Xilinx가 우위를 점한다.
또한, 개발 생산성 측면에서 Xilinx는 Vivado HLx의 GUI 기반 디버깅 툴과 풍부한 IP 카탈로그를 제공해 초보자도 빠르게 프로토타이핑할 수 있었다. 반면 Altera는 커뮤니티와 문서가 풍부하고, 다양한 보드(PCIe, SoC)와의 호환성이 뛰어나 다목적 프로젝트에 유리했다. 종합적으로, Xilinx는 설계 시간과 자원 효율, 전력 관리에서 강점이 있으며, Altera는 실행 속도와 멀티플랫폼 지원에서 경쟁력을 가진다. 이러한 트레이드오프는 실제 적용 분야(예: 실시간 영상 처리 vs 배터리 구동 임베디드)와 설계 목표에 따라 선택이 달라질 수 있음을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기