짧은 발화 화자 인식을 위한 시스템 결합
초록
본 논문은 텍스트 독립 짧은 발화 화자 인식(SUSR)에서 성능 저하를 극복하기 위해 두 개의 음소 인식 기반 시스템을 결합한다. 하나는 DNN 기반 i‑vector 모델이며, 다른 하나는 서브리전 기반 GMM‑UBM 모델이다. 두 시스템은 각각 음소 후처리 정보를 활용해 통계량을 강화하거나 음소별 GMM을 구축함으로써 짧은 테스트 발화에 대한 강인성을 높인다. 최종적으로 점수 수준에서 선형 가중 평균을 수행해 두 모델의 장점을 통합했으며, 실험 결과 EER를 28.97%에서 17.43%로 크게 감소시켰다.
상세 분석
본 연구는 짧은 발화(0.5~2초) 상황에서 텍스트 독립 화자 인식의 근본적인 문제를 ‘음소 인식 기반(phonetic‑aware)’ 접근법으로 재정의한다. 기존 GMM‑UBM은 전체 음향 공간을 하나의 확률 모델로 취급해 짧은 테스트 발화가 전체 Gaussian 구성요소를 충분히 커버하지 못하면 likelihood가 편향된다. 반면 i‑vector는 모든 Gaussian이 공유하는 저차원 잠재 변수(T‑matrix)를 통해 통계량을 압축하지만, 짧은 발화에서는 Baum‑Welch 통계가 불안정해 i‑vector 추정이 부정확해진다. 이를 보완하기 위해 두 가지 음소 인식 기반 모델을 도입한다.
첫 번째는 DNN 기반 i‑vector 모델이다. 대규모 ASR용 DNN을 학습시켜 senone(음소 상태) posterior를 얻고, 이를 기존 GMM‑UBM의 posterior 대신 사용해 Baum‑Welch 통계와 T‑matrix를 계산한다. 이렇게 하면 각 Gaussian이 특정 음소와 연관되며, 음소별 데이터 분포를 반영한 통계가 공유 잠재 변수에 축적돼 짧은 발화에서도 보다 견고한 i‑vector를 생성한다.
두 번째는 서브리전 기반 GMM‑UBM 모델이다. 음소(또는 최종음) 단위로 음향 공간을 서브리전으로 분할하고, 각 서브리전에 다중 Gaussian을 학습한다. 여기서는 ASR 정렬 결과를 이용해 각 프레임이 어느 서브리전에 속하는지를 결정하고, 해당 서브리전의 posterior P(c|x_t)를 사용해 likelihood를 계산한다. 서브리전마다 독립적인 speaker‑dependent GMM을 구축함으로써 음소별 세부 특성을 더 정밀하게 포착한다. 특히 중국어의 ‘Initial‑Final’ 구조를 고려해 Final을 K‑means로 군집(C=6)하고, 각 군집을 서브리전으로 삼아 모델 복잡도와 데이터 희소성 사이의 균형을 맞춘다.
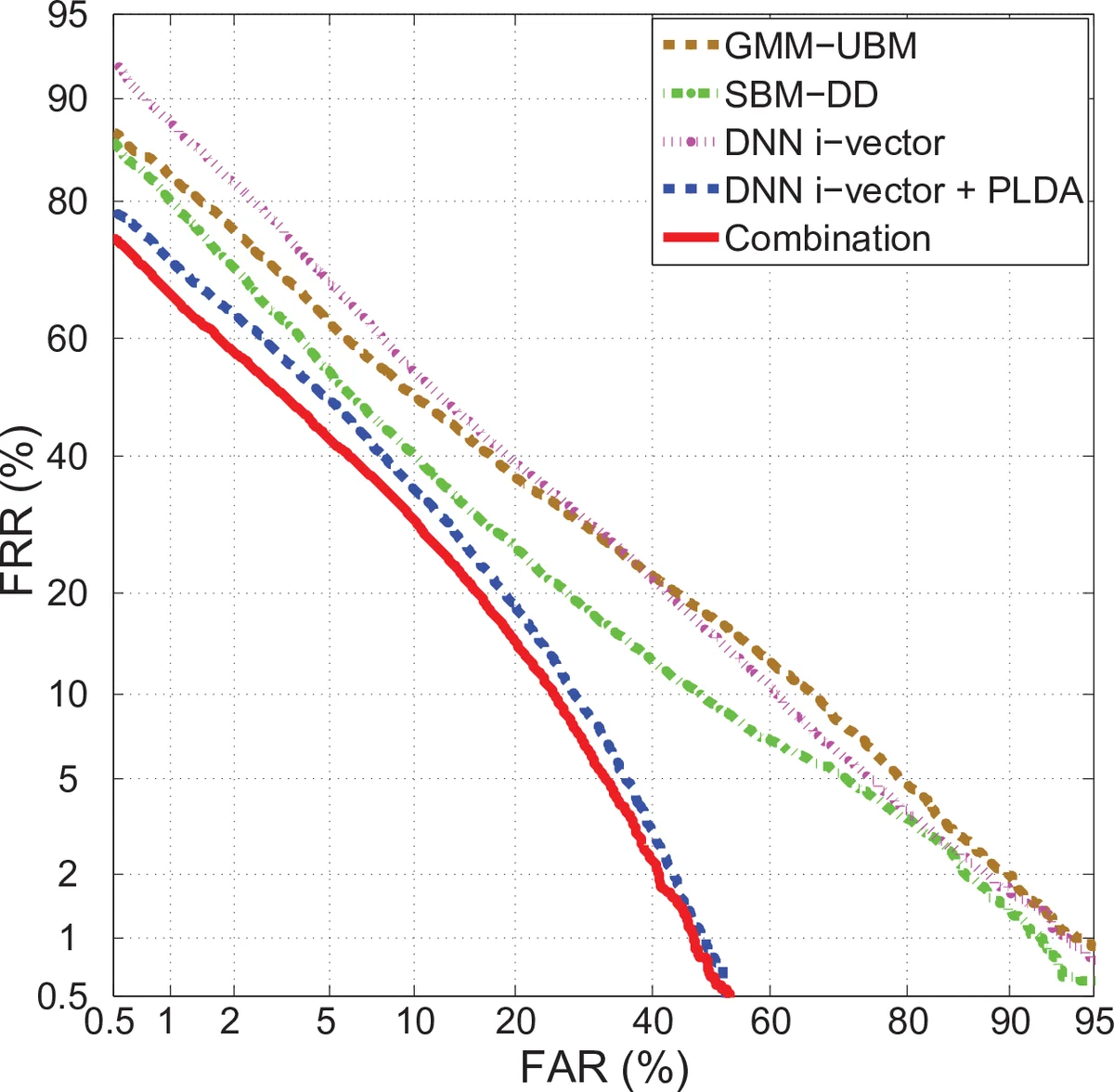
두 모델은 서로 보완적인 특성을 가진다. 서브리전 모델은 음소별 상세 정보를 제공해 짧은 구간에서도 의미 있는 likelihood를 산출하지만, 서브리전 간 독립성으로 인해 전체 발화에 대한 전역적 강인성은 다소 부족할 수 있다. 반면 DNN‑i‑vector는 전역적인 저차원 표현을 공유함으로써 통계적 안정성을 확보하지만, 음소별 미세 차이는 희생한다. 따라서 점수 수준에서 선형 가중 평균(s_comb = α·s_i‑vector + (1‑α)·s_subregion)으로 결합하면 두 장점이 시너지 효과를 낸다. 실험에서는 α=0.94가 최적으로 나타났으며, 이는 i‑vector 점수가 주도적이지만 서브리전 점수의 작은 기여가 전체 성능을 크게 향상시킴을 의미한다.
실험 설정은 자체 구축한 SUD12 데이터베이스(56명, 0.5~2초 짧은 발화)와 863DB(17시간)로 UBM 및 T‑matrix를 학습한 뒤, Kaldi 기반 MFCC와 VAD를 사용했다. Baseline으로는 1024‑component GMM‑UBM와 전통적인 GMM‑i‑vector(400 차원) 시스템을 사용했으며, PLDA 적용 후 DNN‑i‑vector는 EER 19.16%를 기록했다. 서브리전 모델은 22.74%의 EER를 보였고, 두 시스템을 결합한 최종 모델은 17.43%로 가장 낮았다. 이는 짧은 발화 상황에서 음소 정보를 활용한 두 모델의 결합이 기존 방법보다 현저히 우수함을 입증한다.
본 논문의 주요 기여는 (1) 짧은 발화에 특화된 두 종류의 phonetic‑aware 모델을 제안하고, (2) 이들을 점수 수준에서 효과적으로 결합하는 방법을 제시했으며, (3) 실제 짧은 발화 데이터베이스에서 실증적인 성능 향상을 입증했다는 점이다. 향후 연구에서는 더 정교한 음소 군집화, 다중 언어 확장, 그리고 end‑to‑end 딥러닝 기반 결합 전략을 탐색함으로써 실시간 응용 및 포렌식 분야에의 적용 가능성을 높일 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기