피드포워드 네트워크와 주의 메커니즘으로 장기 기억 문제 해결
초록
본 논문은 순환 구조 없이도 입력 시퀀스 전체에 대한 가중 평균을 계산하는 단순화된 어텐션을 도입해, 길이가 10 000까지 변동하는 합산·곱셈 태스크를 빠르게 학습시킬 수 있음을 보인다. 모델은 완전 병렬화가 가능하며, 가중 어텐션이 무가중 평균보다 뛰어난 성능을 나타낸다.
상세 분석
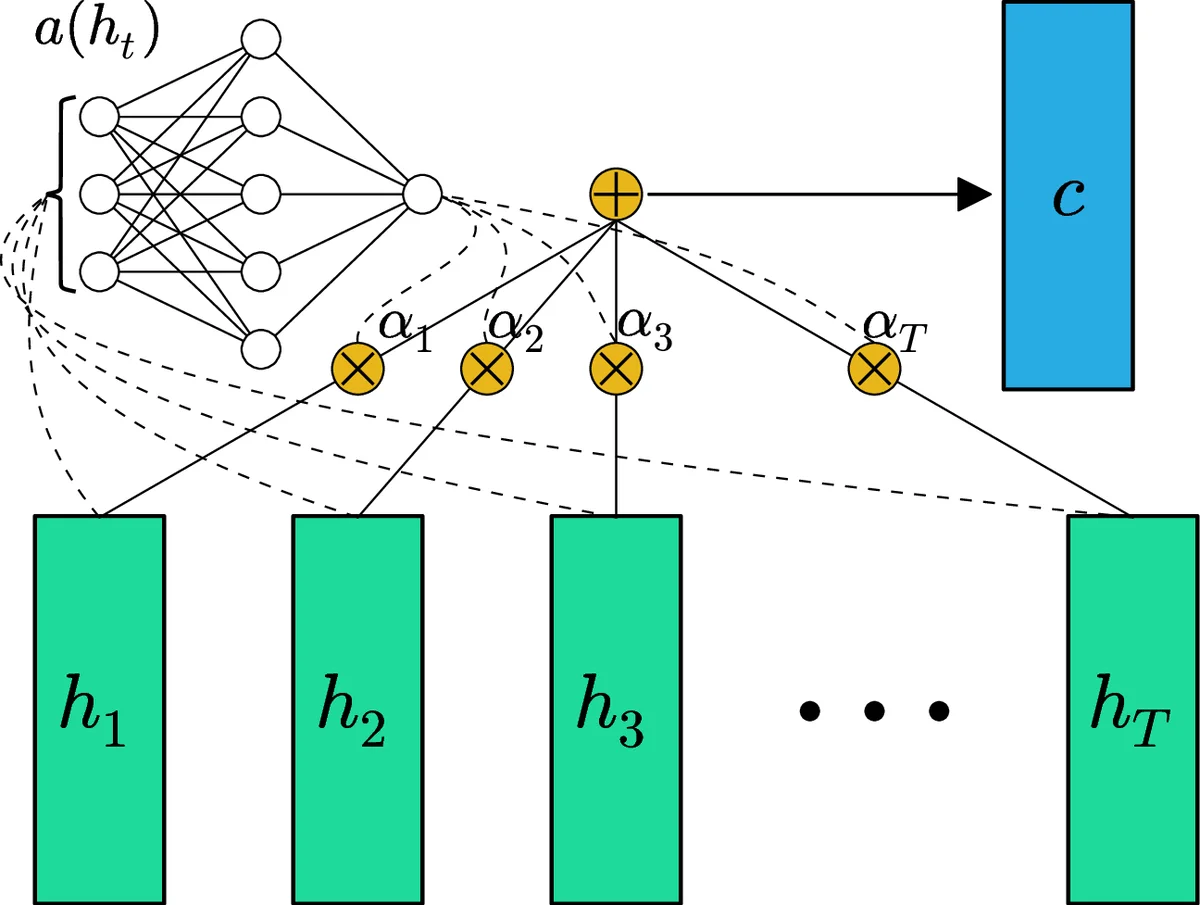
이 연구는 기존 RNN이 겪는 기울기 소실·폭발 문제와 순차적 연산의 비병렬성을 극복하고자, “feed‑forward attention”이라는 새로운 구조를 제안한다. 입력 시퀀스 xₜ에 대해 단순히 선형 변환 후 Leaky‑ReLU 활성화로 은닉 표현 hₜ = LReLU(Wₓₕxₜ + bₓₕ)를 만든 뒤, 각 hₜ에 대해 스칼라 점수 eₜ = a(hₜ) = tanh(Wₕc hₜ + bₕc)를 계산한다. 소프트맥스 정규화를 통해 αₜ = exp(eₜ)/∑ₖexp(eₖ)를 얻고, 전체 시퀀스에 대한 컨텍스트 벡터 c = Σₜ αₜ hₜ를 정의한다. 이 과정은 순전파 단계에서 완전 병렬화가 가능하므로 GPU 가속 효율이 높다.
c를 얻은 뒤, 또 다른 선형 변환과 Leaky‑ReLU를 거쳐 중간 벡터 s = LReLU(W_cs c + b_cs)를 만들고, 최종 출력 y = LReLU(W_sy s + b_sy)로 매핑한다. 차원 D는 100으로 고정했으며, 모든 가중치는 정규분포(σ = 1/√N)로 초기화하고, 편향은 0으로 시작한다. 최적화는 Adam(β₁=0.9, β₂=0.999)으로 수행했으며, 배치 크기는 100, 학습은 최대 100 epoch 또는 100 % 정확도 달성 시 종료한다.
실험은 두 가지 합성 장기 기억 태스크(‘addition’과 ‘multiplication’)에 대해 수행되었다. 고정 길이 실험에서는 T₀ ∈ {50, 100, 500, 1 000, 5 000, 10 000} 범위의 시퀀스를 사용했으며, 어텐션 기반 모델은 모든 길이에서 100 % 정확도에 도달하거나 100 epoch 내에 99 % 이상을 기록했다. 무가중 평균(단순 평균) 버전은 긴 시퀀스에서 급격히 성능이 떨어졌다. 또한, 동일한 하드웨어(NVIDIA GTX 980Ti)에서 10 000 길이 시퀀스 100 000개를 1 epoch 학습하는 데 254 초가 소요된 반면, 동일 파라미터 규모의 vanilla RNN은 917 초가 걸렸다.
가변 길이 실험에서는 길이 50~10 000 사이를 무작위로 섞어 학습했으며, 가중 어텐션 모델은 addition에서 99.9 %, multiplication에서 99.4 % 정확도를 달성했다. 반면 무가중 평균은 각각 77.4 %와 55.5 %에 머물렀다. 이는 어텐션이 특정 시점의 정보를 선택적으로 강조할 수 있음을 입증한다.
제한점으로는 순서 정보가 완전히 사라지기 때문에, 순서가 중요한 태스크(예: 두 심볼 순서 구분)에서는 전혀 작동하지 않는다. 저자들은 실제 문서 분류와 같이 단어 순서가 크게 영향을 미치지 않는 경우에 이 접근법이 유용할 수 있음을 강조한다. 또한, 동일 구조를 서브시퀀스 검색 등 고차원·초대형 데이터에 적용한 별도 연구도 진행 중이다. 앞으로는 순서 정보를 보존하면서도 병렬성을 유지하는 하이브리드 설계가 필요할 것으로 보인다.
댓글 및 학술 토론
Loading comments...
의견 남기기