다중 데이터 소스를 위한 희소 그룹 팩터 분석 기반 바이클러스터링
본 논문은 그룹 팩터 분석(GFA)을 확장하여 스파스(spike‑and‑slab) 사전과 변수‑레벨 희소성을 도입함으로써, 여러 유전체 데이터 소스를 동시에 바이클러스터링할 수 있는 베이지안 모델을 제안한다. 시뮬레이션과 NCI‑DREAM 약물 반응 예측 과제에서 제안 방법이 기존 단일‑뷰 혹은 연결된 데이터 기반 방법보다 높은 정확도와 해석 가능성을 보였다.
저자: Kerstin Bunte, Eemeli Lepp"aaho, Inka Saarinen
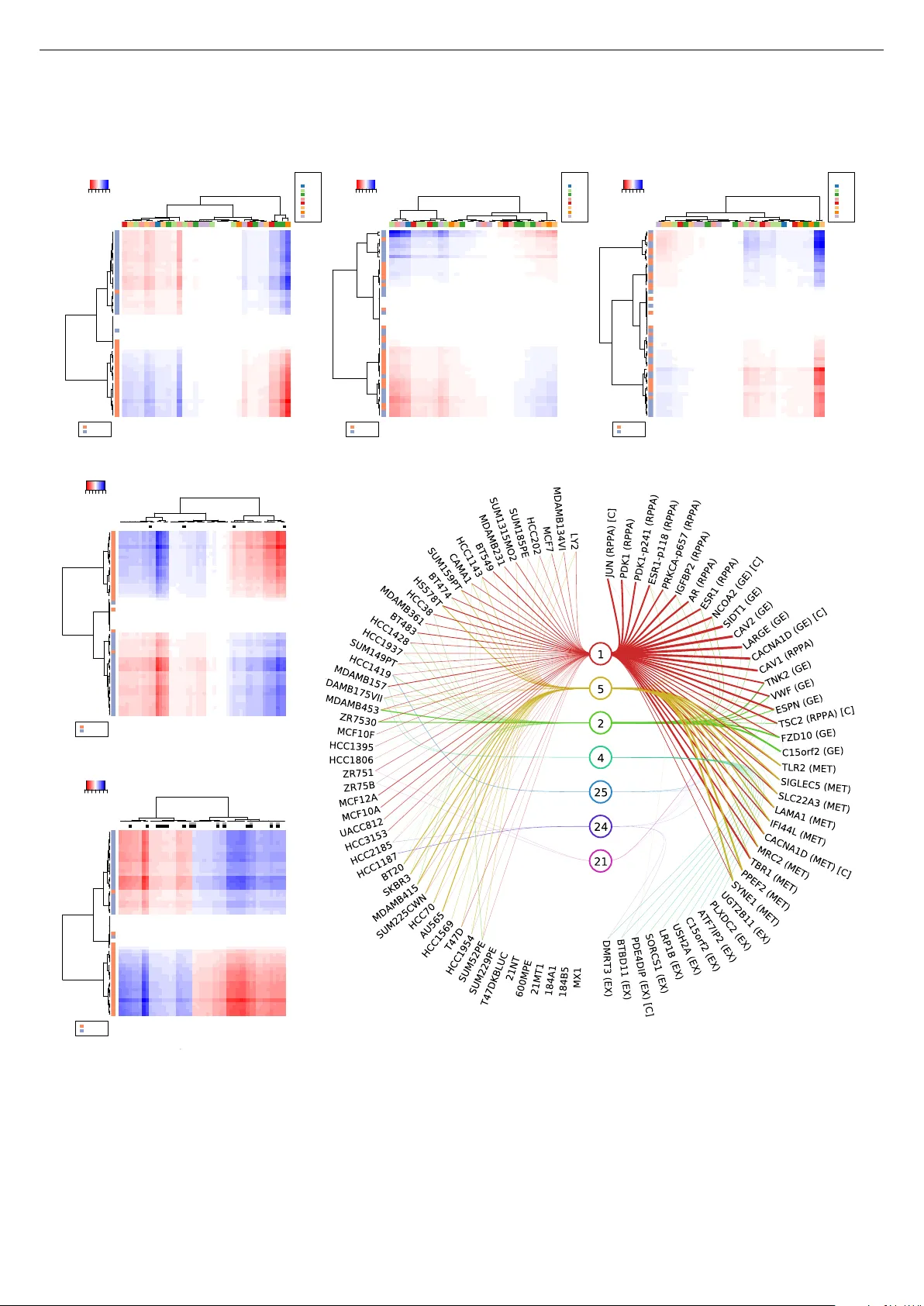
본 논문은 현대 유전체 연구에서 발생하는 대규모 다중 오믹스 데이터의 구조적 패턴을 효율적으로 탐지하기 위해, 기존 그룹 팩터 분석(Group Factor Analysis, GFA)을 바이클러스터링에 적합하도록 확장한 새로운 베이지안 모델을 제안한다. 전통적인 바이클러스터링은 단일 데이터 매트릭스(주로 유전자 발현)에서 행(샘플)과 열(유전자)의 부분집합을 동시에 군집화하는 기법으로, 최근에는 선형 종속성을 고려한 Factor Analysis for Bicluster Acquisition(FABIA)와 같은 확률적 접근법이 등장하였다. 그러나 이러한 방법들은 다중 데이터 소스(view)를 동시에 모델링하기에 한계가 있다.
제안된 모델은 GFA의 기본 구조를 유지하면서, 각 뷰의 로딩 행렬 W^(m)와 샘플 잠재 변수 X에 대해 스파스(spike‑and‑slab) 사전을 도입한다. 구체적으로, w_{d,k}^{(m)}와 x_{n,k}에 대해 이진 활성화 변수 h를 두어, h=1일 경우 정규분포(N(0,α^{-1}))를, h=0일 경우 정확히 0(δ_0)으로 고정한다. 이진 변수 h는 베타 사전(π)으로, 스케일 파라미터 α는 감마 사전으로 각각 정규화된다. 이러한 설계는 (i) 특정 뷰에만 영향을 미치는 전용 컴포넌트, (ii) 모든 뷰에 공통적인 컴포넌트, (iii) 일부 뷰에만 공유되는 컴포넌트를 자동으로 구분하게 하며, 변수‑레벨 스파스성을 통해 실제 바이클러스터(행·열의 부분집합) 해석을 가능하게 만든다.
모델 추론은 공액성을 이용한 Gibbs 샘플링으로 수행한다. 샘플링 복잡도는 데이터 샘플 수 N 과 전체 피처 수 D 에 대해 선형이며, 컴포넌트 수 K 에 대해 세제곱 수준이다. 실험에서는 사전 지정된 K 보다 약간 큰 값(예: K+5)을 설정하고, 불필요한 컴포넌트는 자동으로 0으로 수렴하도록 하여 모델이 스스로 적절한 바이클러스터 수를 선택하도록 했다.
시뮬레이션 연구에서는 여섯 가지 시나리오를 설계하였다. (a) 동질적인 뷰가 다수인 경우, (b) 뷰마다 이질적인 신호·노이즈 비율을 갖는 경우, (c) 그룹‑스파스 바이클러스터(특정 뷰에만 강하게 나타나는 경우), (d) 뷰별 구조화 잡음이 추가된 경우, (e) 부분적으로 겹치는 다중 바이클러스터, (f) 바이클러스터 강도가 뷰마다 다르게 변하는 경우다. 결과는 특히 (b)~(d) 상황에서 기존 FABIA와 단일‑뷰 기반 Factor Analysis(F‑A)보다 높은 F1 점수를 기록했으며, 컴포넌트 수를 정확히 추정한 비율이 90 % 이상이었다. 이는 다중 뷰의 이질성 및 그룹‑스파스 가정이 모델 성능에 크게 기여함을 보여준다.
실제 데이터 적용으로는 NCI‑DREAM 약물 감수성 예측 과제를 선택하였다. 53개의 인간 유방암 세포주에 대해 6가지 오믹스 데이터(유전자 발현, RNA‑seq, DNA 메틸화, 복제수 변이, 단백질 양, 엑솜 시퀀스)와 31개의 약물에 대한 IC50 값을 이용했다. 제안 모델은 각 뷰별로 공유·전용 바이클러스터를 자동으로 탐지하고, 이를 기반으로 약물 반응을 예측하였다. 교차 검증 결과, 제안 모델은 기존 베이스라인(Elastic Net, Random Forest 등)보다 높은 예측 정확도(R² ≈ 0.68)를 달성했으며, 특히 메틸화와 단백질 양이 동시에 변하는 서브그룹이 특정 약물에 대한 감수성에 큰 영향을 미치는 것을 확인하였다. 이러한 바이클러스터는 생물학적 해석이 가능하도록 구성 요소를 명시적으로 제공한다.
결론적으로, 이 논문은 (1) 다중 오믹스 데이터를 위한 그룹‑스파스 베이지안 팩터 모델을 제안, (2) 스파스 사전과 Gibbs 샘플링을 통해 자동 컴포넌트 선택 및 바이클러스터 해석을 구현, (3) 시뮬레이션 및 실제 약물 반응 데이터에서 기존 방법 대비 우수한 성능과 해석력을 입증함으로써, 복합 오믴스 데이터 통합 분석에 새로운 방향을 제시한다. 향후 연구에서는 비선형 확장, 시간적 데이터 통합, 그리고 대규모 클라우드 환경에서의 효율적 구현 등이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기