걸프 아라비아 대규모 말뭉치 구축과 분석
초록
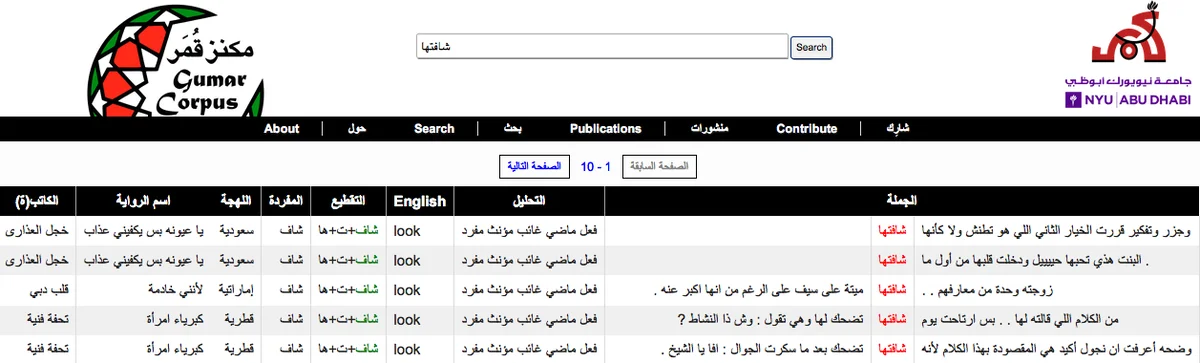
본 논문은 걸프 아라비아 방언(Gulf Arabic) 텍스트 1,200편의 포럼 소설에서 추출한 1억 1천만 단어 규모의 Gumar 말뭉치를 소개한다. 문서 수준에서 하위 방언을 라벨링하고, 기존 CODA 규칙을 확장한 정규화 표기법을 제시하며, 초기 형태소 주석 결과를 보고한다. 또한 웹 기반 탐색 인터페이스를 제공한다.
상세 분석
이 연구는 아랍어 자연어 처리 분야에서 방언 자원의 불균형을 해소하려는 중요한 시도이다. 기존 연구는 주로 현대 표준 아랍어(MSA)와 이집트 방언에 집중했으며, 걸프 방언에 대한 대규모 코퍼스는 거의 없었다. 저자들은 온라인 포럼에 자발적으로 게시된 장편 소설을 수집함으로써 방언 텍스트의 새로운 출처를 발굴했다. 1,200개의 MS Word 문서를 자동 크롤링하고, 문서당 평균 9,300문장, 92,000단어라는 규모를 확보했다. 특히 방언별(사우디, 아랍에미리트, 쿠웨이트 등) 라벨링을 문서 수준에서 수행했으며, 작가의 별명, 등장인물 이름, 문화적 요소(히즈리 달력 등)를 활용해 방언 식별 정확도를 높였다.
형태소 주석에서는 기존 이집트 방언용 형태소 분석기(MADAMIRA‑EGY)를 베이스로 사용하고, CODA(Conventional Orthography for Dialectal Arabic)를 걸프 방언에 맞게 확장하였다. 이는 방언 텍스트의 비표준 철자를 통일해 자동 처리 파이프라인 구축에 필수적인 전처리 단계다. 저자들은 규칙 기반 정규화와 사전 구축 과정을 상세히 기술하고, 초기 주석 품질을 정량적으로 평가했다.
또한 웹 인터페이스를 통해 연구자와 일반 사용자가 말뭉치를 자유롭게 탐색·다운로드할 수 있게 함으로써, 향후 형태소 분석, 구문 분석, 기계 번역, 스펠링 교정 등 다양한 NLP 응용 연구의 기반을 제공한다. 이와 같은 공개 데이터 정책은 방언 연구 커뮤니티의 협업을 촉진하고, 데이터 편향 문제를 완화하는 데 기여한다.
전반적으로 본 논문은 방언 자원의 규모·다양성·표준화라는 세 축을 동시에 달성했으며, 향후 GA 형태소 사전 확대, 다중 방언 병렬 코퍼스 구축, 심층 신경망 기반 모델 학습 등 연구 방향을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기