기본 감정을 활용한 Q러닝
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
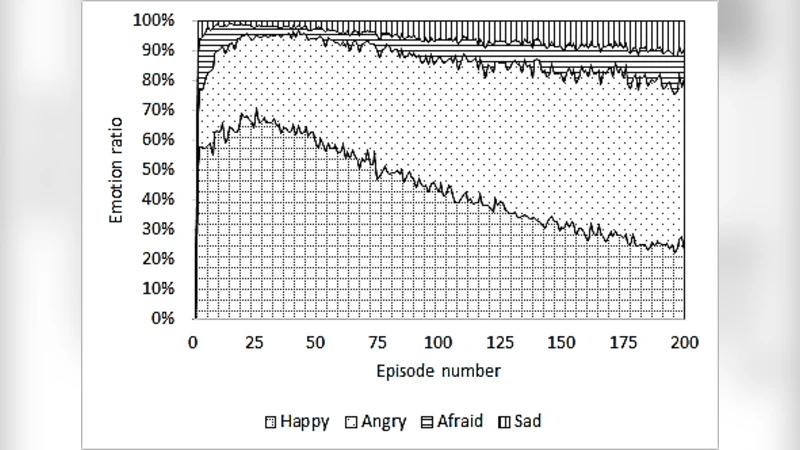
본 논문은 Q‑학습 에이전트에 네 가지 기본 감정(기쁨, 슬픔, 두려움, 분노)을 도입하여 탐색‑활용 균형을 동적으로 조절하는 방법을 제안한다. 감정 상태에 따라 행동 선택 확률을 변형함으로써, 에이전트는 최적 경로를 찾는 데 필요한 총 단계 수를 감소시킨다. 실험 결과, 감정 기반 에이전트는 전통적인 Q‑학습 대비 탐색 비율이 점진적으로 낮아지며, 장기적으로 더 효율적인 경로 탐색을 달성한다.
상세 분석
이 연구는 강화학습 분야에서 감정 메커니즘을 수학적으로 모델링하고 Q‑learning에 통합하는 최초의 시도 중 하나이다. 저자는 인간의 기본 감정 네 가지를 각각 탐색‑활용 전략에 매핑하였다. ‘기쁨’은 높은 보상 기대와 연관되어 탐색 확률을 증가시켜 새로운 경로를 시도하도록 유도하고, ‘슬픔’은 보상이 낮을 때 탐색을 억제해 현재 정책을 유지하도록 만든다. ‘두려움’은 위험(예: 높은 비용) 상황에서 급격히 탐색을 감소시켜 안전한 행동을 선택하게 하며, ‘분노’는 부정적인 피드백이 반복될 때 탐색을 다시 활성화시켜 정책을 재조정한다. 이러한 감정‑행동 매핑은 감정 강도를 실시간으로 업데이트하는 감정 상태 변수(E_t)를 도입함으로써 구현된다.
Q‑learning의 핵심 업데이트식 Q(s,a)←Q(s,a)+α
댓글 및 학술 토론
Loading comments...
의견 남기기