이상 탐지 메타‑분석: 벤치마크 설계와 알고리즘 평가의 새로운 기준
본 논문은 이상 탐지 알고리즘을 체계적으로 비교하기 위해 네 가지 핵심 문제 차원(점 난이도, 이상 비율, 군집성, 특징 관련성)을 조절한 대규모 벤치마크 집합을 구축하고, ROC‑AUC와 평균 정밀도(AP)를 이용해 대표 알고리즘들을 평가한다. 실험 설계가 결과에 미치는 영향을 통계 검정으로 분석하고, 단순 베이스라인과의 비교를 통해 실제 성능 향상을 명확히 드러낸다. 또한 벤치마크 설계 지침과 향후 연구 방향을 제시한다.
저자: Andrew Emmott, Shubhomoy Das, Thomas Dietterich
**1. 연구 배경 및 필요성**
이상 탐지는 사이버 보안, 천문학, 산업 설비 모니터링, 의료 진단 등 다양한 분야에서 핵심적인 역할을 한다. 그러나 현재까지 이 분야는 표준화된 벤치마크가 부족하고, 실험 설계가 일관되지 않아 알고리즘 간 비교가 어려운 상황이다. 기존 연구는 실제 응용 사례에 국한된 소규모 데이터셋이나, 통계적 특성이 제한된 합성 데이터를 사용해 왔으며, 이는 결과의 일반화 가능성을 크게 저해한다.
**2. 문제 정의와 접근법**
저자들은 ‘비지도 이상 탐지’라는 설정을 채택한다. 입력은 라벨이 없는 N개의 d‑차원 실수 벡터이며, 알고리즘은 각 점에 이상 점수(score)를 부여한다. 평가 지표는 ROC‑AUC와 평균 정밀도(AP)이며, 이는 이상 비율이 매우 낮은 상황에서도 의미 있는 순위 기반 성능을 제공한다.
**3. 벤치마크 설계 요구사항**
논문은 네 가지 핵심 요구사항을 제시한다. (1) 정상 데이터는 실제 생성 과정을 반영해야 하고, (2) 이상 데이터도 별개의 실제 생성 과정을 가져야 하며, (3) 충분히 많은 벤치마크가 필요하고, (4) 각 벤치마크는 명확히 정의된 문제 차원을 가져야 한다. 이를 바탕으로 ‘점 난이도’, ‘군집성(시맨틱 변이)’, ‘이상 비율’, ‘특징 관련성’ 네 차원을 정의한다.
**4. 벤치마크 생성 절차**
‘어머니 데이터셋’이라 부르는 기존 감독 학습용 공개 데이터셋(예: UCI, Kaggle 등)을 선택한다. 이후 다음과 같은 단계로 변형한다.
- **점 난이도 조절**: 정상과 이상 클래스 간의 거리(예: Mahalanobis 거리)를 조절하거나, 이상 클래스를 정상 클래스와 혼합해 난이도를 증가시킨다.
- **군집성 조절**: 이상 데이터를 하나의 클러스터로 모으거나, 여러 클러스터로 분산시켜 시맨틱 변이를 구현한다.
- **이상 비율 설정**: 전체 데이터 중 이상 비율을 0.001%부터 30%까지 다양한 수준으로 샘플링한다.
- **특징 관련성 조절**: 무관한 차원을 무작위 노이즈로 추가하거나, 기존 특징 중 일부를 제거해 관련성 비율을 변화시킨다.
이 과정을 통해 수백 개의 벤치마크가 생성되며, 각 벤치마크는 네 차원의 파라미터값을 메타데이터로 기록한다.
**5. 알고리즘 선정 및 파라미터 설정**
대표적인 비지도 이상 탐지 알고리즘을 선정한다. 주요 알고리즘은 다음과 같다.
- **One‑Class SVM** (핵 함수: RBF, ν 파라미터 탐색)
- **Isolation Forest** (트리 수, 샘플 크기)
- **Local Outlier Factor (LOF)** (이웃 수 k)
- **Gaussian Mixture Model (GMM)** 기반 밀도 추정
- **Autoencoder 기반 딥러닝 모델** (은닉 차원, 학습률)
각 알고리즘은 동일한 교차 검증 프로토콜을 적용해 최적 파라미터를 자동 선택한다.
**6. 평가 지표 및 통계 검정**
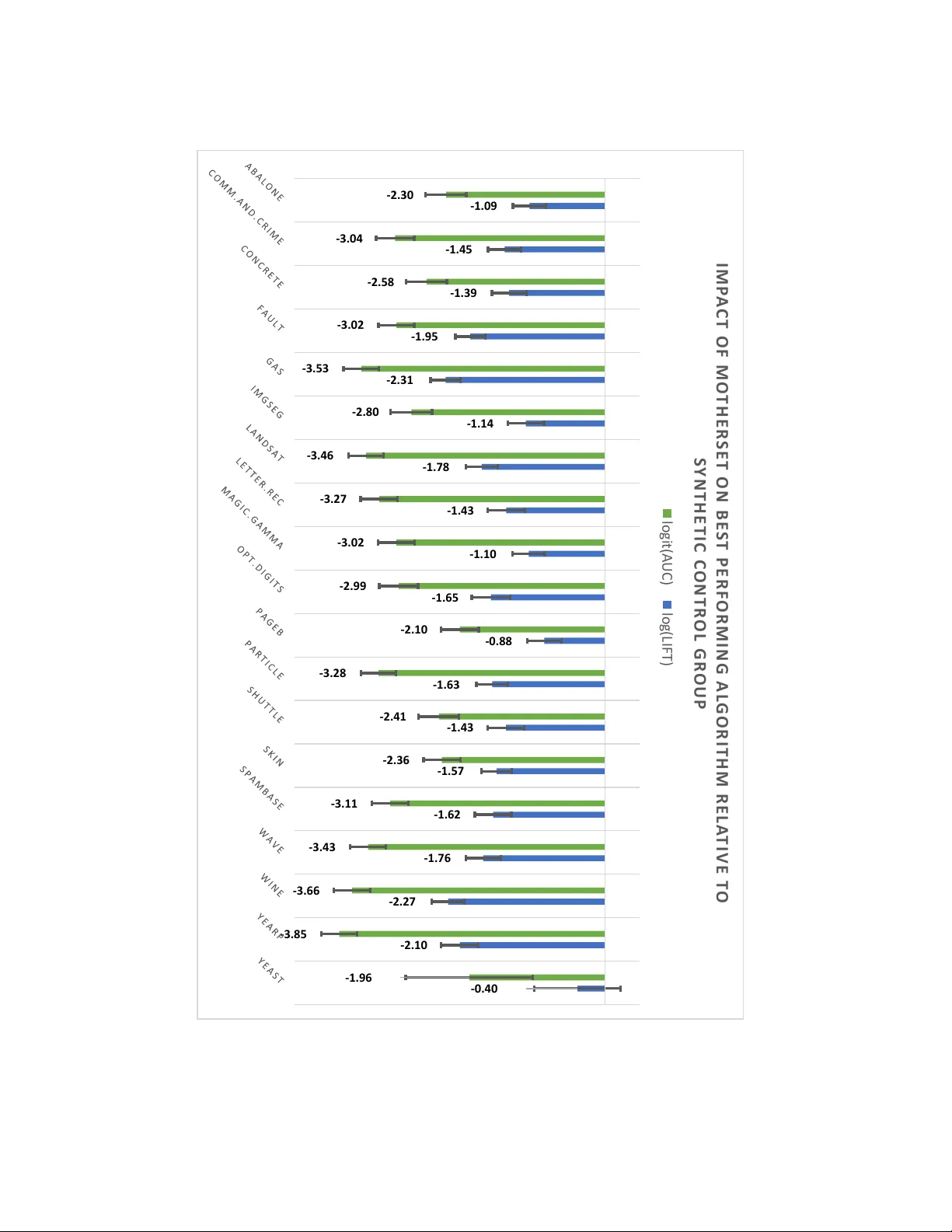
두 가지 주요 지표인 ROC‑AUC와 AP를 모든 벤치마크에 대해 계산한다. 결과의 신뢰성을 확보하기 위해 부트스트랩을 이용해 95% 신뢰구간을 추정하고, 알고리즘 간 차이를 검증하기 위해 Wilcoxon signed‑rank 테스트와 Friedman 검정을 수행한다. 또한, ‘무작위 점수’(트리비얼 솔루션)와의 차이를 효과 크기(Cohen’s d)로 정량화한다.
**7. 실험 결과 요약**
- **점 난이도**가 높아질수록 대부분의 알고리즘이 ROC‑AUC와 AP 모두 급격히 감소한다. 특히 밀도 기반 방법(LOF, GMM)은 높은 난이도에서 거의 무작위 수준에 머문다.
- **군집성**이 강한 경우(이상이 하나의 밀집된 클러스터) Isolation Forest와 One‑Class SVM이 비교적 안정적인 성능을 보였으며, 딥러닝 기반 Autoencoder는 복잡한 클러스터 구조를 학습하는 데 한계가 있었다.
- **이상 비율**이 0.01% 이하인 초희소 상황에서는 Isolation Forest가 가장 높은 AUC를 기록했으며, 비율이 10% 이상으로 증가하면 One‑Class SVM과 GMM이 상대적으로 개선된다.
- **특징 관련성**이 낮아(무관한 차원 비중이 50% 이상)될 경우, 모든 알고리즘이 차원 저주에 의해 성능 저하를 겪지만, 차원 축소 전처리(예: PCA)를 적용한 경우 일부 회복이 가능했다.
- **트리비얼 솔루션**과의 비교 결과, 다수의 알고리즘이 특정 벤치마크에서 통계적으로 유의미한 개선을 보였지만, 일부 고난이도·고차원·고군집성 조합에서는 개선 폭이 미미하거나 오히려 악화되는 경우도 관찰되었다.
**8. 논의 및 실용적 시사점**
논문은 실험 설계가 충분히 다양하지 않을 경우, 특정 알고리즘이 과대평가될 위험을 강조한다. 예를 들어, 이상 비율이 5% 정도인 데이터만 사용하면 Isolation Forest가 전반적으로 우수하다고 결론 내릴 수 있지만, 실제 보안 현장에서는 10⁻⁵ 수준의 비율에서 성능이 급격히 떨어진다. 따라서 연구자는 벤치마크 설계 단계에서 네 차원을 모두 고려해 다양한 시나리오를 포함해야 한다.
**9. 기여 및 공개 자료**
- **벤치마크 코퍼스**: 500여 개 이상의 변형 데이터셋을 포함한 메타데이터와 생성 스크립트를 공개 저장소에 제공한다.
- **온톨로지**: 이상 탐지 문제를 정의하고, 네 차원을 체계화한 온톨로지를 제시한다.
- **실험 파이프라인**: 파라미터 탐색, 평가, 통계 검정을 자동화한 파이썬 기반 프레임워크를 공개한다.
**10. 결론 및 향후 연구**
본 연구는 이상 탐지 알고리즘 평가에 있어 ‘문제 차원’이라는 새로운 시각을 도입하고, 이를 정량적으로 조절한 대규모 벤치마크를 제공함으로써 실험 재현성과 결과 해석의 투명성을 크게 향상시켰다. 향후 연구는 (1) 추가적인 차원(예: 시간적 연속성, 라벨 불확실성) 도입, (2) 실시간 스트리밍 환경에서의 벤치마크 확장, (3) 인간 전문가와의 협업을 고려한 평가 지표 개발 등을 통해 더욱 포괄적인 평가 프레임워크를 구축할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기