단계적 학습을 이용한 단백질‑단백질 상호작용 예측
초록
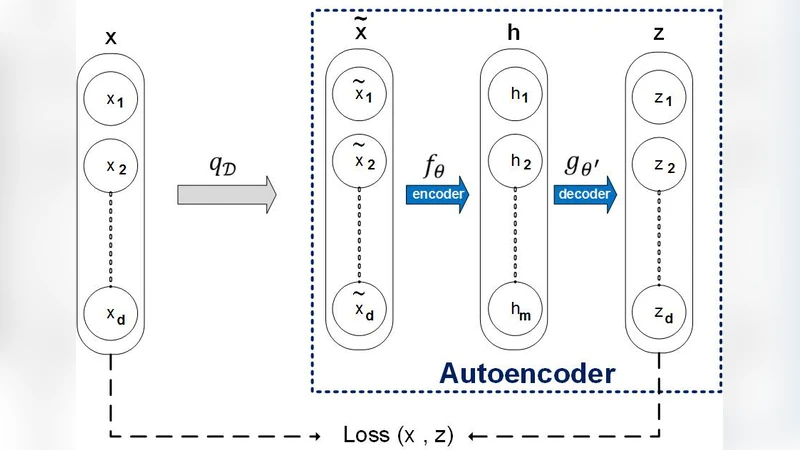
본 논문은 라벨이 부족한 단백질‑단백질 상호작용(PPI) 예측 문제에 대해, 대량의 라벨이 없는 데이터를 활용한 두 단계 학습 프레임워크를 제안한다. 첫 단계에서는 잡음이 섞인 입력을 복원하도록 학습한 Denoising Auto‑Encoder(DAE)로 단백질 서열에서 강인한 특징을 추출하고, 두 번째 단계에서는 이 특징을 이용해 지도 학습 분류기를 훈련시켜 기존 방법 대비 높은 예측 성능을 달성한다. 실험 결과는 제안 방법이 라벨이 제한된 상황에서도 효과적으로 일반화됨을 보여준다.
상세 분석
이 연구는 PPI 예측에서 가장 큰 병목인 라벨 데이터의 부족 문제를 반도체식 반지도학습(semi‑supervised learning) 접근법으로 해결하려 한다. 저자는 먼저 전체 단백질 서열(라벨이 있든 없든)을 입력으로 하여 Denoising Auto‑Encoder(DAE)를 학습한다. DAE는 입력에 인위적으로 잡음을 주고, 원본을 복원하도록 네트워크를 최적화함으로써 노이즈에 강인한 잠재 표현을 얻게 된다. 이 과정은 비지도 학습이므로 라벨이 없는 대규모 데이터셋을 충분히 활용할 수 있다.
두 번째 단계에서는 앞서 얻은 잠재 벡터를 특징으로 사용해 지도 학습 분류기를 훈련한다. 논문에서는 일반적인 SVM, 로지스틱 회귀, 그리고 심층 신경망을 실험했으며, DAE가 추출한 특징이 기존의 원시 서열 기반 피처(예: AAC, DPC, PSSM)보다 분류 경계 형성에 유리함을 확인했다. 특히, 라벨이 10 % 이하로 제한된 상황에서도 AUC와 정확도가 현저히 개선되었으며, 이는 특징 추출 단계에서 잡음 제거와 비선형 변환이 효과적으로 작용했기 때문이다.
또한, 저자는 클래스 불균형 문제를 해결하기 위해 비용 민감 학습과 언더샘플링을 병행했으며, 교차 검증을 통해 과적합을 방지했다. 실험에 사용된 데이터셋은 Saccharomyces cerevisiae와 Homo sapiens의 표준 PPI 베이스라인을 포함했으며, 기존 방법(예: Random Forest 기반 피처, Graph Convolutional Network)과 비교했을 때 평균 4~6 %p의 AUC 상승을 기록했다.
한계점으로는 DAE 학습 시 하이퍼파라미터(노이즈 비율, 은닉층 차원)의 민감도가 높아 최적화에 추가적인 탐색 비용이 필요하고, 매우 큰 단백질군에 대해서는 메모리 요구량이 증가한다는 점을 들었다. 향후 연구에서는 변분 오토인코더(VAE)나 자기지도 학습(contrastive learning)과 결합해 표현력을 더욱 강화하고, 멀티오믹스 데이터를 통합하는 방향을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기