깊은 클러스터링 기반 단일채널 다중화자 분리 혁신
본 논문은 기존 딥 클러스터링 모델에 정규화·깊은 네트워크·긴 시간 컨텍스트를 적용해 두 화자 분리에서 SDR 10.3 dB, 세 화자 분리에서 7.1 dB 향상을 달성한다. 또한 클러스터링 결과를 강화하는 Enhancement 레이어와 소프트 K‑means 기반의 엔드‑투‑엔드 학습을 도입해 신호 재구성 손실을 직접 최소화하고, 자동 음성 인식 실험에서 WER를 89.1 %에서 30.8 %로 크게 낮춘다.
저자: Yusuf Isik, Jonathan Le Roux, Zhuo Chen
**1. 서론**
인간은 복잡한 소음 환경에서도 대화를 구분할 수 있지만, 단일 채널에서 여러 화자를 분리하는 ‘칵테일 파티 문제’는 오랜 연구 과제다. 기존의 CASA, NMF, 베이시안 모델 등은 계산량이 크거나 화자 독립적인 경우 성능이 제한적이었다. 최근 딥 러닝 기반의 딥 클러스터링은 TF 셀마다 임베딩을 학습하고 이를 군집화해 마스크를 추정함으로써 퍼뮤테이션 문제를 해결했지만, 초기 구현은 2 dB 수준의 SDR 향상에 머물렀다.
**2. 딥 클러스터링 모델 복습**
입력 신호 x의 STFT X_{t,f}를 로그 스펙트럼으로 변환하고, N개의 TF 셀에 대해 D‑차원 임베딩 V∈ℝ^{N×D}를 BLSTM‑FFN 네트워크 f_θ로 얻는다. 임베딩은 단위 길이 제약을 두고, 목표는 V Vᵀ와 실제 어피니티 행렬 Y Yᵀ 사이의 Frobenius 거리 최소화(C_Y)이다. 테스트 시 K‑means로 임베딩을 군집화하고, 얻은 이진 마스크를 원본 스펙트럼에 적용해 각 화자를 복원한다.
**3. 학습 레시피 개선**
- **정규화**: 입력 로그 스펙트럼에 전역 평균·분산 정규화 적용.
- **드롭아웃**: 피드‑포워드 연결에 p=0.5, 순환 연결에 p=0.2 드롭아웃 적용. 순환 드롭아웃은 시퀀스 전체에 동일 마스크를 사용해 장기 기억을 보존한다.
- **그래디언트 클리핑**: |∇|≤200으로 폭발적 그래디언트 방지.
- **네트워크 심화**: 2‑layer BLSTM(300×2) → 4‑layer BLSTM(300×4) 확장, 각 레이어 뒤에 300‑차원 피드‑포워드 레이어를 삽입해 임베딩 차원 D=20으로 유지.
- **시간 컨텍스트**: 학습 시 100프레임(≈0.8 s) 구간에서 시작해 400프레임(≈3.2 s) 구간으로 전이하는 커리큘럼 학습 적용. 긴 구간은 전역 퍼뮤테이션 정렬을 용이하게 하여 최종 성능을 끌어올린다.
- **다중 화자 학습**: 2‑speaker와 3‑speaker 혼합을 동시에 학습시켜 모델이 화자 수에 대해 유연하게 일반화하도록 함.
**4. 신호 재구성을 위한 Enhancement 레이어**
딥 클러스터링이 만든 초기 마스크는 저에너지 TF 영역에서 손실이 크다. 이를 보완하기 위해 각 화자별로 강화 네트워크를 두었다. 입력은 (혼합 스펙트럼, 딥 클러스터링 추정 스펙트럼)이며, BLSTM‑FFN을 통과해 중간 출력 z_c를 만든다. 소프트맥스를 통해 각 화자에 대한 마스크 m_{c,i}=exp(z_{c,i})/Σ_{c'}exp(z_{c',i})를 계산하고, 이를 혼합 스펙트럼에 곱해 최종 추정 ˜s_c,i를 얻는다. 손실 C_E는 퍼뮤테이션 불변 L2 손실로 정의돼, 최적의 화자 매핑을 자동으로 찾는다.
**5. 엔드‑투‑엔드 학습과 소프트 K‑means**
하드 K‑means는 미분 불가능해 전체 파이프라인을 직접 최적화할 수 없었다. 저자는 가중 소프트 K‑means를 도입해 각 임베딩 v_i에 대해 클러스터 중심 μ_c와 할당 확률 γ_{i,c}=exp(-α‖v_i-μ_c‖²)/Σ_c'exp(-α‖v_i-μ_c'‖²) 를 계산한다. 여기서 α는 클러스터링 경도를 조절하고, w_i는 TF 에너지 기반 가중치(무음 구간에 0)이다. 이 과정을 여러 번 반복하고, 각 단계의 연산을 네트워크 레이어처럼 풀어 ‘딥 언폴딩’으로 구현한다. 이렇게 하면 클러스터링 단계까지 역전파가 가능해져, 최종 SI‑SDR 혹은 L1/ L2 손실을 직접 최소화하는 엔드‑투‑엔드 학습이 가능해진다.
**6. 실험 설정**
- 데이터: WSJ0 기반 2‑speaker(30 h)·3‑speaker(동일 규모) 혼합, 8 kHz 다운샘플링.
- 특징: 32 ms 창, 8 ms 홉, 로그 스펙트럼.
- 평가: SI‑SDR(=SDR)와 자동 음성 인식(WER) 사용.
- 베이스라인: 원 논문 dpcl v1 (2 dB SDR) 및 CASA(3.1 dB).
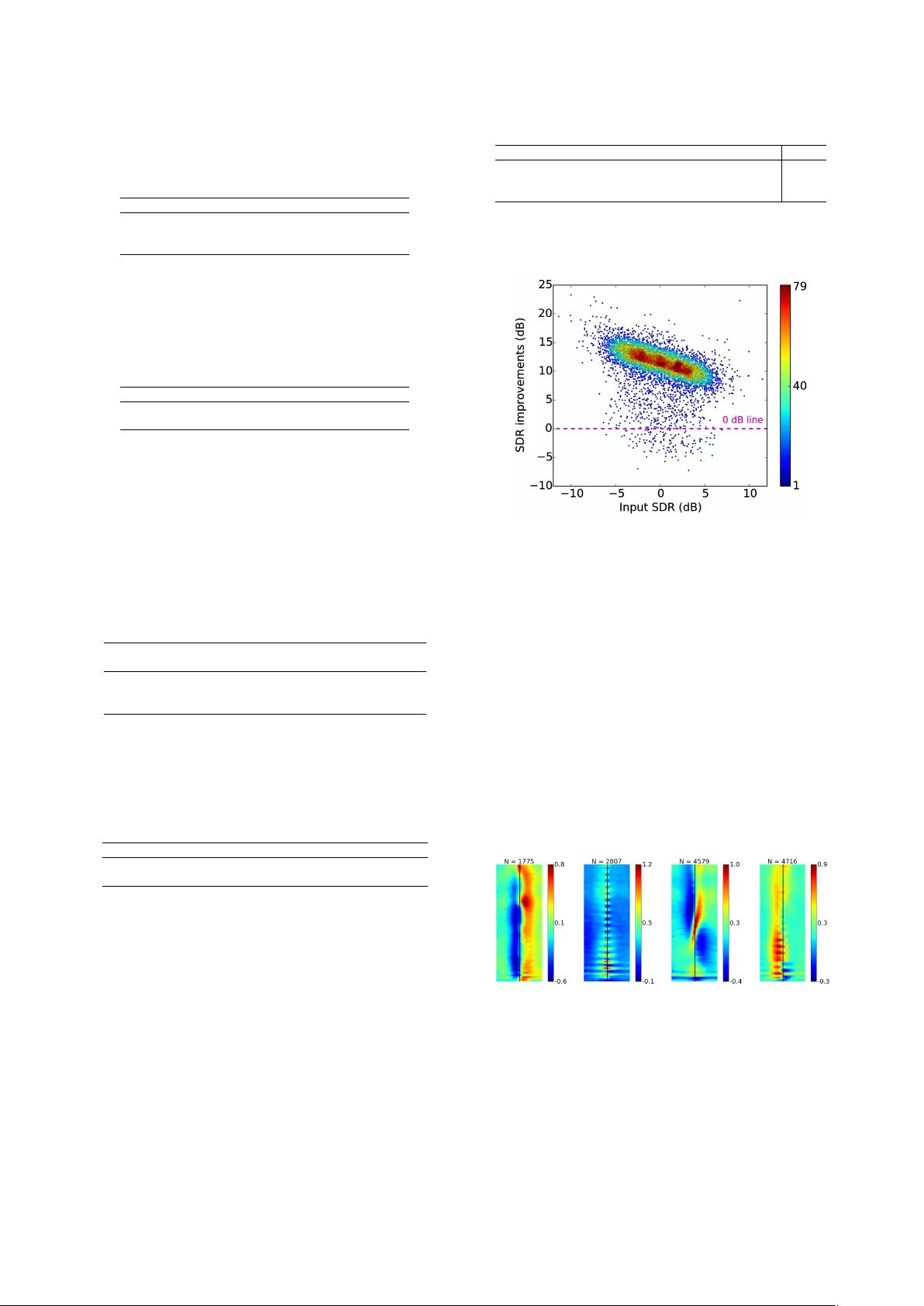
**7. 결과**
| 모델 | 2‑speaker SDR (dB) | 3‑speaker SDR (dB) | WER (%) |
|------|-------------------|-------------------|----------|
| IBM (ideal) | 13.5 | 13.3 | - |
| Wiener‑like (ideal) | 13.9 | 13.8 | - |
| dpcl v1 | 6.0 | - | 89.1 |
| 본 논문 (정규화·심화·긴 컨텍스트) | 9.0 | - | - |
| + Enhancement 레이어 | 10.2 | 7.5 | 45.3 |
| + End‑to‑End 소프트 K‑means | **10.3** | **7.1** | **30.8** |
두 화자 경우 SDR 10.3 dB(기존 6 dB 대비 +4.3 dB), 세 화자 경우 7.1 dB 향상. WER는 89.1 %에서 30.8 %로 크게 감소, 이는 실제 어플리케이션에서 인식 정확도가 크게 개선됨을 의미한다.
**8. 논의 및 향후 과제**
- 소프트 K‑means와 엔드‑투‑엔드 학습은 마스크의 연속성을 보장하고, 퍼뮤테이션 문제를 근본적으로 해결한다.
- 강화 네트워크는 저에너지 영역을 보완해 전체 파형 품질을 크게 높인다.
- 현재는 8 kHz 저해상도에서 실험했으며, 고해상도(16 kHz 이상)와 다채널 마이크 어레이에 대한 확장이 필요하다.
- 또한, 비음성 소음(배경음악, 환경소음)과의 혼합에서도 동일한 프레임워크가 적용 가능한지 추가 연구가 요구된다.
**9. 결론**
본 연구는 딥 클러스터링 기반 단일채널 다중화자 분리 시스템에 정규화·심화·긴 컨텍스트·Enhancement·엔드‑투‑엔드 학습을 통합함으로써, 기존보다 현저히 높은 SDR와 낮은 WER를 달성하였다. 이는 ‘칵테일 파티 문제’ 해결을 위한 중요한 진전이며, 향후 실시간 음성 비서, 회의 기록, 청각 보조 장치 등에 직접 적용될 가능성을 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기