의미 있는 모델: 개념 구조 활용으로 머신러닝 해석성 강화
초록
본 논문은 인간의 개념 형성 메커니즘, 특히 ‘형(form)’과 ‘기능(function)’이라는 두 축을 통해 의미를 정의하고, 이를 머신러닝 모델 설계에 적용함으로써 해석성을 높이는 방법을 제시한다. 저자는 인간의 암묵적 학습, 특징 추출, 개념화 과정을 심리학적·인지과학적 관점에서 분석하고, 모델의 목적과 입력·출력 요구사항을 명확히 규정하고, 기존 프로세스와의 연계 및 사용자 경험(UX) 설계를 통해 비전문가도 이해하기 쉬운 인터페이스를 제공할 것을 권고한다.
상세 분석
이 논문은 머신러닝 해석성 연구에 인간 인지과학을 접목한 독창적인 시도를 보여준다. 먼저 저자는 ‘암묵적 학습(implicit learning)’을 인간이 의식적 노력 없이 환경으로부터 특징을 추출하는 과정으로 정의하고, 이러한 하위 수준의 특징이 의식적 개념화 단계에서 ‘키‑값’ 구조(기호‑특징 집합)로 전환된다고 설명한다. 여기서 ‘키’는 단어, 이미지 등 심볼이며, ‘값’은 해당 심볼이 내포하는 다차원 특징이다. 이러한 관점은 전통적인 피처 엔지니어링을 인간 두뇌의 자연스러운 과정에 비유함으로써, 모델 설계 시 인간이 직관적으로 이해할 수 있는 피처 집합을 선택하는 것이 해석성 향상의 첫걸음임을 시사한다.
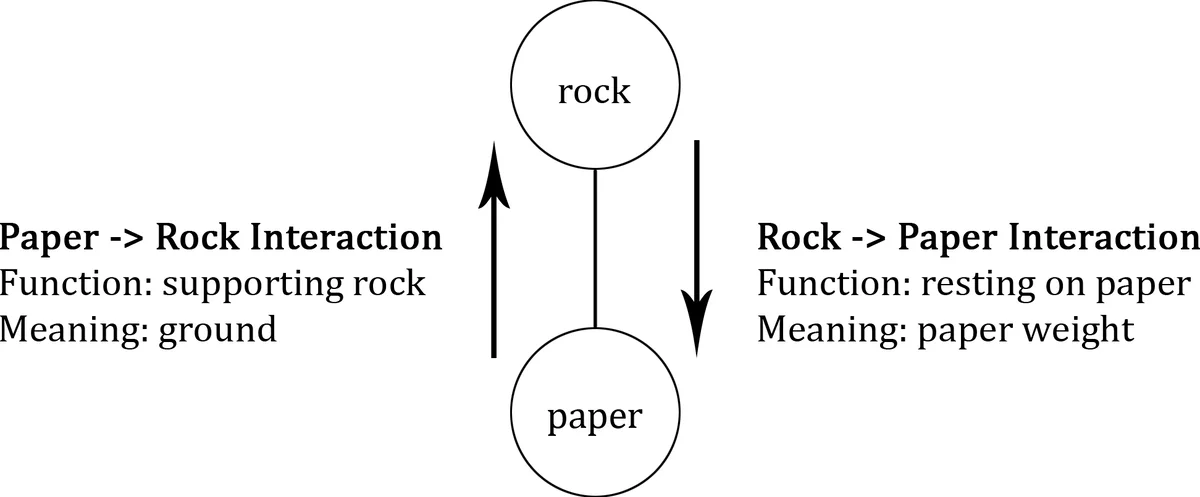
다음으로 저자는 ‘형(form)’과 ‘기능(function)’이라는 두 축을 도입해 의미를 재정의한다. ‘기능’은 특정 맥락에서 개념이 수행하는 역할, 즉 입력‑출력 관계를 의미하며, 이는 개념의 핵심(core) 특징에 해당한다. 반면 ‘형’은 그 기능을 구현하는 구체적 인스턴스로, 주변(peripheral) 특징을 담는다. 예를 들어 “go”와 “head”는 동일한 기능(이동)에서는 같은 의미를 가지지만, “head the ball”에서는 전혀 다른 기능을 수행한다. 이러한 구분은 모델 출력이 동일한 기능을 수행하지만 형식이 다양할 때, 사용자는 어떤 형식이 자신의 업무 흐름에 맞는지를 판단할 수 있게 한다.
실제 모델 설계에 적용하기 위해 저자는 세 가지 실천적 제안을 제시한다. 첫째, 모델의 ‘기능’을 명확히 기술한다는 것으로, 입력 조건과 목표 출력(예: 의료 진단, DNA 시퀀스 마이닝 등)을 구체적으로 명시하고, 불필요한 피처를 최소화한다. 이는 변수 선택 알고리즘(예: 변수 중요도 순위, 가중치 제거)과 결합해 모델 복잡도를 낮추고, 해석성을 높인다. 둘째, 모델을 기존 업무 프로세스에 자연스럽게 배치함으로써 그 ‘맥락(context)’을 제공한다. 모델이 전체 시스템에서 어떤 단계에 위치하고, 어떤 의사결정을 지원하는지를 명시하면 사용자는 모델의 역할을 직관적으로 이해한다. 셋째, 사용자 경험(UX) 관점에서 프론트엔드를 설계한다는 점이다. 입력 폼, 결과 시각화, 설명 텍스트 등을 친숙한 형식으로 제공하고, 사용성 지표(추천 의사, 효율성 개선, 문제점 파악 등)를 지속적으로 측정·반영한다.
이러한 접근은 해석성을 사후에 추가하는 것이 아니라, 모델 설계 초기 단계부터 ‘형‑기능’ 구조를 고려하도록 함으로써, 정확도와 해석성 사이의 전통적 트레이드오프를 완화한다는 점에서 의미가 크다. 또한, 의미를 ‘관계적 함수’로 보는 관점은 현재의 설명가능 인공지능(XAI) 기법—예: LIME, SHAP—과도 연결될 수 있다. 즉, LIME이 지역 선형 모델을 통해 기능을 설명하고, SHAP이 기여도를 시각화하는 방식이 ‘기능’에 해당하고, 그 결과를 사용자에게 친숙한 ‘형’으로 변환하는 UI 설계가 필요하다는 점을 강조한다.
결론적으로, 인간 인지 메커니즘을 모델 설계에 반영함으로써, 비전문가도 모델의 의도와 작동 원리를 빠르게 파악할 수 있는 ‘의미 있는 모델’ 구축이 가능하다는 것이 논문의 핵심 주장이다. 이는 향후 머신러닝이 다양한 도메인에 확산될 때, 기술과 사용자의 간극을 메우는 중요한 전략으로 활용될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기