무작위 가우시안 가중치 딥 뉴럴 네트워크 보편적 분류 전략
이 논문은 무작위 가우시안 가중치를 갖는 심층 신경망이 입력 데이터의 거리 구조를 거의 보존하면서, 클래스 간 각도 차이를 이용해 구분능력을 강화한다는 이론적 근거를 제시한다. 1‑비트 압축 센싱과 가우시안 평균 폭 개념을 활용해 각 층이 Gromov‑Hausdorff 의미에서 δ‑동형임을 증명하고, ReLU 비선형성이 각도에 따라 거리 수축을 조절함을 보인다. 또한, 이러한 특성이 학습 데이터 양과 일반화에 미치는 영향을 정량화한다. 실험을 …
저자: Raja Giryes, Guillermo Sapiro, Alex M. Bronstein
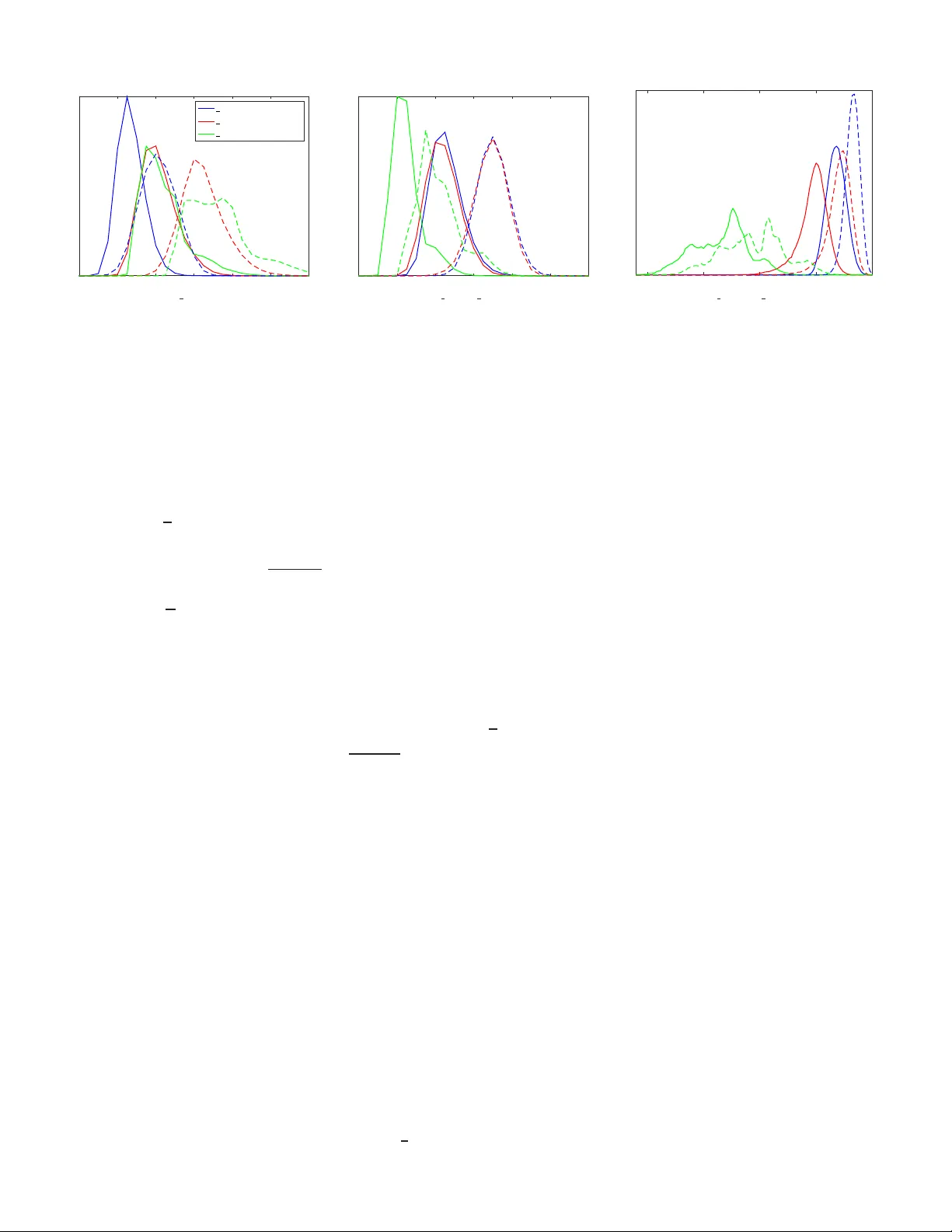
본 논문은 딥 뉴럴 네트워크(DNN)의 구조적 특성을 무작위 가우시안 가중치라는 가정 하에 체계적으로 분석한다. 저자는 먼저 분류 시스템이 만족해야 할 세 가지 기본 속성—입력 정보 보존, 학습 샘플이 미지 데이터에 대한 정보를 전달, 클래스 간 차별화—을 제시하고, 이러한 속성이 무작위 가중치를 갖는 DNN에서도 충족된다는 것을 증명한다.
1. **이론적 배경 및 동기**
- 무작위 가중치 기반 학습이 실제로 좋은 성능을 보인 사례들을 소개하고, 압축 센싱, 로컬리티‑센시티브 해싱(LSH), 위상 복원 등에서 무작위 연산이 핵심 역할을 했던 역사를 언급한다.
- 기존 연구(Arora 등, Bruna‑Mallat 등)와 차별화하기 위해, 본 논문은 무작위 가중치가 데이터 매니폴드의 거리 구조를 어떻게 변형시키는지에 초점을 맞춘다.
2. **단일 레이어의 안정적 임베딩**
- 입력 매니폴드 K⊂S^{n‑1}의 복잡도를 Gaussian mean width ω(K)로 정의하고, 이를 통해 매니폴드가 저차원 구조(예: 가우시안 혼합, 희소 표현)임을 정량화한다.
- 랜덤 행렬 M∈ℝ^{m×n} (i.i.d. N(0,1/√m))와 반절단 비선형 함수 f(주로 ReLU)를 적용한 후, sign 함수를 통해 이진 출력 g(x)=sgn(f(Mx))를 만든다.
- 정리 1에 의해, 충분히 큰 출력 차원 m에 대해 g는 δ‑isometry이며, δ≈C·m^{−1/6}·ω(K)^{1/3}이다. 이는 구면 거리와 Hamming 거리 사이의 차이가 작아, 각 레이어가 입력 메트릭을 거의 보존한다는 의미다.
- 이 결과는 각 레이어가 고차원 하이퍼플레인으로 공간을 테셀레이션하고, 같은 셀에 속하는 점들의 직교 거리 ≤δ임을 의미한다. 따라서 LSH와 유사하게 거리 정보를 이진 코드에 효율적으로 인코딩한다.
3. **ReLU가 만든 각도 의존적 거리 변형**
- 순수 랜덤 프로젝션만으로는 유클리드 거리가 거의 보존되지만, ReLU는 양·음 부호를 구분함으로써 입력 벡터 사이의 각도 θ에 따라 거리 수축 정도가 달라진다.
- 작은 각도(동일 클래스)인 경우 거리 감소가 크게 일어나고, 큰 각도(다른 클래스)인 경우 감소가 상대적으로 적다. 이는 “각도 기반 거리 변형”이라고 부를 수 있다.
- 네트워크가 깊어질수록 이러한 변형이 누적돼, 같은 클래스 내부는 더욱 뭉쳐지고, 서로 다른 클래스는 상대적으로 멀어지는 효과가 강화된다.
4. **내재 차원 유지와 학습 샘플 복잡도**
- 각 레이어를 통과하면서 매니폴드의 내재 차원(즉, ω(K))은 크게 증가하지 않는다. 이는 전체 네트워크가 저차원 구조를 유지하면서도 고차원 임베딩을 수행한다는 것을 의미한다.
- 이를 바탕으로, 충분히 일반화 가능한 모델을 학습하기 위해 필요한 샘플 수 N은 O(ω(K)^2·log |K|) 수준으로 추정된다. 즉, 데이터가 저차원 매니폴드에 집중될수록 적은 학습 샘플로도 좋은 성능을 기대할 수 있다.
5. **학습 과정의 역할**
- 무작위 네트워크는 라벨 정보를 전혀 사용하지 않으므로, 클래스 간 각도 차이를 자동으로 강조하지 않는다.
- 실제 학습된 네트워크와 무작위 네트워크를 비교한 실험에서, 학습은 특정 각도를 선택적으로 강조하고, 클래스 간 거리 확대를 더욱 크게 만든다. 이는 학습이 “각도 선택” 메커니즘을 통해 분류 경계를 최적화한다는 실증적 증거다.
- ILSVRC(ImageNet) 등 대규모 데이터셋에서 최신 아키텍처를 적용한 결과, 논문에서 제시한 이론적 예측과 일치하는 거리·각도 변화를 관찰했다.
6. **결론 및 향후 연구**
- 무작위 가우시안 가중치를 갖는 DNN은 본질적으로 거리 보존 임베딩을 수행하면서, ReLU와 같은 비선형성이 각도에 따라 거리 변형을 일으켜 클래스 구분을 강화한다.
- 학습은 이러한 기본 메커니즘 위에 추가적인 각도 선택 및 좌표계 정렬을 적용해 성능을 끌어올린다.
- 향후 연구는 풀링, 컨볼루션, 비가우시안(서브가우시안) 가중치 등에 대한 일반화, 그리고 실제 데이터에서 각도 가정이 깨지는 경우에 대한 대처 방안을 탐구할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기