와이드 앤 딥 학습 기반 추천 시스템
와이드(선형) 모델과 딥(신경망) 모델을 동시에 학습시켜 메모리와 일반화를 동시에 달성한다. 구글 플레이의 앱 추천에 적용해 3.9%의 온라인 획득 증가와 10 M 앱/초 처리량을 14 ms 지연으로 구현했으며, TensorFlow 구현을 오픈소스로 제공한다.
저자: Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen
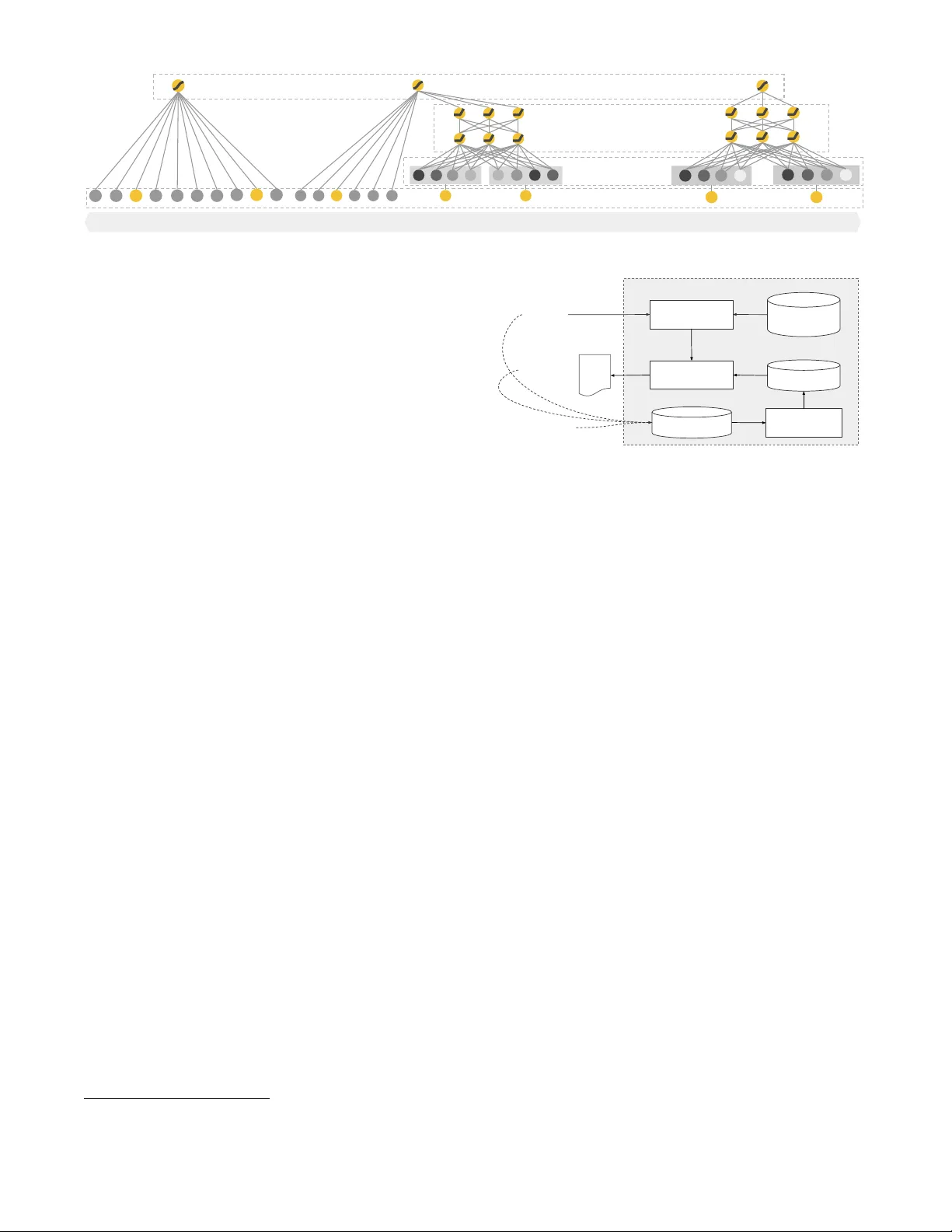
본 논문은 대규모 희소 피처를 다루는 추천 시스템에서 ‘기억(Memorization)’과 ‘일반화(Generalization)’라는 두 가지 상반된 요구를 동시에 만족시키기 위한 모델 구조인 Wide & Deep Learning을 제안한다. 기존의 일반화 선형 모델(예: 로지스틱 회귀)은 교차곱(feature cross)과 같은 명시적 변환을 통해 빈번히 관측되는 피처 조합을 효과적으로 기억하지만, 새로운 피처 조합에 대한 일반화 능력이 제한적이다. 반면, 딥 뉴럴 네트워크는 각 범주형 피처를 저차원 임베딩으로 변환하고 다층 비선형 함수를 적용함으로써, 훈련 데이터에 존재하지 않았던 조합에 대해서도 예측이 가능하도록 일반화한다. 그러나 사용자‑아이템 매트릭스가 희소하고 고랭크인 경우, 딥 모델은 모든 쌍에 대해 비제로 예측값을 생성해 과도한 일반화(over‑generalization)로 이어지며, 이는 추천 정확도 저하를 초래한다.
이를 해결하기 위해 저자들은 Wide 파트와 Deep 파트를 동시에 학습시키는 ‘Joint Training’ 방식을 채택한다. Wide 파트는 일반화 선형 모델에 교차곱 변환을 포함한 희소 피처 집합을 사용한다. 교차곱 변환 φ_k(x) = ∏_{i∈c_k} x_i 은 해당 피처들이 모두 1일 때만 1이 되며, 이는 특정 피처 조합을 직접 기억하도록 만든다. Deep 파트는 범주형 피처를 10~100 차원의 임베딩 벡터로 매핑하고, 이들을 모두 연결(concatenate)한 뒤 2~3개의 ReLU 은닉층을 통과시켜 고차원 비선형 상호작용을 학습한다. 두 파트의 출력(logit)은 가중합 형태로 결합되어 하나의 시그모이드 로지스틱 손실에 의해 동시에 최적화된다.
학습 최적화에서는 Wide 파트에 FTRL‑L1(Follow‑the‑Regularized‑Leader with L1 regularization) 알고리즘을, Deep 파트에 AdaGrad를 적용해 각각의 특성에 맞는 학습률 조절을 수행한다. 이렇게 하면 Wide 파트는 메모리 역할을, Deep 파트는 일반화 역할을 수행하면서도 파라미터 수를 최소화할 수 있다.
시스템 구현은 크게 세 단계로 나뉜다. 1) 데이터 생성 단계에서는 사용자 행동 로그와 앱 인상(impression) 데이터를 수집해, 문자열 피처를 정수 ID로 매핑하는 vocabularies를 만든다. 연속형 피처는 누적 분포 함수 기반 양자화(quantile)로
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기