텍스트 분류를 위한 인터랙티브 의미 사전 특징
본 논문은 전통적인 사전(딕셔너리) 기반 특징을 확장해, 문맥 정보를 활용하는 ‘스무딩 사전 특징(smoothed dictionary features)’을 제안한다. 교사가 직접 사전을 정의하고, 문맥 모델을 통해 사전 항목이 등장할 확률을 추정함으로써 동형어·동음이의어 구분과 누락된 용어 보완이 가능해진다. 인터랙티브한 피처링·라벨링 루프를 통해 사전을 구축하고, 두 개의 실제 웹 페이지 분류 작업(헬스, 음악)에서 BoW 대비 경쟁력 있는 …
저자: Camille J, ot, Patrice Simard
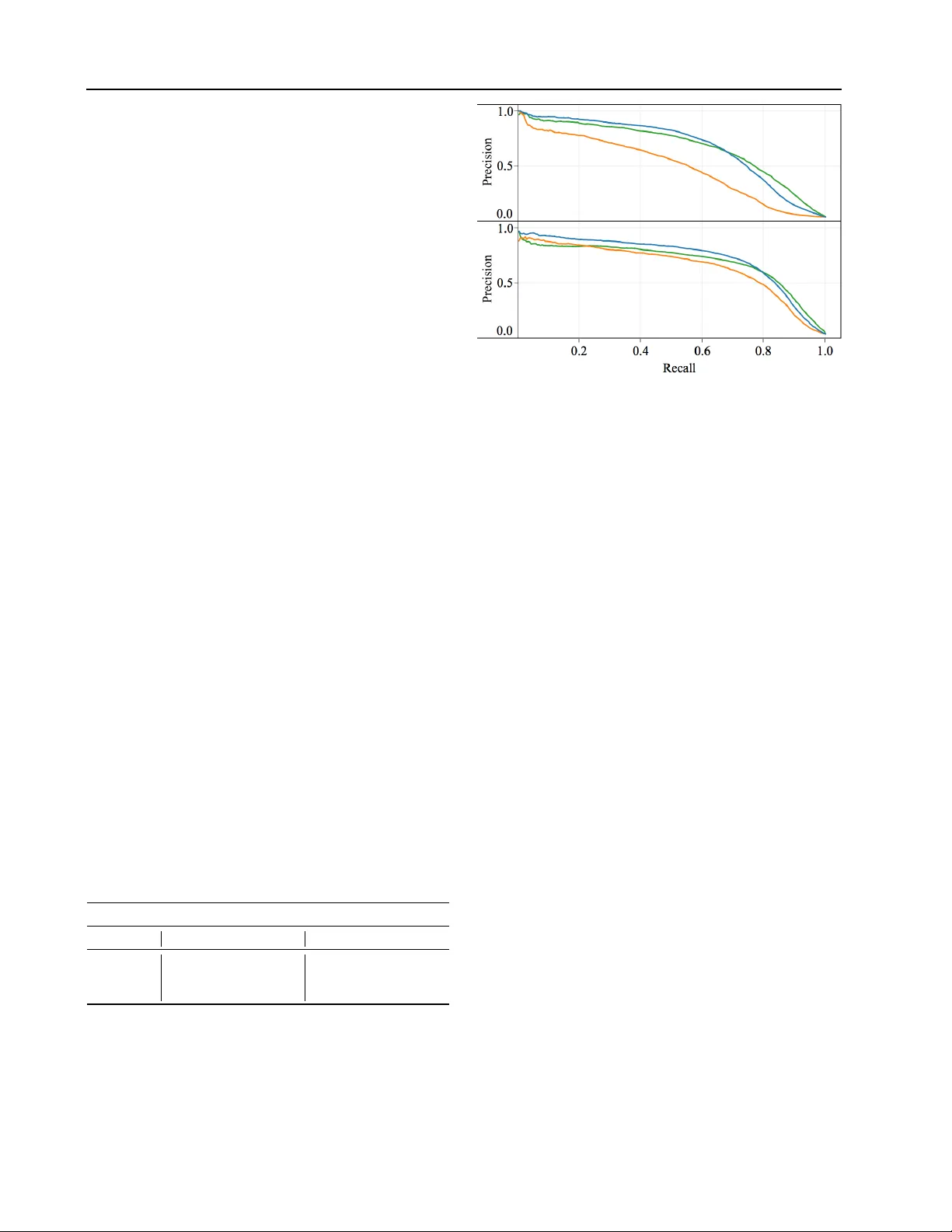
본 논문은 텍스트 분류 작업에서 인간이 직관적으로 이해하고 조작할 수 있는 특징을 제공하기 위해 기존 사전(dictionary) 기반 특징을 확장한 ‘스무딩 사전 특징(smoothed dictionary features)’을 제안한다. 전통적인 사전 특징은 사전에 포함된 n‑gram이 문서에 그대로 나타날 때만 매치를 카운트한다. 이러한 방식은 (1) 사전에 포함되지 않은 동의어나 변형을 놓치고, (2) 동음이의어나 다의어를 구분하지 못한다는 근본적인 한계를 가진다. 저자들은 이러한 문제를 해결하기 위해 ‘문맥 모델(context model)’을 도입한다. 문맥 모델은 특정 n‑gram g가 사전에 속할 확률 p(g ∈ D | Context)를 추정한다. 이를 위해 g 주변의 토큰을 비중첩하는 10개의 문맥 윈도우(크기 1, 2, 4, 8 등)를 정의하고, 각 윈도우에 대해 나이브 베이즈 기반 로그 오즈 점수 c_i = log
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기