비선형 분류기 예측 설명을 위한 레이어와이즈 관련성 전파의 NLP 적용
본 논문은 이미지 분야에서 성공을 거둔 레이어와이즈 관련성 전파(LRP) 기법을 자연어 처리에 최초로 적용한다. 20 NewsGroups 데이터셋을 이용한 토픽 분류 CNN 모델에 LRP와 전통적인 민감도 분석(SA)을 비교 평가하고, 단어 삭제 실험, 시각화, PCA 기반 문서 표현 등 다양한 실험을 통해 LRP가 보다 의미 있는 단어 중요도 해석을 제공함을 입증한다.
저자: Leila Arras, Franziska Horn, Gregoire Montavon
본 논문은 레이어와이즈 관련성 전파(Layer‑wise Relevance Propagation, LRP)라는 최신 설명 기법을 자연어 처리(NLP) 분야에 최초로 적용하고, 기존의 민감도 분석(Sensitivity Analysis, SA)과 비교 평가한다. 연구 배경으로는 딥러닝 모델이 텍스트 분류, 감성 분석 등 다양한 NLP 과제에서 뛰어난 성능을 보이지만, 내부 의사결정 과정을 이해하기 어려워 ‘블랙박스’ 문제를 야기한다는 점을 들었다. 이미지 분야에서는 LRP가 시각적 히트맵을 통해 모델이 어떤 픽셀에 주목했는지를 명확히 보여주었으며, 이를 NLP에 그대로 옮겨볼 필요가 있다.
방법론에서는 20 NewsGroups 데이터셋(20개 토픽, 총 18,846문서)을 사용해 토픽 분류 CNN 모델을 구축하였다. 입력은 사전 학습된 구글 뉴스 word2vec(300차원) 임베딩을 고정하고, 각 문서는 최대 400 토큰으로 잘라낸다. CNN 구조는 1‑D 컨볼루션(필터 크기 2, 800개) → ReLU → 전역 1‑Max‑Pooling → 전결합(FC) 로 이루어져 있다. 모델은 80.19% 정확도를 달성했으며, 이는 최신 최고 성능(≈83%)에 근접한다.
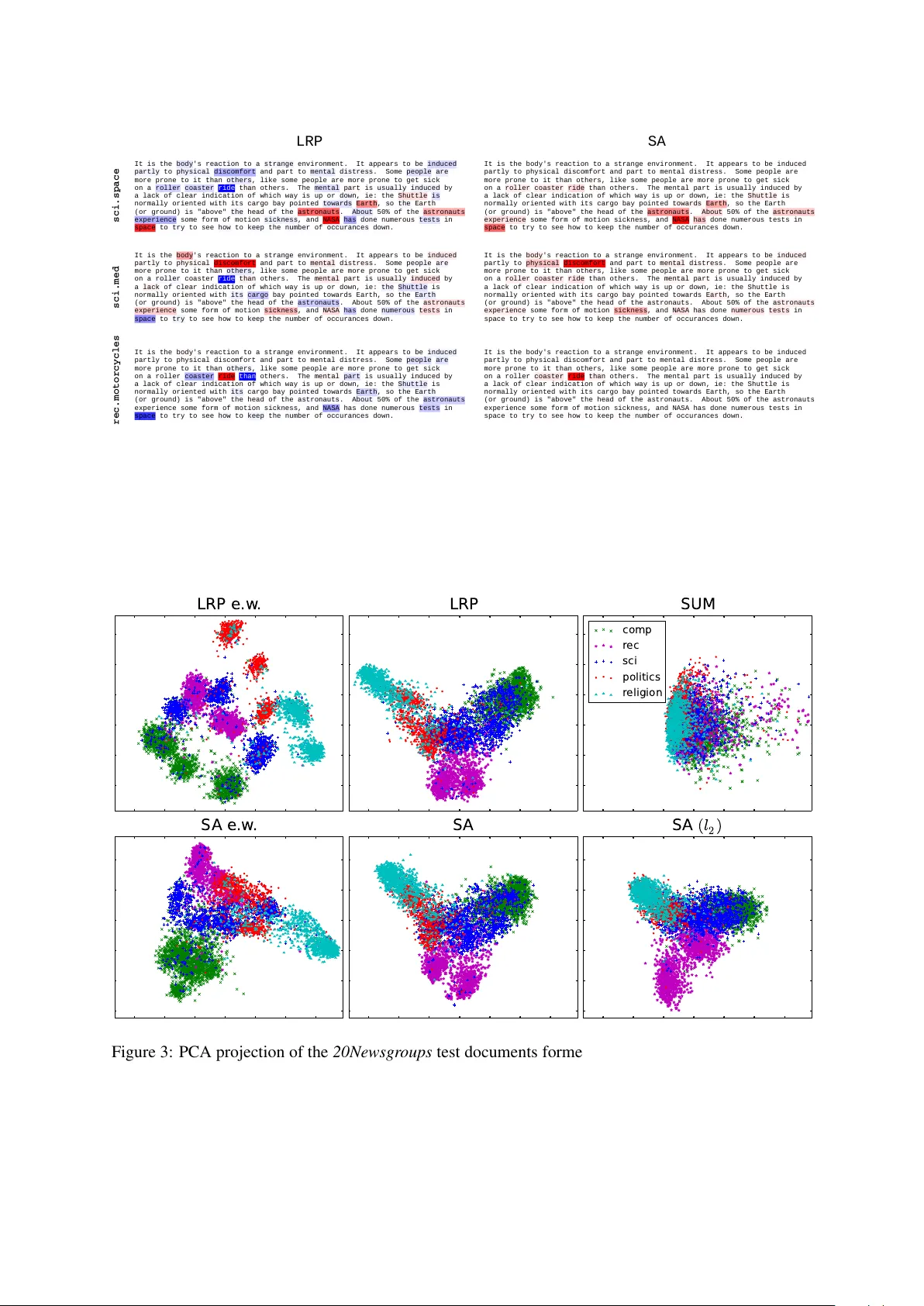
LRP는 모델의 최종 출력 f(x)를 입력 변수 x_d에 대한 중요도 R_d 로 보존(conservation)하는 방식으로 역전파한다. 각 뉴런 j의 활성화 z_j는 입력 x_i와 가중치 w_{ij}의 선형 결합이며, 관련성 R_j는 입력에 비례적으로 재분배한다. 재분배 공식은 R_{i←j}= (z_{ij}+s(z_j))/∑_i(z_{ij}+s(z_j))·R_j 로, 여기서 s(z_j) 은 0에 가까운 분모를 안정화하기 위한 작은 상수이다. 이 과정은 양·음의 기여를 모두 보존하며, 최종적으로 f(x)=∑_d R_d 를 만족한다. 반면 SA는 출력에 대한 입력의 2‑제곱 편미분 ‖∇_x f(x)‖² 를 사용해 중요도를 정의한다. SA는 로컬 변화에만 민감하고, 양의 값만 반환한다는 제한이 있다.
중요도 평가를 위해 두 가지 ‘단어 삭제’ 실험을 설계하였다. 첫 번째 실험에서는 처음에 올바르게 분류된 문서(정답 클래스가 모델 출력과 일치)에서 높은 중요도 순으로 단어를 삭제한다. LRP는 삭제된 단어 수가 증가함에 따라 정확도가 급격히 감소했으며, SA보다 더 빠른 하강을 보였다. 이는 LRP가 실제로 분류에 기여하는 핵심 단어를 정확히 식별한다는 증거이다. 두 번째 실험에서는 처음에 오분류된 문서에 대해 낮은 중요도 순으로 단어를 삭제한다. 여기서도 LRP가 SA보다 더 큰 정확도 회복 효과를 보였으며, 특히 LRP가 부정적 관련성을 가진 방해 단어를 효과적으로 제거한다는 점을 확인했다.
시각화 측면에서는 단어별 히트맵을 생성해 LRP와 SA의 차이를 직관적으로 보여준다. 예를 들어 ‘ride’ 라는 단어는 ‘motorcycles’ 토픽에 대해 LRP는 강한 부정적 관련성을 부여했지만, SA는 단순히 양의 값만을 반환해 구분이 어려웠다. 이는 LRP가 양·음의 기여를 명시적으로 제공함을 의미한다. 또한, LRP와 SA를 가중치로 사용해 문서 벡터를 재구성하고, 이를 PCA로 2‑차원에 투영한 결과를 비교하였다. LRP 기반 가중치는 토픽 군집을 가장 명확히 구분했으며, SA와 단순 합산(UNIFORM) 방식은 군집이 흐릿하게 나타났다. 이는 LRP가 의미론적 관계를 보존하면서 중요한 단어에 높은 가중치를 부여한다는 점을 시사한다.
논의에서는 LRP가 이미지 분야에서 입증된 설명력을 NLP에도 성공적으로 이전했음을 강조한다. LRP는 모델 전반에 걸친 증거량을 보존하고, 양·음의 기여를 명시적으로 제공함으로써 해석 가능성, 오류 분석, 모델 디버깅 등에 유용한 도구가 된다. 반면 SA는 구현이 간단하고 계산 비용이 낮지만, 로컬 변화에만 초점을 맞추어 전체적인 의사결정 구조를 충분히 드러내지 못한다는 한계가 있다. 따라서 복잡한 텍스트 분류 모델을 투명하게 이해하고자 할 때 LRP가 보다 적합한 선택임을 실험적으로 입증하였다. 향후 연구에서는 LRP를 다른 NLP 태스크(예: 감성 분석, 질의응답)와 다양한 모델(예: Transformer)에도 적용하고, 설명 기반 모델 개선 방안을 모색할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기