머신러닝과 데이터 기반 저널리즘: 국제 뉴스 이해와 투명성 강화
본 논문은 머신러닝, 통계학, 저널리즘 연구를 결합해 국가별 뉴스 보도의 차이를 정량적으로 분석하고, TTIP(미·EU 무역협정) 사례를 통해 국제 여론의 구조와 프레이밍을 밝힌다. LDA, Attentional Topic Model, PDN, word2vec 등 다양한 텍스트 모델을 활용해 언어 장벽을 낮추고, 인간 평가와 통계적 검증을 병행함으로써 데이터‑드리븐 저널리즘의 가능성을 제시한다.
저자: Elena Erdmann, Karin Boczek, Lars Koppers
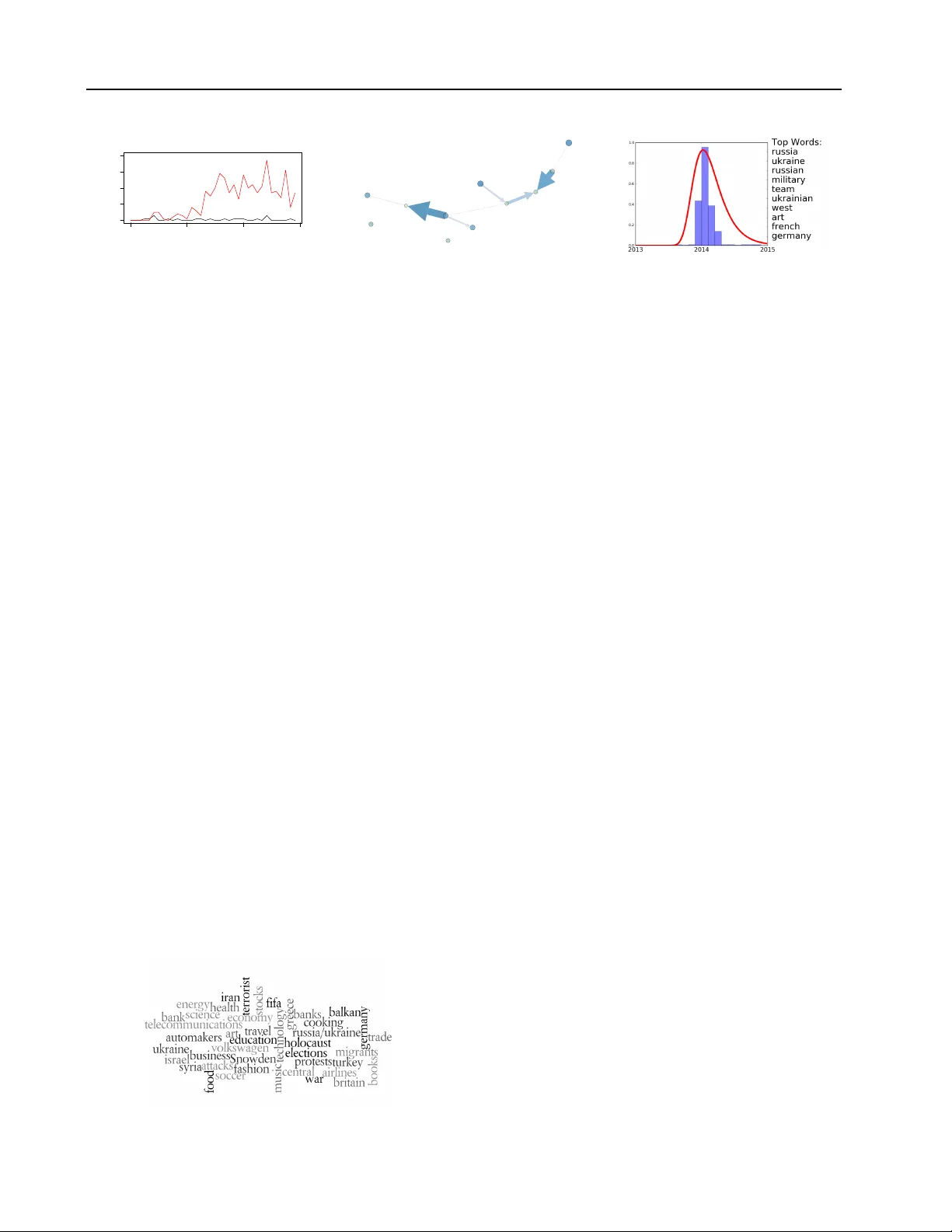
본 논문은 글로벌 이슈에 대한 국제적 공론장을 형성하기 위해, 국가별 뉴스 보도의 파편화와 언어 장벽을 머신러닝과 데이터‑드리븐 저널리즘 기법으로 해소하고자 하는 ‘위치 선언(position statement)’이다. 서론에서는 이민 위기, 기후 변화, 조세 회피와 같은 전 지구적 문제들이 국가 중심의 미디어 환경 때문에 공동 논의가 어려워진다는 점을 강조한다. 특히, 파나마 페이퍼스와 같은 사례가 국제 협력의 가치를 보여주지만, 일상적인 국제 사안은 여전히 ‘국내 vs. 해외’ 논리로 보도된다고 비판한다.
문제 제기를 바탕으로 저자들은 머신러닝, 통계학, 저널리즘 연구를 결합한 인터디서플리너리 접근법을 제시한다. 구체적으로는 다음과 같은 텍스트 분석 도구들을 활용한다.
1. **LDA와 Topics over Time (TOT)** – 토픽을 확률적 단어 분포로 모델링하고, 시간 축을 추가해 토픽의 증감 추이를 파악한다.
2. **Attentional Topic Model (@TM)** – 기존 토픽 모델이 인간의 주의 곡선을 반영하지 못한다는 점을 보완, Shifted Gompertz 분포를 적용해 뉴스 보도의 실제 관심도 변화를 물리적으로 설명한다.
3. **Probabilistic Dependency Networks (PDN) 및 Directed APM** – 단어 간 비대칭 의존성을 그래프 형태로 모델링, ‘조약’과 ‘국무장관’처럼 한 단어가 다른 단어를 강하게 유도하는 관계를 포착한다.
4. **word2vec** – 단어 임베딩을 통해 특정 이슈와 연관된 의미 네트워크를 시각화하고, ‘염소 처리된 닭고기’와 같은 상징적 프레이밍을 자동 탐지한다.
이러한 모델들을 실제 사례인 TTIP(Transatlantic Trade and Investment Partnership) 논쟁에 적용한다. 데이터는 미국 뉴욕타임즈와 독일 Süddeutsche Zeitung 두 일간지에서 ‘TTIP’라는 키워드가 포함된 기사들을 추출한 것이다. 분석 결과는 다음과 같다.
- **보도량 차이**: 2014년 이후 독일 매체는 TTIP 관련 기사 수가 급증했지만, 미국 매체는 큰 변동이 없었다. 이는 독일 대중이 TTIP에 대해 더 높은 관심을 보였음을 의미한다.
- **토픽 구조**: LDA 토픽을 저널리스트가 라벨링한 결과, 독일 매체는 ‘EU 정책·관세·투자자 보호’와 같은 프레이밍을, 미국 매체는 ‘금융·유로 위기·경제 안정’에 초점을 맞추었다.
- **단어 의존성**: PDN 분석에서 독일 기사에서는 ‘EU 헌법·의회·참여’와 같은 정치적 구조가 강조된 반면, 미국 기사에서는 이러한 논의가 거의 나타나지 않았다.
- **주의 곡선**: @TM을 적용한 결과, 독일 매체는 TTIP와 직접 연결된 주의 토픽이 존재했지만, 미국 매체는 ‘우크라이나 전쟁’ 등 다른 국제 이슈에 주의가 집중돼 있었다.
- **워드 임베딩**: word2vec 결과는 양국 매체가 ‘이민’과 같은 주제에서는 유사한 단어 맥락을 공유하지만, TTIP와 관련해서는 독일이 ‘염소 처리된 닭고기·식품 안전’이라는 부정적 프레이밍을, 미국이 ‘무역 협상·투자 파트너십’이라는 중립적·사실적 어휘를 주로 사용함을 보여준다.
이러한 다층적 분석을 통해 저자들은 국제 여론이 어떻게 국가별 미디어 프레이밍에 의해 다르게 형성되는지를 정량적으로 입증한다. 또한, 인간 저널리스트와 통계적 평가를 병행함으로써, ‘대량 문서 최적화’와 ‘의미 있는 소수 문서’ 사이의 평가 기준 차이를 드러낸다.
마지막으로 논문은 향후 연구 방향을 제시한다. 첫째, 알고리즘 텍스트 분석(ATA)의 베스트 프랙티스를 정립하고, 저널리스트가 손쉽게 활용할 수 있는 툴킷을 개발해야 한다. 둘째, 국제 공론장의 장기적·단기적 담론 패턴을 연결해 ‘아젠다 설정’, ‘이슈 주의 사이클’, ‘프레이밍’ 등을 정량적으로 시각화할 필요가 있다. 셋째, 다양한 언어와 문화권을 포괄하는 다국어 모델을 구축해, 현재의 ‘국가별 파편화’를 넘어선 글로벌 뉴스 분석 인프라를 마련해야 한다.
결론적으로, 머신러닝 기반 텍스트 분석은 국제 뉴스 보도의 투명성을 높이고, 국가 간 이해를 촉진하는 강력한 도구임을 강조한다. 그러나 그 잠재력을 실현하려면 컴퓨터 과학자, 통계학자, 커뮤니케이션 연구자, 현장 저널리스트 간의 지속적인 협업과, 사용성을 고려한 알고리즘 설계가 필수적이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기