딥러닝 기반 전력 부하 예측으로 에너지 효율 극대화
본 논문은 스마트 미터 데이터를 활용해 단기 전력 부하를 예측하고, 전력 생산·분배 효율을 높이는 방안을 제시한다. 전통적인 회귀·트리 모델과 다중 심층 신경망(DNN, DNN‑SA, RNN, LSTM, CNN 등)을 비교 실험했으며, DNN 계열이 평균 절대오차율(MAPE)에서 2~3% 수준으로 가장 우수함을 확인했다. 다만 학습 시간과 계산 비용이 크게 증가한다는 트레이드오프가 존재한다. 결과를 바탕으로 동적 가격 책정 및 전력 생산 최적화…
저자: Stefan Hosein, Patrick Hosein
본 논문은 전력 생산·분배 과정에서 발생하는 에너지 손실을 최소화하기 위해, 스마트 미터에서 수집된 고해상도 전력 사용 데이터를 활용한 단기 부하 예측(STLF) 모델을 개발하고, 전통적인 통계·머신러닝 기법과 최신 딥러닝 아키텍처를 체계적으로 비교한다. 서론에서는 현재 전력 생산의 약 58%가 낭비되고 있으며, 특히 산업·주거 부문에서 큰 비중을 차지한다는 사실을 제시한다. 부하 예측을 통해 발전량을 정확히 맞추면 화석 연료 사용을 줄이고, 동적 가격 정책을 통해 소비자 행동을 유도할 수 있음을 강조한다.
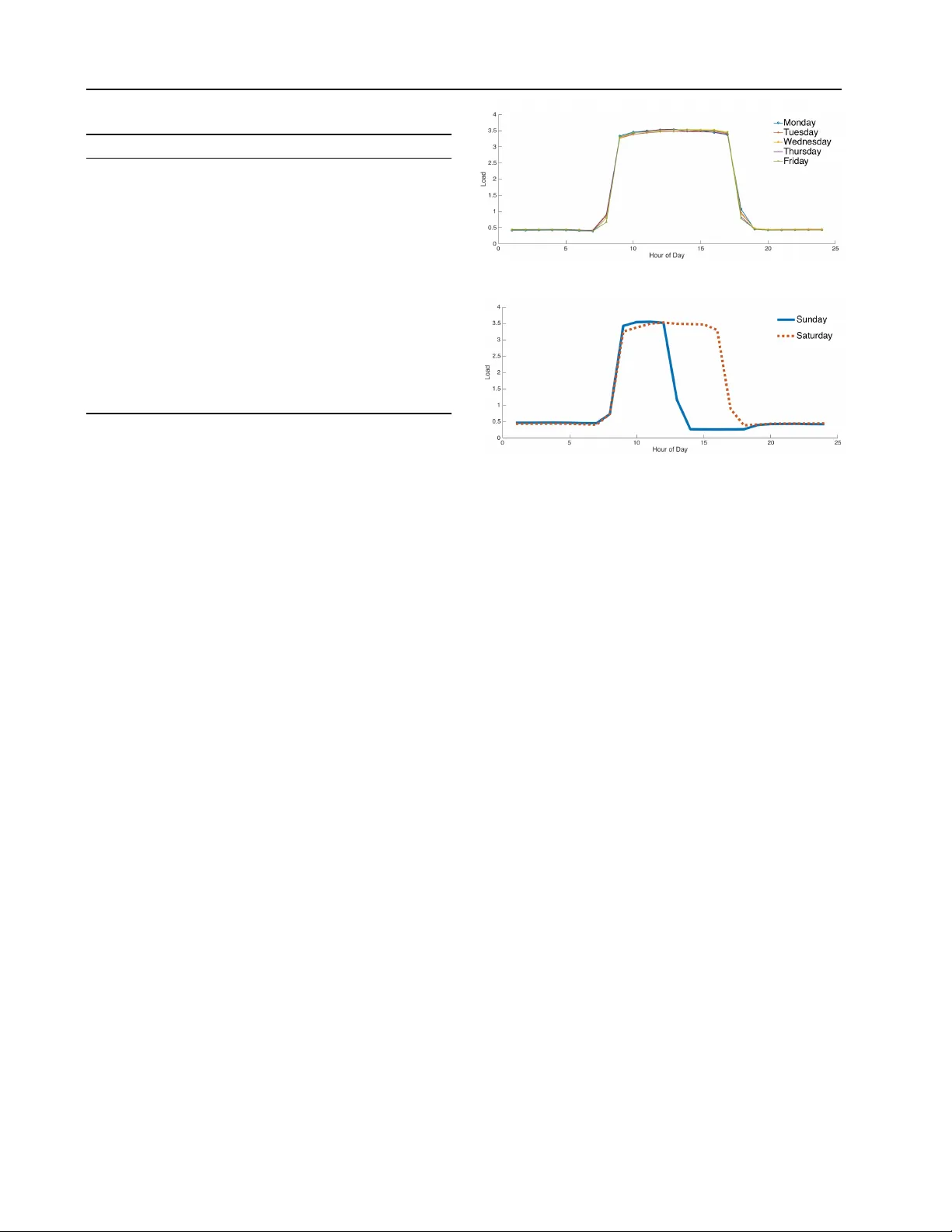
데이터는 트리니다드·토바고의 주거 가구에서 1년간 시간당 수집된 8,592개의 샘플과 18개의 특성(과거 부하값, 요일·시간·주말·공휴일 여부, 온도·습도 등)으로 구성된다. 특성 선택은 기존 STLF 연구에서 널리 사용된 변수들을 그대로 적용했으며, 데이터는 평균 0, 표준편차 1로 정규화하였다. 학습·검증·테스트 비율은 65:15:20이며, 주중·주말 데이터를 별도로 분리해 모델 성능 차이를 분석한다.
비교 대상은 전통적인 가중 이동 평균(WMA), 다중 선형 회귀(MLR), 2차 회귀(MQR), 회귀 트리(RT), 서포트 벡터 회귀(SVR)와, 딥러닝 계열인 다층 퍼셉트론(MLP), 사전학습 없는 DNN(DNN‑W), 사전학습된 스택드 오토인코더(DNN‑SA), 순환 신경망(RNN), 장기 기억 네트워크(LSTM), 합성곱 신경망(CNN) 및 CNN‑LSTM 하이브리드 모델을 포함한다. 전통 모델은 교차 검증을 통해 최적 하이퍼파라미터를 탐색했고, 딥러닝 모델은 무작위 그리드 서치를 이용해 레이어 수, 에포크 수(200·400), 은닉 뉴런 수 등을 조정하였다.
성능 평가는 평균 절대 백분율 오차(MAPE)와 평균 백분율 오차(MPE)를 사용한다. 결과는 표 1과 표 2에 정리된다. 전통 모델 중에서는 회귀 트리(RT)가 가장 낮은 MAPE(7.23%)를 기록했으며, MLR은 24.25%로 가장 부진했다. 딥러닝 모델은 전반적으로 우수했는데, DNN‑SA(3층, 400 에포크)가 MAPE 1.84%로 최고 성능을 보였으며, DNN‑W(3층)도 2.50% 수준을 기록했다. RNN·LSTM·CNN 계열은 정확도는 다소 낮지만(5~6% 수준) 학습 시간이 크게 늘어(수백 초) 실용성에 한계가 있다.
주중·주말 별 분석에서는 대부분의 딥러닝 모델이 주중에 더 낮은 MAPE를 보였으며, 이는 주중 데이터가 양적으로 풍부해 패턴 학습이 용이하기 때문이다. 반면 전통 모델은 특정 요일(예: 일요일)에 편향된 성능을 보여, 데이터 양과 분포에 민감함을 드러냈다. MPE 측면에서는 대부분의 딥러닝 모델이 약 0~1%의 양(언더프레딕션) 값을 보여, 전력 공급 측면에서 과잉 생산 위험을 최소화하는 데 도움이 될 수 있다.
논문은 이러한 예측 정확도가 전력 생산 계획과 동적 가격 책정에 어떻게 적용될 수 있는지를 논의한다. 정확한 부하 예측을 통해 발전소 가동 스케줄을 최적화하고, 피크 시기의 전기 요금을 상승시켜 소비자에게 전력 사용을 억제하도록 유도함으로써 전체 에너지 효율을 향상시킬 수 있다.
하지만 몇 가지 한계점도 지적한다. 첫째, 데이터가 열대 기후 지역에 국한돼 계절 변동이 큰 지역에 대한 일반화가 어려울 수 있다. 둘째, 딥러닝 모델의 학습 시간과 계산 자원 요구가 높아 실시간 재학습이 제한적이며, 클라우드 기반 가속이 필요하다. 셋째, 논문에서는 모델 초기화, 최적화 알고리즘, GPU 사양 등 재현성을 위한 상세 파라미터가 충분히 공개되지 않아, 동일 실험 재현에 어려움이 있다. 넷째, 전통 모델에 대한 상세 구현·하이퍼파라미터 설명이 부족해 직접 비교가 제한적이다.
결론적으로, 본 연구는 다양한 딥러닝 아키텍처가 전통적인 STLF 방법보다 높은 정확도를 달성함을 실증했으며, 특히 사전학습된 DNN‑SA가 가장 안정적인 성능을 보였다. 그러나 계산 비용·데이터 다양성·재현성 문제를 해결하기 위한 추가 연구가 필요하다. 향후 연구에서는 보다 다양한 기후·지역 데이터를 포함하고, 경량화된 딥러닝 모델(예: 모델 압축·지식 증류) 및 온라인 학습 기법을 도입해 실시간 적용 가능성을 높이는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기