다중해상도 순환 신경망을 이용한 대화 응답 생성
본 논문은 고수준의 ‘거친 토큰(명사·활동·엔티티 등)’과 저수준의 자연어 토큰을 동시에 모델링하는 다중해상도 순환 신경망(MrRNN)을 제안한다. 두 시퀀스를 공동 로그우도 최대화로 학습함으로써 장기 의존성과 대화 주제 구조를 효과적으로 포착한다. Ubuntu 기술 지원 대화와 Twitter 대화 두 도메인에서 기존 HRED·RNNLM 대비 자동 평가와 인간 평가 모두에서 우수한 성능을 보였다.
저자: Iulian Vlad Serban, Tim Klinger, Gerald Tesauro
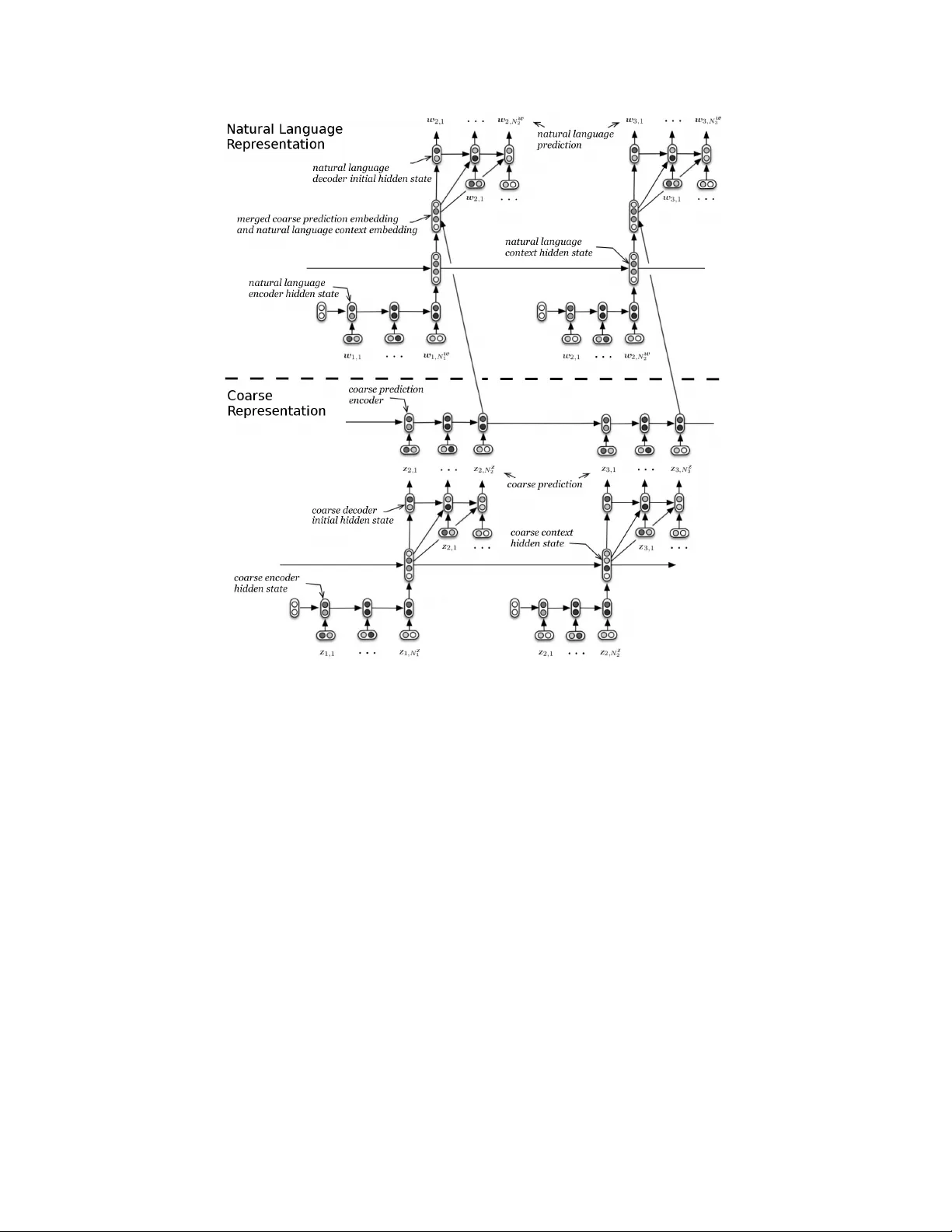
본 논문은 대화 응답 생성이라는 복합적인 자연어 생성 과제를 해결하기 위해 ‘다중해상도 순환 신경망(Multiresolution Recurrent Neural Network, MrRNN)’이라는 새로운 모델을 제안한다. 기존의 시퀀스‑투‑시퀀스 및 HRED 모델은 입력‑출력 토큰을 단일 흐름으로 처리해, 대화의 장기 구조와 고수준 의미를 포착하기 어려웠다. 이를 극복하고자 저자는 두 개의 평행 이산 시퀀스, 즉 고수준 ‘거친 토큰(coarse tokens)’과 저수준 ‘자연어 토큰(word tokens)’을 동시에 모델링한다. 거친 토큰은 발화에서 명사만을 추출하거나, Ubuntu 도메인에 특화된 활동(동사)·엔티티(소프트웨어·명령어) 집합을 이용해 자동으로 생성한다. 이 과정은 전처리 단계에서 POS 태거와 도메인 사전을 활용해 간단히 구현되며, 각 발화마다 하나의 거친 토큰 시퀀스가 대응한다.
모델 구조는 HRED를 기반으로 두 서브모델을 계층적으로 연결한다. 첫 번째 서브모델은 거친 토큰 시퀀스를 HRED‑형식으로 학습해 고수준 의도를 예측한다. 이때 코코스 프리딕션 인코더(GRU)는 이전에 생성된 모든 거친 토큰을 실시간으로 인코딩해 고수준 컨텍스트 벡터를 만든다. 두 번째 서브모델은 자연어 토큰을 HRED로 모델링하되, 위에서 얻은 고수준 컨텍스트 벡터를 디코더에 추가 입력으로 제공한다. 이렇게 하면 자연어 디코더는 ‘어떤 명사·동사를 포함해야 하는가’라는 고수준 제약을 받으며, 실제 단어를 순차적으로 생성한다.
학습 목표는 두 시퀀스에 대한 공동 로그우도(joint log‑likelihood)를 최대화하는 것이다. 이는 기존의 단일 시퀀스 로그우도(단어 퍼플렉시티 최소화)와 차별화되며, 파라미터가 고수준 추상에 더 큰 비중을 두도록 만든다. 최적화는 Adam을 사용하고, 조기 종료와 그래디언트 클리핑을 적용한다. 테스트 시에는 거친 토큰을 먼저 beam search(크기 5)로 생성하고, 그 결과를 조건으로 자연어 토큰을 다시 beam search로 생성한다.
실험은 두 도메인, Ubuntu 기술 지원 대화와 Twitter 일상 대화에 대해 수행되었다. Ubuntu 데이터는 0.5 M 대화, Twitter 데이터는 749 K 대화로 구성되며, 각각 훈련·검증·테스트 셋으로 분할된다. 베이스라인으로는 단일 RNNLM(LSTM)과 HRED(LSTM‑decoder, GRU‑encoder) 모델을 사용하였다. 평가 지표는 BLEU, METEOR, Recall@k 등 자동 지표와, Ubuntu에서는 인간 평가(적절성, 정보성)도 포함한다.
결과는 다음과 같다. Ubuntu에서는 MrRNN이 BLEU‑4에서 기존 HRED보다 약 12 % 향상되었으며, 인간 평가에서 ‘적절성’ 0.78, ‘정보성’ 0.71 등 현저히 높은 점수를 기록했다. 특히 Activity‑Entity 기반 거친 토큰이 가장 큰 성능 개선을 이끌었으며, 이는 도메인 지식이 고수준 토큰에 효과적으로 반영된 결과로 해석된다. Twitter에서는 명사 기반 거친 토큰이 주제 중심성을 강화해, BLEU‑4와 Recall@5에서 각각 1.8 %와 3.2 %의 개선을 보였다. 전반적으로 MrRNN은 희소한 단어 조합 문제를 완화하고, 장기 의존성을 더 잘 유지함으로써 대화 응답의 일관성과 관련성을 높였다.
논문의 주요 기여는 (1) 고수준 추상과 저수준 단어 흐름을 동시에 학습하는 다중해상도 확률 모델 제안, (2) 간단한 규칙 기반 추출 방법으로 거친 토큰을 자동 생성하고 이를 학습에 활용한 실용성, (3) 공동 로그우도 최적화를 통한 고수준 의미 편향 학습, (4) 두 가지 상이한 도메인에서의 실증적 성능 입증이다. 향후 연구에서는 거친 토큰을 자동 학습하거나, 강화학습과 결합해 대화 목표 달성률을 더욱 높이는 방안을 모색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기