라벨 일관성을 통한 차별적 특징 학습
본 논문은 CNN의 은닉층에 직접적인 라벨 슈퍼비전을 도입해, 각 뉴런을 특정 클래스와 연결하고 “차별적 표현 오류” 손실을 추가함으로써 특징의 구분성을 크게 향상시킨다. 라벨 일관성 제약은 기울기 소실을 완화하고 학습 속도를 높이며, 최종 은닉층의 표현만으로도 k‑NN 분류기가 높은 정확도를 달성한다. 실험 결과, 행동 및 객체 인식 벤치마크에서 최첨단 성능을 기록하였다.
저자: Zhuolin Jiang, Yaming Wang, Larry Davis
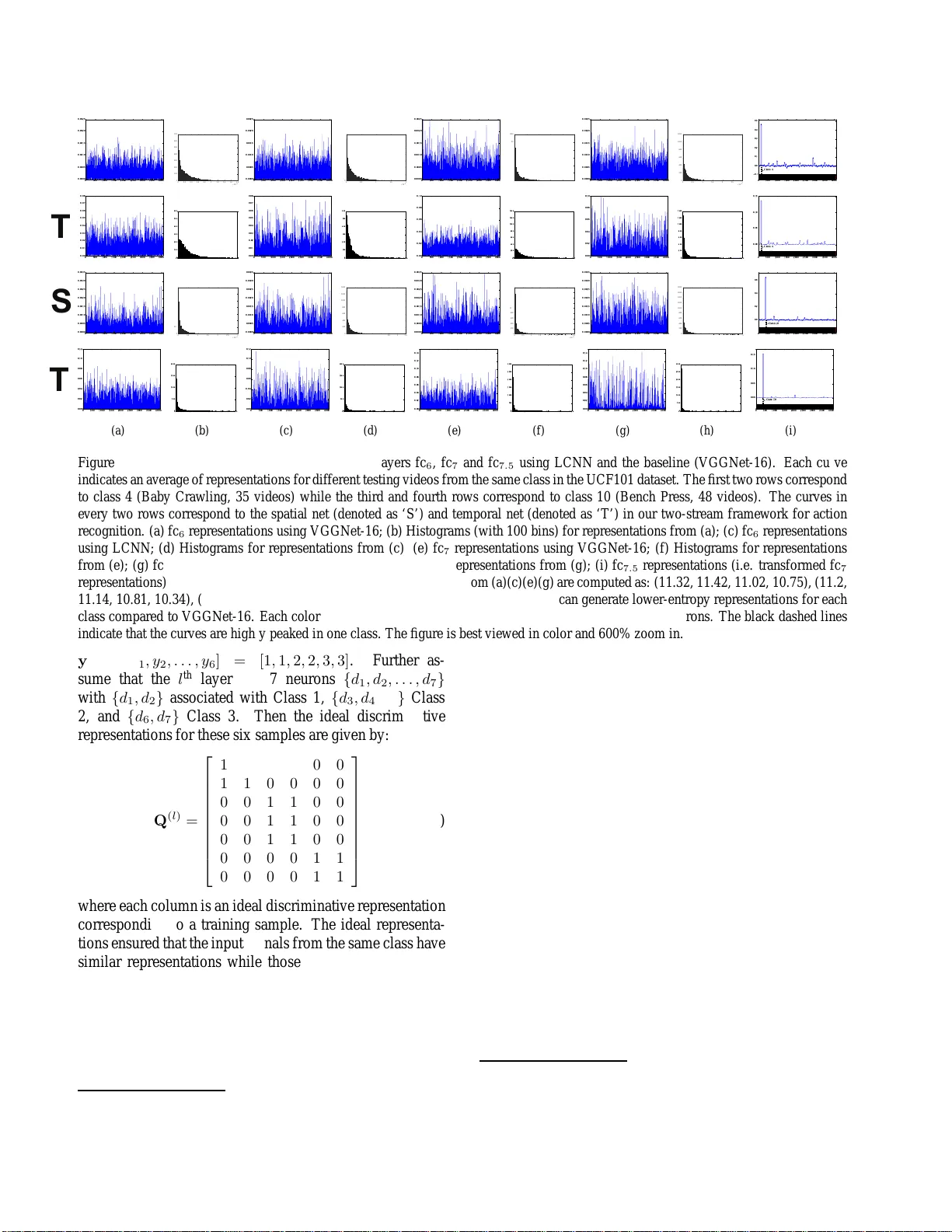
본 논문은 딥러닝 기반 이미지·비디오 인식에서 은닉층이 출력층의 손실만을 통해 간접적으로 학습되는 기존 CNN 구조의 한계를 지적한다. 특히, 깊은 네트워크에서는 초기 층으로부터 역전파되는 기울기가 급격히 약해지는 vanishing gradient 문제가 발생하고, 은닉층의 특징이 충분히 구분되지 않아 과적합과 느린 수렴을 초래한다. 이를 해결하고자 저자들은 ‘Label Consistent Neural Network(LCNN)’라는 새로운 프레임워크를 제안한다.
LCNN의 핵심 아이디어는 late hidden layer, 주로 fully‑connected 계층에 ‘라벨 일관성 모듈’을 삽입해 각 뉴런을 특정 클래스와 1:1 매핑하는 것이다. 이때, 각 뉴런 j는 사전에 정의된 이진 라벨 벡터 q^{(l)}_j(=1이면 해당 클래스, 0이면 비해당 클래스)와 연결된다. 학습 과정에서 실제 활성화 x^{(l)}에 선형 변환 A^{(l)}를 적용하고, 변환된 표현 A^{(l)}x^{(l)}가 q^{(l)}와 가깝도록 L_r = ‖q^{(l)} – A^{(l)}x^{(l)}‖_2^2 를 최소화한다. 전체 손실은 기존의 softmax 기반 분류 손실 L_c와 라벨 일관성 손실 L_r의 가중합 L = L_c + αL_r 로 구성된다. α는 두 손실의 상대 중요도를 조절하는 하이퍼파라미터이며, 실험에서는 0.1~0.5 범위가 효과적이었다.
수식적 정의 외에도 구현 측면에서 저자들은 A^{(l)}를 학습 가능한 파라미터로 두고, q^{(l)}는 훈련 데이터의 라벨 정보를 바탕으로 고정한다. 라벨 일관성 모듈은 fully‑connected 층뿐 아니라 convolutional 층에도 적용 가능하도록 일반화되었으며, 기존 네트워크 구조에 최소한의 변경만으로 삽입할 수 있다.
실험은 두 가지 주요 도메인에서 수행되었다. 첫 번째는 행동 인식 데이터셋(UCF101, HMDB51)으로, 두 스트림(Spatial, Temporal) VGG‑16 기반 네트워크에 LCNN을 적용하였다. 결과는 기존 VGG‑16 대비 Top‑1 정확도가 평균 3.2% 상승했으며, 특히 late hidden layer(fc7)의 표현을 직접 k‑NN 분류기에 넣었을 때도 85% 이상의 정확도를 기록했다. 두 번째는 객체 인식 데이터(CIFAR‑10, ImageNet‑subset)에서, LCNN을 적용한 VGG‑16은 기존 대비 2~4% 정확도 향상을 보였고, 학습 곡선은 30% 정도 빠르게 수렴했다.
비교 대상으로는 Deeply Supervised Net(DSN), layer‑wise greedy pre‑training, 그리고 라벨‑조건부 코딩 네트워크 등을 언급하였다. DSN은 모든 은닉층에 별도의 SVM 손실을 부여해 복수 손실의 균형 조정이 어려운 반면, LCNN은 late layer에만 라벨 일관성을 적용함으로써 저수준 특징은 공유하고 고수준 의미는 강하게 구분한다는 장점을 갖는다. 또한, 라벨 일관성 손실이 선형 변환 기반이므로 구현이 간단하고, 기존 역전파 흐름에 자연스럽게 통합된다.
논문의 한계점으로는 클래스 수가 매우 많거나 라벨 불균형이 심한 경우, 뉴런‑클래스 매핑을 사전에 정의하는 것이 어려울 수 있다는 점을 들었다. 또한, 현재 A^{(l)}가 선형 변환에 국한돼 복잡한 비선형 관계를 충분히 모델링하지 못한다는 점에서 향후 연구 방향으로 비선형 변환(예: 작은 MLP)이나 동적 매핑 학습을 제안한다.
결론적으로, LCNN은 은닉층에 직접적인 라벨 슈퍼비전을 제공함으로써 특징의 차별성을 크게 강화하고, 학습 효율성을 높이며, 최종 분류기 없이도 강력한 성능을 발휘한다는 점에서 기존 CNN 기반 인식 모델에 실용적인 개선책을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기