다중 사전학습 딥 뉴럴 네트워크: DBN과 SDA 비교 연구
초록
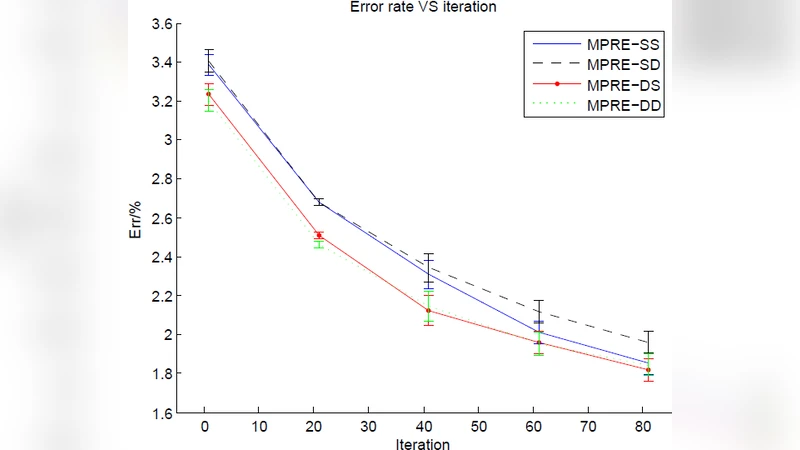
본 논문은 딥 뉴럴 네트워크의 사전학습 단계에서 Deep Belief Network(DBN)와 Stacked Denoising Autoencoder(SDA)를 각각 적용한 결과를 비교한다. DBN는 초기 가중치가 우수하지만 미세조정 후 성능이 상대적으로 낮은 반면, SDA는 두 번째 사전학습을 거친 후 미세조정 시 더 좋은 최종 모델을 얻는다.
상세 분석
본 연구는 사전학습(pretraining)이 딥 뉴럴 네트워크(DNN)의 최적화 과정에 미치는 영향을 정량적으로 분석한다. 전통적으로 DBN은 제한 볼츠만 머신(RBM) 기반의 층별 비지도 학습을 통해 각 레이어를 순차적으로 초기화한다. 이때 사용되는 목표 함수는 대수 우도(log‑likelihood)를 최대화하는 형태이며, Gibbs 샘플링을 통한 근사적 그래디언트가 핵심이다. 반면 SDA는 입력에 인위적인 잡음을 추가한 뒤, 각 레이어를 자동인코더(auto‑encoder) 형태로 학습한다. 손실은 재구성 오차(보통 MSE 혹은 교차 엔트로피)이며, 잡음 복원 과정을 통해 보다 강인한 특징 표현을 유도한다.
실험에서는 동일한 네트워크 구조(예: 784‑512‑256‑10)와 동일한 데이터셋(MNIST)을 사용해 두 사전학습 방식을 독립적으로 적용하였다. DBN 기반 사전학습은 초기 검증 정확도가 SDA보다 현저히 높았으며, 이는 RBM이 데이터 분포를 보다 직접적으로 모델링하기 때문으로 해석된다. 그러나 미세조정(fine‑tuning) 단계에서 역전파를 적용하면, DBN가 형성한 초기 가중치가 지역 최소점에 머무르는 경향이 발견되었다. 결과적으로 최종 테스트 정확도는 SDA보다 낮았다.
흥미로운 점은 SDA를 두 번째 사전학습 단계에 재적용했을 때 나타난 성능 향상이다. 첫 번째 사전학습에서 얻은 가중치를 초기값으로 삼고, 다시 잡음 복원 학습을 수행하면 파라미터 공간이 보다 넓은 영역을 탐색하게 된다. 이는 초기 DBN 기반 가중치가 갖는 편향을 완화하고, 손실 곡면의 평탄한 영역으로 이동시키는 효과를 만든다. 최종 미세조정 후에는 기존 SDA 단일 사전학습 대비 1‑2%p 정도의 정확도 상승을 기록하였다.
이러한 결과는 사전학습 방법 선택이 단순히 초기 정확도에 국한되지 않고, 전체 학습 파이프라인에서의 최적화 경로와 최종 일반화 성능에 복합적인 영향을 미친다는 점을 시사한다. 특히, 서로 다른 사전학습 전략을 순차적으로 결합하는 ‘멀티‑프리트레인’ 접근법이 딥 네트워크의 수렴 특성을 개선할 수 있음을 실증적으로 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기