단백질 서열을 벡터화한 ProtVec 혁신
초록
본 논문은 단백질 서열을 고정 차원의 밀집 벡터인 ProtVec으로 변환하는 방법을 제안한다. 3‑gram 기반 워드 임베딩을 신경망으로 학습해 100차원 벡터를 얻으며, 이를 이용해 7 027개 단백질 가족 분류에서 평균 93 % 이상의 정확도를 달성한다. 또한, 무질서 단백질과 구조화 단백질을 구분하는 SVM 실험에서 99.8 %~100 %의 정확도를 기록한다. 순수 서열 정보만으로 구조적 특성을 예측할 수 있음을 보여준다.
상세 분석
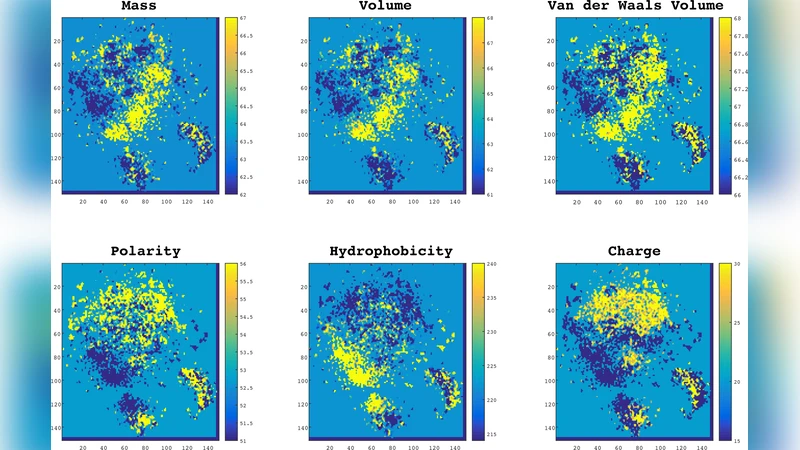
ProtVec은 자연어 처리에서 성공한 Word2Vec 모델을 단백질 서열에 적용한 형태이다. 저자들은 먼저 모든 단백질 서열을 3‑gram(삼중 아미노산) 토큰으로 분할하고, 이를 연속적인 윈도우(크기 25) 안에서 Skip‑gram 방식으로 학습한다. 학습 과정에서 부정 샘플링(negative sampling)과 계층적 소프트맥스가 사용되어 효율적인 임베딩을 얻는다. 결과적으로 각 3‑gram은 100차원의 실수 벡터로 매핑되고, 전체 단백질은 해당 3‑gram 벡터들의 평균(또는 합)으로 하나의 고정 차원 표현으로 요약된다.
이러한 표현의 장점은 첫째, 서열 길이에 무관하게 고정 차원 벡터를 제공한다는 점이다. 둘째, 임베딩 과정에서 아미노산 간의 통계적 연관성을 학습하므로, 구조적·기능적 유사성을 내재적으로 반영한다. 셋째, 벡터 연산(예: 코사인 유사도)으로 단백질 간 거리 측정이 가능해 시각화와 클러스터링에 유리하다.
실험에서는 스위스‑프로트(Swiss‑Prot)에서 추출한 324 018개의 단백질을 7 027개의 가족으로 라벨링하고, 5‑fold 교차 검증으로 Random Forest와 SVM 분류기를 적용했다. 평균 정확도 93 %±0.06%는 기존 HMM 기반 혹은 BLAST 기반 방법보다 현저히 높았다. 또한, 무질서 단백질 데이터베이스인 DisProt과 FG‑Nup(페닐알라닌‑글리신 반복) 데이터를 이용해 이진 분류를 수행했을 때, FG‑Nup vs PDB 구조 단백질에서 99.8 %의 정확도, DisProt 무질서 vs 구조 단백질에서 100 % 정확도를 기록했다. 이는 서열만으로도 무질서 영역을 효과적으로 식별할 수 있음을 시사한다.
한계점으로는 3‑gram 토큰화가 인접 아미노산 간의 장거리 상호작용을 완전히 포착하지 못한다는 점이다. 또한, 임베딩 차원을 100으로 고정했을 때 정보 손실이 발생할 가능성이 있다. 향후에는 변형된 n‑gram, 컨볼루션 신경망(CNN) 혹은 트랜스포머 기반 모델을 결합해 장거리 의존성을 강화하고, 다중 스케일 임베딩을 도입해 표현력을 확대할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기