탐험과 활용을 동시에 잡는 인포맥스 전략
본 논문은 다중 슬롯머신(멀티-암드 밴딧) 문제에 인포맥스 원리를 적용한 두 가지 전략, Info‑p와 Info‑id를 제안한다. Info‑p는 각 팔의 성공 확률 중 최고값에 대한 정보를 최대화하도록 설계돼, 라이‑로빈스(Lai‑Robbins) 하한을 포화함으로써 점근적으로 최적임을 증명한다. 반면 Info‑id는 최적 팔의 정체성을 파악하는 데 초점을 맞추지만 보상 측면에서는 차감된다. 실험 결과 Info‑p는 기존 UCB·KL‑UCB·DM…
저자: Gautam Reddy, Antonio Celani, Massimo Vergassola
논문은 인포맥스(Infomax) 원리를 다중 슬롯머신(멀티‑암드 밴딧) 문제에 적용해 탐험‑활용 트레이드오프를 정량적으로 분석한다. 서론에서는 샤논의 정보 이론이 의미를 배제하고 통계적 특성만을 다루는 점을 강조하며, 생물학·경제·신경과학 등 다양한 분야에서 정보와 보상의 관계가 연구돼 왔음을 언급한다. 특히 켈리(Kelly) 베팅 이론이 정보와 성장률 사이의 경계를 제시했으며, 효율 코딩 이론이 신경계에서 정보 효율성을 최적화한다는 점을 인용한다. 이러한 배경을 바탕으로, 정보가 항상 보상 최적화와 일치하지 않을 수 있음을 지적하고, 정보 획득 비용과 행동 선택에 따른 기회비용을 고려한 균형이 필요함을 제시한다.
다음으로 밴딧 문제의 정의와 기존 최적 이론을 정리한다. K개의 베르누이 팔이 각각 미지의 성공 확률 p_i 를 가지고 있으며, 목표는 누적 보상을 최대화하거나 기대 후회 R을 최소화하는 것이다. 라이‑로빈스(Lai‑Robbins) 하한은 n_i ≥ (ln n)/D(p_i, p_1) 로, 여기서 D는 KL‑다이버전스이며, 이 하한을 만족하는 정책을 점근적 최적이라고 부른다. 기존 최적 정책으로는 할인 보상에 대한 Gittins 인덱스와, 비할인 상황에서의 UCB·KL‑UCB·DMED 등이 있다.
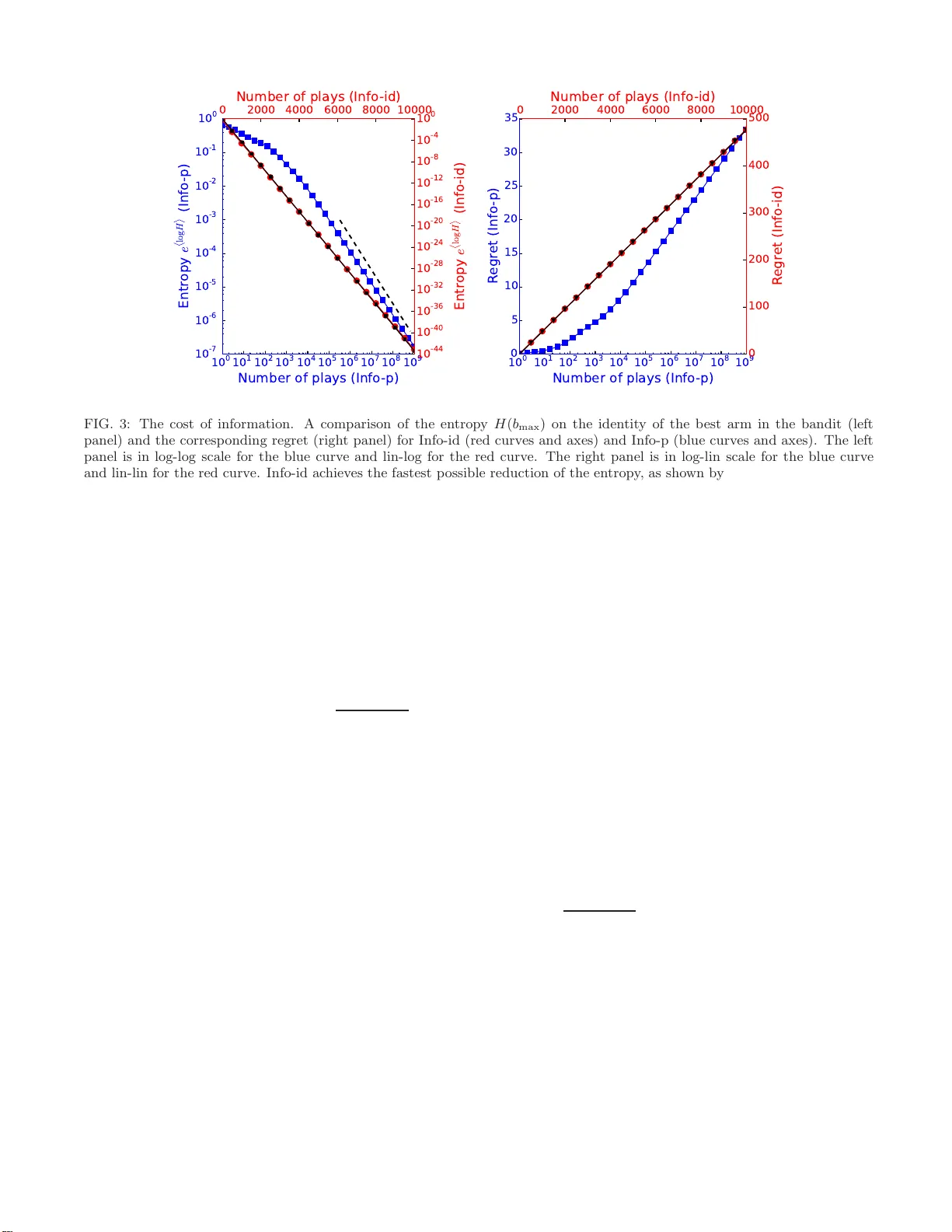
본 연구는 두 가지 인포맥스 전략을 제안한다. 첫 번째인 Info‑p는 각 팔의 사후 베타 분포 P_i(π_i) 를 기반으로, “가장 큰 성공 확률” π_max = max_i π_i 의 연속 확률밀도 ρ(π_max) 를 계산한다. 엔트로피 H(π_max) = ‑∫ρ ln ρ 를 정의하고, 한 번의 팔 선택이 가져올 기대 엔트로피 감소 ΔH_i 를 (5) 식으로 구한다. 이때 관측 결과(성공/실패)별 사후 업데이트를 수행하고, 새로운 ρ를 재계산한다. 기대 감소가 큰 팔을 선택함으로써 탐험과 활용을 동시에 조정한다.
수학적 분석에서는 대수적 전개와 대수적 대수정리(central limit theorem)·대편차 이론(large deviations)을 활용한다. ρ(π_max)의 좌측은 주로 최적 팔의 베타 분포에 의해 지배되고, 우측 꼬리는 열등한 팔의 샘플 평균이 최적 팔보다 크게 나타날 확률, 즉 e^{‑n_2 D(π̂_2, π̂_1)} 로 표현된다. 엔트로피는 두 항, 즉 탐색 항(σ_1^2 ∝ 1/n_1)과 탐험 항(∝ e^{‑n_2 D}) 로 분리된다. 두 항의 기대 감소가 동일해지는 경계는 ln n ≈ n_2 D(π̂_2, π̂_1) 로, 이는 라이‑로빈스 하한과 동일함을 보인다. 따라서 Info‑p는 점근적으로 최적이며, 실제 시뮬레이션에서도 로그 규모의 후회가 하한에 근접한다.
두 번째 전략인 Info‑id는 “최적 팔이 무엇인가”라는 이산 변수의 엔트로피를 최소화한다. 이는 π_max 대신 최적 팔 인덱스에 대한 사후 확률을 사용한다. 결과적으로 탐험이 과도하게 진행돼 보상 효율은 떨어지지만, 최적 팔 식별 속도는 최고 수준이다.
실험에서는 p_1 = 0.9, p_2 = 0.8 인 2‑armed 베르누이 밴딧을 설정하고, 10^9 회까지 시뮬레이션을 수행했다. Info‑p는 UCB‑Tuned, UCB2, KL‑UCB 등과 비교해 평균 후회가 로그 스케일에서 동일한 기울기를 보이면서, 특히 n ≈ 10^5 ~ 10^7 구간에서 가장 낮은 후회를 기록했다. DMED, Kelly 비례 베팅, 전통적 UCB 인덱스와도 비슷하거나 더 나은 성능을 보였다. 또한, Info‑p의 후회는 O(ln ln n) 수준의 부차항을 갖는 것으로 확인돼, 실용적인 중간 시간에서도 우수함을 입증한다.
결론적으로, “가장 큰 평균 보상”이라는 통계량에 대한 정보 획득을 최적화하는 것이 탐험‑활용 문제에 있어 근본적인 해결책이 될 수 있음을 보여준다. 이는 정보 이론과 강화 학습 사이의 교차점을 명확히 하며, 라그랑주 승수 형태의 최적 조건이 기존 이론적 한계와 일치한다는 점에서 학문적·실용적 의의가 크다. 향후 연구에서는 다중 팔(K>2) 상황, 비베르누이 보상, 그리고 정보 획득 비용을 명시적으로 모델링한 확장에 대한 탐구가 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기