깊이의 힘 3층 신경망이 2층을 능가하는 이유
초록
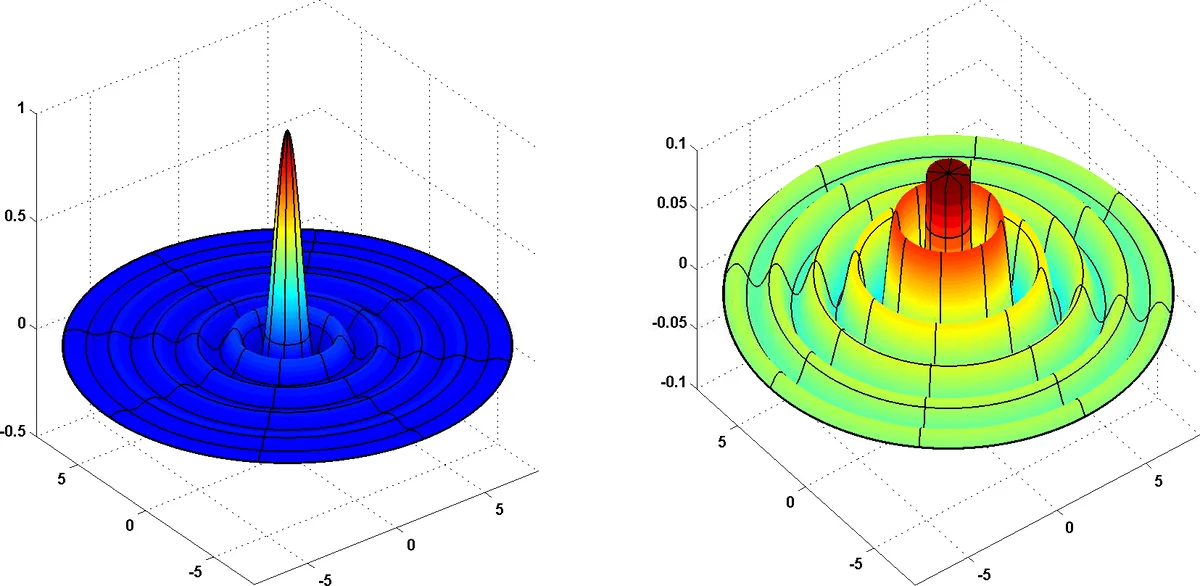
이 논문은 폭이 다항식 수준인 3층 완전 연결 피드포워드 신경망이 반경형(approximately radial) 함수를 효율적으로 구현할 수 있지만, 동일한 함수를 2층 네트워크가 근사하려면 차원 d에 대해 지수적인 폭이 필요함을 증명한다. 결과는 ReLU, 시그모이드, 임계값 등 대부분의 일반적인 활성화 함수에 적용되며, 깊이가 폭보다 훨씬 강력한 표현력을 가질 수 있음을 이론적으로 뒷받침한다.
상세 분석
본 연구는 “깊이와 폭의 트레이드오프”라는 핵심 질문에 대해 매우 구체적인 수학적 증명을 제공한다. 먼저 저자들은 활성화 함수 σ가 두 가지 약한 가정(보편적 근사 가능성 및 다항 성장)을 만족하면, 폭이 O(poly(d))인 3층 네트워크가 반경형 함수 g(x)=h(‖x‖²) 를 구현할 수 있음을 보인다. 여기서 h는 1차원 Lipschitz 함수이며, σ의 1층 근사 능력을 이용해 ‖x‖² 를 근사한 뒤, 2층에서 h를 적용한다. 반면 2층 네트워크는 입력과 선형 결합된 σ의 출력만을 한 번에 합산하므로, 동일한 반경형 구조를 만들기 위해서는 각 좌표별로 σ를 여러 번 사용해야 한다. 저자들은 이를 Fourier 분석과 확률적 측면에서 정량화한다. 구체적으로, 입력 분포 μ를 ‖x‖² 의 역푸리에 변환 ϕ²(x) 로 정의하고, L₂(μ) 오차 ‖f−g‖²_μ 를 푸리에 변환 공간에서 ‖ĥ_f−ĥ_g‖²_L₂ 로 변환한다. 2층 네트워크의 푸리에 변환은 제한된 차원의 선형 부분공간에만 지원되므로, 고차원 구형 영역에서의 ϕ와 겹치는 부분이 매우 작다. 이로 인해 ‖f−g‖²_μ 은 상수 c>0 이하로 감소하지 못하고, 정확히 말하면 폭이 exp(Ω(d)) 수준이어야만 오차를 임의로 작게 만들 수 있다. 중요한 점은 이 하한이 활성화 함수의 구체적 형태에 크게 의존하지 않는다는 것이다. ReLU, 시그모이드, 하드 스텝 등 대부분의 실용적 활성화 함수가 가정 1·2를 만족하므로, 결과는 넓은 범위의 네트워크에 적용된다. 또한 파라미터 크기에 대한 제한을 두지 않아, 기존의 Boolean 회로 결과와 달리 실수값 네트워크에서도 동일한 깊이‑폭 분리 현상이 나타남을 보인다. 논문은 기존 연구와 비교해 두드러진 차별점을 가진다. 이전에는 깊이‑폭 차이가 다층(예: k층) 네트워크 사이에서만 지수적 분리가 알려졌으며, 함수의 Lipschitz 상수가 매우 크게 설정돼야 했다. 여기서는 단 2층과 3층 사이에서, 그리고 함수의 Lipschitz 상수가 다항식 수준인 경우에도 지수적 차이가 발생한다는 점이 혁신적이다. 마지막으로, 저자들은 가정 1을 약화시켜 폭이 poly(R,L,1/δ) 수준이 되도록 할 수 있음을 언급하며, 차원 의존성에 대한 정밀한 상수도 제시한다. 전체적으로 이 논문은 깊이가 하나만 늘어나도 표현력에 있어 폭을 지수적으로 초과할 수 있음을 엄밀히 증명함으로써, 깊이의 본질적 가치를 이론적으로 확립한다.
댓글 및 학술 토론
Loading comments...
의견 남기기