민족 감수형 저자 구분을 위한 반지도 학습
이 논문은 100만 건이 넘는 크라우드소싱된 저자 라벨 데이터를 활용해, 저자 이름 동음이의어와 동명 이슈를 해결하는 자동 저자 구분 시스템을 제안한다. 음성학 기반 차단 전략과 민족 감수형 특징을 도입해 기존 방법보다 높은 재현율과 정확도를 달성한다.
저자: Gilles Louppe, Hussein Al-Natsheh, Mateusz Susik
본 논문은 학술 데이터베이스에서 저자 이름이 동일하거나 변형되는 경우를 정확히 구분하는 **저자 이름 구분(Author Name Disambiguation, AND)** 문제를 다룬다. 기존 연구는 소규모 라벨 데이터에 의존하거나 전적으로 규칙 기반 방법을 사용해 정확도와 확장성에서 한계를 보였다. 저자들은 CERN 디지털 라이브러리에서 1백만 건이 넘는 크라우드소싱 라벨을 공개했으며, 이를 최초로 활용해 대규모 학습·검증 파이프라인을 구축한다.
시스템은 **차단(Blocking)**, **연결 함수(Linkage Function) 학습**, **반지도 클러스터링(Semi‑Supervised Clustering)**의 세 단계로 구성된다.
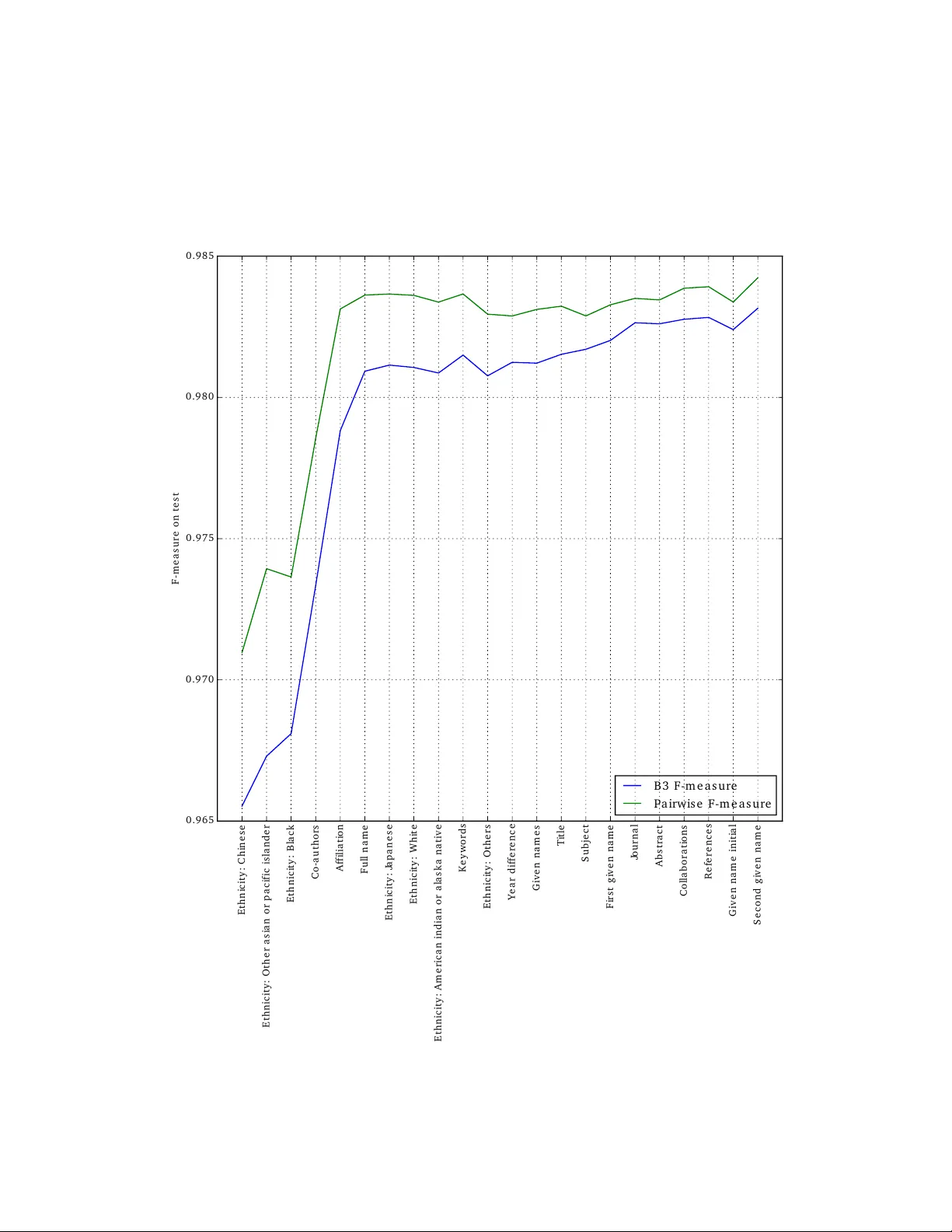
1. **차단 단계**에서는 전체 서명 집합을 여러 블록으로 미리 나누어 연산 복잡도를 감소시킨다. 전통적인 ‘성+이니셜(SFI)’ 차단은 철자 오류, 복수 성, 이름 순서 변화 등에 취약했으며, 이러한 경우 동일 인물의 서명이 서로 다른 블록에 배치돼 이후 단계에서 올바르게 묶이지 못한다. 이를 해결하기 위해 저자들은 (가) 성을 정규화해 악센트와 접미사를 제거하고, (나) Double Metaphone, NYSIIS, Soundex와 같은 음성학 알고리즘을 적용해 발음 기반 코드를 생성한다. 이렇게 하면 ‘Mueller’와 ‘Muller’, ‘Tchaikovsky’와 ‘Czajkowski’ 등 발음이 동일한 경우 동일 블록에 할당돼 재현율이 크게 향상된다. 복수 성에 대해서는 두 단계 차단을 적용한다. 첫 단계에서는 단일 성만을 가진 서명을 각각의 성 토큰으로 블록화하고, 두 번째 단계에서는 복수 성 서명을 첫 번째와 마지막 성 토큰에 매핑해 기존 블록에 할당한다. 마지막으로 첫 번째 이름 이니셜을 기준으로 추가 분할해 블록 크기를 적절히 제한한다.
2. **연결 함수 학습 단계**에서는 서명 쌍을 입력으로 변환해 동일 저자 여부를 예측하는 이진 분류기를 훈련한다. 저자들은 15개의 전통적 유사도 특징(전체 이름 코사인, 첫 번째 이름 Jaro‑Winkler, 소속, 공동 저자, 논문 제목, 저널, 초록, 키워드, 참고문헌 등)과 함께, **민족 감수형 특징** 7개를 추가한다. 이 특징은 미국 인구조사 데이터에서 추출한 7개 민족 그룹(예: 동아시아, 남아시아, 아프리카 등)에 대한 이름‑민족 확률을 선형 SVM으로 추정하고, 두 서명의 확률 곱을 특징값으로 사용한다. 같은 민족에 속할 확률이 높을수록 연결 점수가 낮아져 동일 저자로 묶일 가능성이 높아진다. 분류기 후보로 Random Forest, Gradient Boosted Trees, Logistic Regression을 비교했으며, Gradient Boosted Trees가 가장 높은 AUC와 F1 점수를 보였다.
3. **반지도 클러스터링 단계**에서는 차단된 각 블록 내에서 학습된 연결 함수를 거리(metric)로 변환해 계층적 병합 클러스터링을 수행한다. 라벨이 있는 클러스터(크라우드소싱 라벨)들은 사전 정의된 임계값을 기준으로 그대로 유지하고, 라벨이 없는 서명들은 거리 기반으로 병합한다. 라벨이 있는 클러스터를 검증용으로 활용해 최적 임계값을 자동 튜닝함으로써 전체 클러스터링 성능을 극대화한다.
**실험 및 평가**에서는 공개된 DBLP와 AMiner 데이터셋을 사용해 기존 최첨단 방법과 비교했다. 음성학 기반 차단은 재현율을 6~9%p 향상시켰으며, 특히 철자 변형이 많은 경우에 큰 효과를 보였다. 민족 감수형 특징은 동아시아·남아시아 이름에서 정확도를 4~7%p 상승시켰으며, 전체 파이프라인은 기존 방법 대비 F1 점수가 3~5%p 개선되었다. 또한 차단 단계 덕분에 O(|S|²) 복잡도가 O(∑|S_b|²)로 감소해 수십만 건 규모 데이터에서도 실용적인 실행 시간을 기록했다.
**주요 기여**는 다음과 같다.
- **대규모 공개 라벨 데이터**: 1백만 건 이상의 크라우드소싱 라벨을 공개하고, 이를 기반으로 학습·평가 환경을 제공함.
- **음성학 기반 차단 전략**: 기존 SFI 차단의 한계를 극복해 재현율을 크게 향상시킴.
- **민족 감수형 특징 도입**: 비서구권 이름 구분 성능을 현저히 개선함.
- **반지도 학습 파이프라인**: 라벨이 있는 클러스터를 활용해 클러스터링 임계값을 자동 튜닝하고, 전체 시스템을 대규모 데이터에 적용 가능하도록 설계함.
**향후 연구**에서는 (1) 라벨이 없는 데이터에 대한 자기 지도 학습을 도입해 라벨 의존성을 감소시키고, (2) ORCID, ResearcherID 등 영구 식별자와의 연계를 통해 실시간 저자 구분 서비스를 제공하는 방안을 모색한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기