컨셉 기반 문장 재정렬로 이미지 캡션 품질 향상
초록
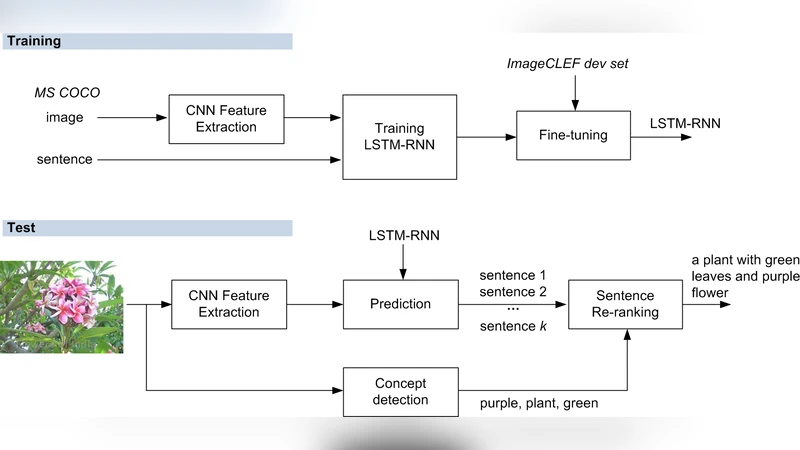
본 논문은 Google의 CNN‑LSTM 이미지 캡션 모델에 ‘컨셉 기반 문장 재정렬(concept‑based sentence reranking)’ 기법을 추가하여 ImageCLEF 2015 캡션 생성 대회에서 우승한 방법을 제시한다. Flickr에 존재하는 대규모 태그(컨셉) 데이터를 활용해 이미지에 대한 컨셉을 자동 검출하고, 생성된 후보 문장들의 점수를 컨셉 매칭 정도와 결합해 재정렬한다. 또한, 사전 학습된 CNN‑LSTM 모델을 ImageCLEF 데이터에 미세 조정(fine‑tuning)함으로써 성능을 추가로 끌어올렸다. 최종 시스템은 METEOR 0.1875를 기록, 2위(0.1687)와 큰 격차를 보였다.
상세 분석
이 연구는 이미지 캡션 생성 모델을 ‘블랙 박스’로 취급하면서도 외부 컨셉 정보를 효과적으로 결합하는 두 단계 접근법을 제안한다. 첫 번째 단계는 기존의 CNN‑LSTM 구조를 그대로 사용해 각 이미지에 대해 k개의 후보 문장을 생성한다. 여기서 k는 빔 서치(beam search)로 얻은 상위 후보이며, 각 후보는 모델 자체가 부여한 확률 점수(sentScore)와 연관된다. 두 번째 단계에서는 Flickr 이미지에 부착된 대규모 태그 데이터를 이용해 이미지‑컨셉 매칭을 수행한다. 논문에서는 두 가지 컨셉 검출 방법을 실험했는데, (1) Neighbor Voting(NeiVote)은 시각적 유사도에 기반해 근접 이미지들의 태그를 집계해 상위 m개의 컨셉을 추출하고, (2) Hierarchical Semantic Embedding(HierSE)은 Word2Vec 기반의 의미 임베딩을 활용해 이미지와 컨셉 사이의 코사인 유사도를 계산한다. 검출된 컨셉이 후보 문장에 포함될 경우, 해당 문장의 concScore를 평균 컨셉 신뢰도로 정의한다. 최종 재정렬 점수는 newScore = θ·concScore + (1‑θ)·sentScore 로 선형 결합되며, θ는 검증 셋을 통해 튜닝한다. 이 간단한 가중합 방식임에도 불구하고, 컨셉 매칭이 높은 문장이 실제로 이미지 내용을 더 정확히 서술한다는 가정을 검증하였다.
실험에서는 먼저 MS‑COCO 데이터로 사전 학습한 CNN‑LSTM 모델을 ImageCLEF dev 셋에 낮은 학습률로 미세 조정한 뒤, 컨셉 재정렬을 적용했다. 미세 조정만으로도 METEOR 0.1759에서 0.1875까지 상승했으며, 특히 NeiVote 기반 재정렬이 HierSE보다 일관적으로 좋은 결과를 보였다. 이는 Flickr 태그가 실제 캡션에 사용되는 어휘와 높은 일치성을 갖기 때문으로 해석된다. 또한, 미세 조정 없이도 재정렬만으로 성능이 크게 개선돼, 컨셉 기반 재정렬이 모델 자체의 구조적 한계를 보완한다는 점을 시사한다.
이 방법의 강점은 (1) 기존 캡션 모델을 그대로 재사용할 수 있어 구현 비용이 낮다, (2) 대규모 약한 라벨(태그) 데이터를 활용해 추가적인 인간 주석 없이도 성능을 끌어올릴 수 있다, (3) 재정렬 단계가 독립적이므로 다른 최신 모델(LSTM 외에도 Transformer 기반 모델)에도 쉽게 적용 가능하다는 점이다. 반면, 컨셉 검출 정확도가 낮을 경우 오히려 재정렬이 부정적인 영향을 미칠 수 있으며, θ 값에 대한 민감도가 존재한다는 제한점이 있다. 또한, 현재는 후보 문장을 제한된 수(k)만 고려하므로, 더 풍부한 후보 풀을 활용하거나 다중 후보를 동시에 평가하는 확장 가능성도 남아 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기