대규모 네트워크를 위한 하한 기반 링크 예측과 효율적 CN 계산
초록
본 논문은 공통 이웃(CN) 값의 하한 L을 설정해 CN가 L보다 큰 노드 쌍만을 대상으로 하여, MapReduce 기반 병렬 알고리즘으로 대규모 이질 네트워크에서 빠르게 링크 예측을 수행한다. 또한 CN 기반 지표의 성능을 측정하는 ‘자기예측성(self‑predictability)’ 지표를 제안한다.
상세 분석
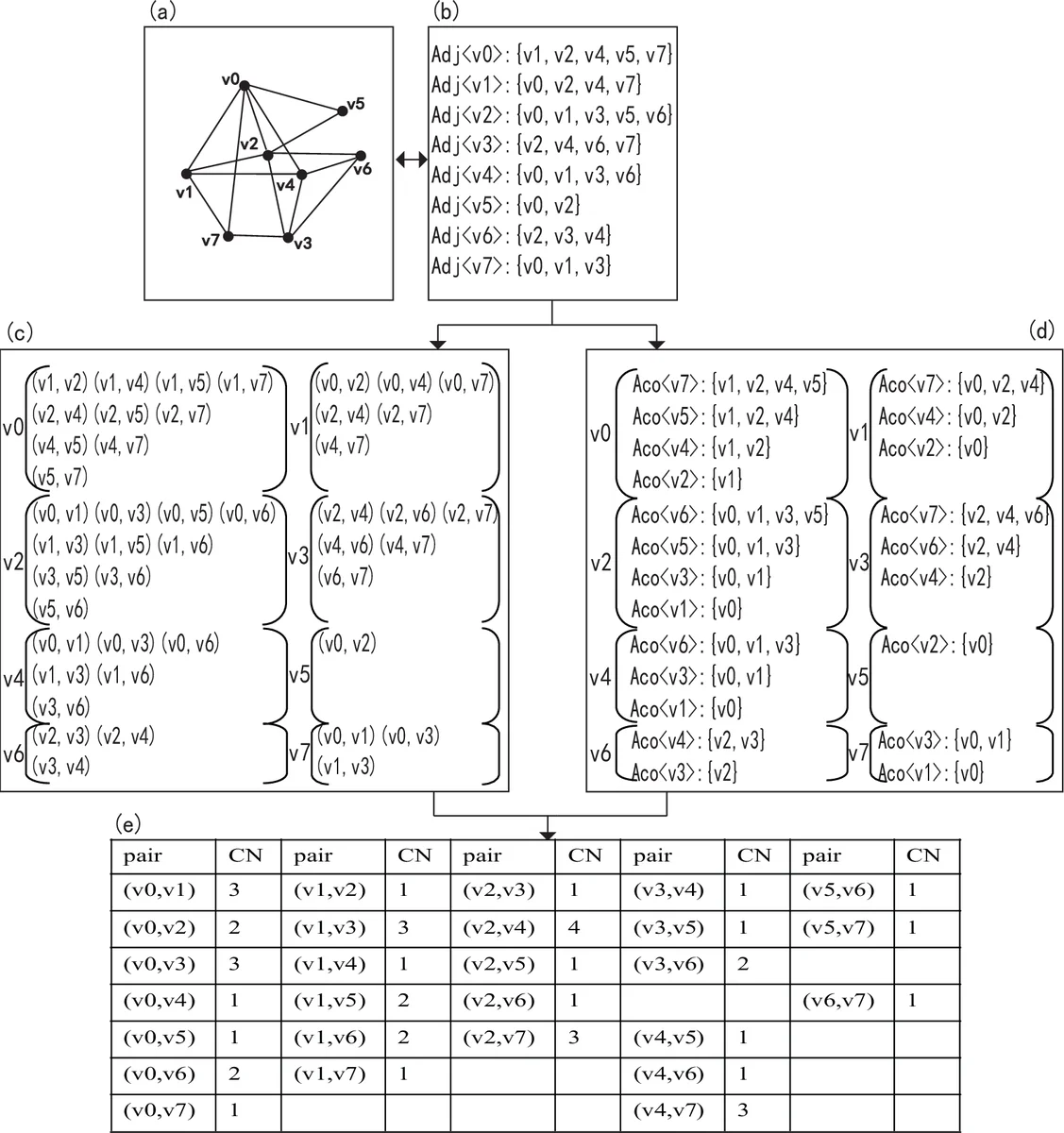
이 연구는 기존의 CN 기반 링크 예측이 O(|V|³) 혹은 최소 Ω(|V|²)의 복잡도를 갖는 점을 지적하고, 실제 대규모 네트워크에서는 대부분의 노드 쌍이 매우 작은 CN 값을 가진다는 사실을 실증한다. 이를 활용해 저자는 두 가지 핵심 아이디어를 제시한다. 첫째, CN 하한 L을 도입해 L 이하인 모든 노드 쌍을 사전에 필터링함으로써 연산량을 급격히 감소시킨다. 이때 L은 “핫” 노드(고도 연결된 노드) 사이의 잠재적 연결을 포착하기에 충분히 낮게 설정한다. 둘째, 두 개의 수학적 보조정리(Lemma 1, 2)를 이용해 필터링 과정을 효율적으로 구현한다. Lemma 1은 차수가 L보다 큰 노드는 그 자체가 L 이상의 CN을 만들 수 없으므로 해당 노드가 포함된 모든 쌍을 제외한다는 내용이며, Lemma 2는 차수가 L 이하인 노드가 L개 이하의 인접 리스트에만 등장하면 역시 L 이상의 CN을 만들 수 없으므로 추가 필터링이 가능함을 보인다.
알고리즘은 전통적인 MapReduce 기반 ‘pair‑generating’과 ‘vectorization’ 방식을 그대로 사용하되, 위 두 레마를 적용해 입력 데이터(노드 인접 리스트)를 사전 정제한다. Map 단계에서는 각 노드의 인접 리스트를 읽어 인접 노드 쌍을 생성하고, Reduce 단계에서는 동일 키(노드 쌍)의 값을 누적해 CN 값을 계산한다. 필터링 덕분에 Map 단계에서 전송되는 키‑값 쌍의 수가 크게 줄어들어 네트워크 규모가 수백만 노드에 달해도 메모리와 통신 비용이 실용적인 수준으로 유지된다.
또한 논문은 기존의 정밀도(precision)와 AUC와 같은 평가 지표가 대규모 희소 그래프에서 의미가 약해지는 문제를 지적하고, ‘자기예측성(self‑predictability)’이라는 새로운 메트릭을 도입한다. 이는 “CN > L인 노드 쌍 중 실제로 존재하는 링크 비율”을 직접 측정함으로써, CN 기반 지표가 해당 네트워크에서 얼마나 예측력을 갖는지를 정량화한다. 실험 결과, 여러 실제 네트워크(소셜, 생물학, 과학 협업 등)에서 L을 적절히 조정하면 자기예측성이 0.7~0.9 수준으로 높게 나타났으며, 이는 기존 지표보다 네트워크 고유의 연결 가능성을 더 잘 반영한다는 것을 의미한다.
이 접근법은 (1) 연산 복잡도 감소, (2) 병렬 처리 친화성, (3) 네트워크 특성에 맞춘 평가 지표 제공이라는 세 축에서 기존 CN 기반 방법을 크게 개선한다. 특히, 대규모 이질 네트워크에서 “핫” 노드 간의 잠재적 연결을 빠르게 탐색하고, 실시간 혹은 근실시간 추천 시스템에 적용할 수 있는 실용성을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기