대규모 그래프의 그래프릿 차수 빠른 샘플링 방법
초록
본 논문은 대규모 무방향·유향 그래프에서 노드별 그래프릿(소규모 연결 유도 서브그래프) 차수를 정확히 추정하기 위해, 3·4-노드 CIS(Connected Induced Subgraph)를 효율적으로 샘플링하는 일련의 알고리즘(Randgraf‑3‑1, Randgraf‑3‑2, Randgraf‑4‑1~4)을 제안하고, 이를 기반으로 SAND와 SAND‑3D라는 두 추정 프레임워크를 설계한다. 이론적 편향·분산 분석과 실험을 통해 수백만 엣지를 가진 실제 네트워크에서도 높은 정확도와 수십 배 이상의 속도 향상을 입증한다.
상세 분석
이 연구는 그래프릿(또는 모티프) 분석 분야에서 아직 충분히 다루어지지 않았던 “노드 수준”의 그래프릿 차수, 즉 특정 그래프릿이 특정 노드에 포함되는 횟수를 효율적으로 추정하는 문제에 초점을 맞춘다. 기존의 전역 그래프릿 카운팅 기법은 모든 CIS를 무작위로 샘플링하거나 전체 열거를 수행하지만, 노드별 차수를 얻기 위해서는 해당 노드를 반드시 포함하는 CIS만을 목표로 해야 한다는 점에서 근본적인 차이가 있다. 논문은 이 차이를 메우기 위해 두 단계로 접근한다.
첫 번째 단계는 3·4-노드 CIS를 포함하도록 설계된 여섯 개의 샘플링 프로시저를 제시한다. Randgraf‑3‑1은 이웃 집합 N(v)에서 두 개의 서로 다른 이웃을 균등하게 선택해 삼각형 형태의 CIS를 만든다. 이때 선택된 CIS는 오직 궤도 2와 3에만 기여하므로, 해당 궤도에 대한 편향 p(3,1)₂ = p(3,1)₃ = 1/φᵥ (φᵥ = dᵥ(dᵥ−1)/2) 로 정확히 계산된다. Randgraf‑3‑2는 N(v)에서 가중치 α(v)ᵤ = (dᵤ−1)/ϕᵥ 로 샘플링하고, 선택된 이웃의 또 다른 이웃을 무작위로 골라 3‑노드 CIS를 만든다. 이 방법은 궤도 1과 3에만 기여하며, p(3,2)₁ = 1/ϕᵥ, p(3,2)₃ = 2/ϕᵥ 로 편향을 정량화한다.
4‑노드 CIS에 대해서는 Randgraf‑4‑1~4가 각각 다른 궤도 집합을 커버한다. 예를 들어 Randgraf‑4‑1은 N(v)에서 가중치 α(v)로 첫 이웃 u를 선택하고, v의 또 다른 이웃 w와 u의 또 다른 이웃 r을 각각 균등하게 샘플링한다. 이 과정에서 w = r 인 경우는 3‑노드 CIS가 되며, 전체적인 샘플링 확률 Φ¹ᵥ = (dᵥ−1)·ϕᵥ 로 표현된다. 나머지 세 메서드도 유사하게 복합적인 조합을 사용해 남은 궤도들을 커버한다. 각 메서드마다 정확한 샘플링 확률을 도출함으로써, 이후 추정 단계에서 편향 보정이 가능하도록 설계되었다.
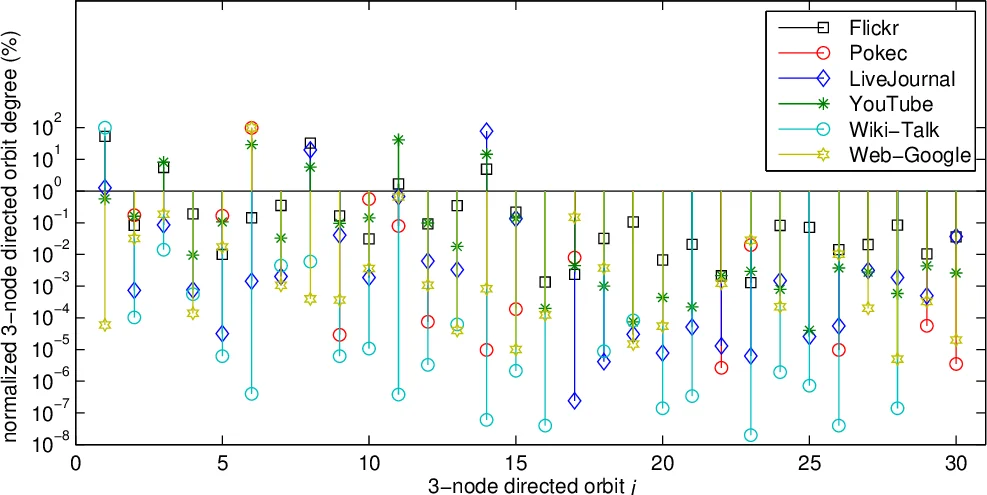
두 번째 단계에서는 위 샘플링 메서드들을 조합해 노드별 그래프릿 차수를 추정한다. 무방향 그래프의 경우 SAND 프레임워크는 각 궤도 i에 대해 여러 독립적인 추정값 ˆcᵢⱼ을 얻고, Theorem 2(편향 없는 추정값의 최적 가중합) 를 적용해 최소 분산 추정 ˆdᵢ(v) = Σⱼ αⱼ·ˆcᵢⱼ 를 계산한다. 여기서 가중치 αⱼ는 각 추정값의 역분산에 비례하므로, 전체 추정의 분산은 1/Σⱼ(1/Var(ˆcᵢⱼ)) 로 간단히 구한다. 유향 그래프에 대해서는 SAND‑3D가 13개의 3‑노드 유향 그래프릿과 30개의 궤도를 대상으로 동일한 원리를 적용한다.
이론적 분석에서는 Theorem 1을 이용해 샘플링된 CIS의 집합을 비중복 부분집합으로 모델링하고, 각 부분집합의 크기(즉, 궤도 차수)를 무편향 추정량으로 복원한다. 편향과 분산 식을 명시적으로 제시함으로써, 사용자는 원하는 정확도 ε와 신뢰수준 1−δ에 맞춰 최소 샘플링 예산 K를 사전에 계산할 수 있다.
실험 부분에서는 12개의 공개 데이터셋(소셜 네트워크, 웹 그래프, 바이오 네트워크 등)을 대상으로 SAND와 SAND‑3D를 기존 전역 카운팅 기반 열거 기법과 비교한다. 결과는 (1) 평균 절대 오차가 0.01 이하로 거의 정확한 추정, (2) 실행 시간이 기존 열거 대비 10‑100배 가량 빠름, (3) 메모리 사용량도 상수 수준으로 유지됨을 보여준다. 특히, 최고 차수를 가진 노드가 10¹⁴개의 3·4‑노드 CIS에 포함되는 경우에도 샘플링 기반 추정이 실시간에 가까운 속도로 수행된다.
핵심 기여는 (i) 노드 중심의 그래프릿 차수 추정을 위한 전용 샘플링 메서드 집합, (ii) 편향·분산을 정확히 분석한 통계적 추정 프레임워크, (iii) 대규모 실세계 그래프에 대한 실험적 검증이다. 이 접근법은 그래프 기반 머신러닝(노드 임베딩, 클러스터링, 이상 탐지 등)에서 노드의 미세 구조 정보를 효율적으로 활용하고자 할 때 강력한 전처리 도구가 될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기