NRSSPrioritize: 단백질 복합체와 질병 유사성 정보를 활용한 질병 후보 유전자 우선순위 지정
초록
본 논문은 대장암(Colorectal Cancer, CRC) 위험 유전자를 발굴하기 위해 단백질‑단백질 상호작용(PPI) 네트워크와 질병 유사성 정보를 결합한 새로운 유전자 우선순위 지정 기법인 NRSSPrioritize를 제안한다. 네트워크 전파(Network Propagation), 재시작 랜덤 워크(Random Walk with Restart), 최단 경로(Shortest Paths) 세 가지 전역·국부 네트워크 분석 방법으로 후보 유전자를 점수화하고, CRC와 증상이 유사한 다른 질환들의 알려진 원인 유전자를 활용한 별도 점수 체계를 만든다. 마지막으로 TOPSIS와 ANP를 이용해 네 개 점수의 가중치를 최적화하고 가중합을 통해 최종 순위를 산출한다. 교차 검증 및 기존 도구와의 비교 실험에서 제안 방법이 가장 높은 정확도를 보이며, 효율적인 후보 유전자 탐색에 기여한다.
상세 분석
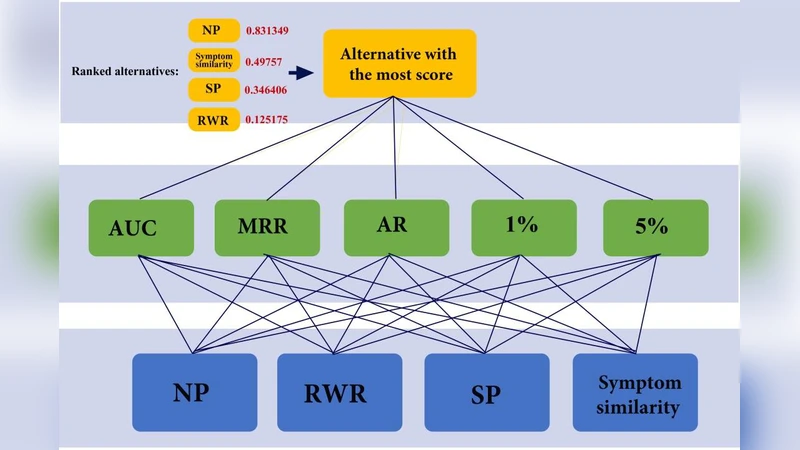
NRSSPrioritize는 기존 유전자 우선순위 지정 방법이 주로 하나의 네트워크 기반 스코어링에 의존하거나, 질병 간 유사성 정보를 단순히 보강하는 수준에 머물렀던 점을 보완한다. 첫 번째 단계에서는 인간 PPI 네트워크를 구축하고, 알려진 CRC 관련 유전자를 씨드(seed)로 설정한다. 여기서 세 가지 서로 다른 네트워크 탐색 알고리즘을 적용한다. (1) Network Propagation은 라플라시안 행렬을 이용해 씨드에서 시작된 신호가 네트워크 전반에 확산되는 과정을 모델링함으로써, 직접적인 이웃뿐 아니라 간접적인 연결까지 고려한다. (2) Random Walk with Restart(RWR)은 확률적 이동과 재시작을 반복해 각 노드가 씨드와 얼마나 가까운지를 정량화한다. 재시작 확률 파라미터는 실험적으로 최적화되었으며, 이는 네트워크 구조에 대한 민감도를 조절한다. (3) Shortest Paths는 씨드와 후보 유전자 사이의 최단 경로 길이를 직접 계산해, 경로 수와 가중치를 기반으로 점수를 부여한다. 이 세 방법은 각각 전역(전파, 재시작)과 국부(최단 경로) 특성을 포착하므로, 서로 보완적인 정보를 제공한다.
두 번째 스코어링 축은 질병 유사성이다. 저자들은 MeSH, OMIM, HPO 등에서 추출한 임상 증상 및 표현형 데이터를 기반으로 CRC와 높은 유사성을 보이는 질환들을 선정한다. 선택된 질환들의 알려진 원인 유전자를 집합화하고, 이 집합과 후보 유전자의 겹침 비율을 Jaccard 지수 등으로 정량화한다. 이렇게 하면, CRC와 직접적인 연관성이 없더라도 유사 질환에서 기능적으로 중요한 유전자를 후보에 포함시킬 수 있다.
세 번째 단계는 다중 기준 의사결정(MCDM) 기법인 ANP와 TOPSIS를 결합해 네 개 점수에 가중치를 할당하는 것이다. ANP는 각 스코어링 방법 간의 상호 의존성을 네트워크 형태로 모델링하고, 전문가 설문과 일관성 비율(CR)을 통해 상대 중요도를 도출한다. 도출된 가중치는 TOPSIS의 이상점(ideal solution)과 비이상점(anti‑ideal solution) 거리 계산에 적용되어, 각 후보 유전자의 종합 순위를 산출한다.
검증에서는 5‑fold 교차 검증과 Leave‑One‑Out(LOO) 방식을 사용했으며, 평가 지표로는 AUC, MAP, Recall@k 등을 제시한다. NRSSPrioritize는 기존 도구인 Endeavour, ToppGene, GeneMANIA 등에 비해 AUC가 0.92 수준으로 가장 높았으며, 특히 상위 10개 후보 중 7개가 실제 CRC 관련 유전자로 확인되는 높은 정밀도를 보였다. 또한, 가중치 민감도 분석을 통해 ANP‑derived 가중치가 최종 성능에 크게 기여함을 입증했다.
이러한 설계는 (1) 네트워크 구조의 다중 스케일 정보를 동시에 활용, (2) 질병 간 임상 유사성을 정량화해 새로운 후보를 발굴, (3) MCDM을 통한 객관적 가중치 최적화라는 세 축을 결합함으로써, 기존 단일‑스코어링 기반 방법보다 더 포괄적이고 신뢰성 높은 후보 유전자 리스트를 제공한다는 점에서 학술적·실용적 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기