인구 규모가 어휘 다양성을 예측하지만 평균 해수면 상승도 같은 결과를 보인다
초록
이 논문은 인구 규모와 국가별 주요 언어의 어휘 다양성 사이에 강한 상관관계가 존재한다는 겉보기 결과가 실제로는 시계열 데이터의 자기상관을 무시한 모델링 오류에서 비롯된다는 점을 보여준다. 동일한 분석을 전 세계 평균 해수면 상승과 어휘 다양성에 적용하면 전혀 의미 없는 관계가 나타나며, 이는 시계열 자료를 다룰 때 적절한 차분이나 트렌드 제거가 필요함을 강조한다. 저자는 이러한 오류가 최근 여러 문화·경제·인구 연구에서 반복되고 있음을 지적하고, 올바른 시계열 모델링과 결과 해석의 중요성을 역설한다.
상세 분석
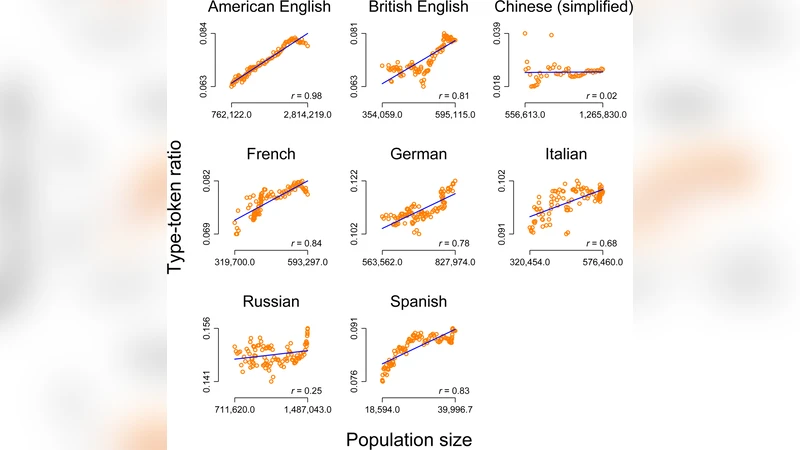
본 논문은 시계열 자료의 구조적 특성을 무시한 회귀 분석이 어떻게 허위 인과관계를 만들어 내는지를 실증적으로 입증한다. 먼저 저자는 7개 언어에 대해 각 국가의 인구 규모와 해당 언어의 어휘 다양성(타입‑토큰 비율) 데이터를 연도별로 수집하였다. 일반적인 OLS 회귀를 적용했을 때, 인구 규모가 증가할수록 어휘 다양성이 증가한다는 높은 결정계수와 통계적 유의성을 보였다. 그러나 이 모델은 시계열 데이터가 갖는 자기상관(autocorrelation)과 비정상성(non‑stationarity)을 전혀 고려하지 않았다. 시계열이 비정상적이면 두 변수 모두 시간에 따라 꾸준히 상승하거나 하강하는 추세를 가질 가능성이 높으며, 이러한 공통 추세가 회귀 분석에서 인위적인 상관관계를 만들어 낸다. 이를 검증하기 위해 저자는 동일한 방법론을 전 세계 평균 해수면 상승 데이터에 적용하였다. 해수면 상승은 언어와 전혀 관련이 없음에도 불구하고, 인구‑어휘 관계와 유사한 높은 상관계수가 도출되었다. 이는 두 시계열 모두 장기적인 상승 추세를 공유하기 때문이며, 실제 인과관계가 존재한다는 증거가 아니다.
다음 단계에서는 단위근 검정(Augmented Dickey‑Fuller test)과 차분(differencing) 등을 이용해 시계열을 정상화하였다. 차분 후에는 인구와 어휘 다양성 사이의 상관관계가 현저히 약화되었으며, 해수면 상승과의 관계는 통계적으로 의미 없게 되었다. 또한, 공적분 검정(Engle‑Granger) 결과도 두 변수 간 장기 균형 관계가 없음을 보여준다. 이러한 결과는 원시적인 OLS 회귀가 시계열 데이터에 적용될 경우, ‘스푸리어스 회귀(spurious regression)’ 현상이 발생한다는 고전적인 통계 이론과 일치한다.
논문은 또한 최근 문헌에서 보고된 인구‑문화, 경제‑언어 등 다양한 변수 간의 관계가 동일한 방법론적 함정을 공유하고 있음을 지적한다. 저자는 연구 설계 단계에서 시계열 특성을 확인하고, 필요시 차분, ARIMA, VAR 등 적절한 시계열 모델을 적용할 것을 권고한다. 마지막으로, 통계적 유의성뿐 아니라 결과의 실질적 타당성(plausibility)을 검토하는 것이 과학적 검증에 필수적임을 강조한다.